







【极简笔记】Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
文章核心:1. 提出DeepLabv3+,采用encoder-decoder结构(其实就是语义分割常用的下采样再上采样);2. 该网络通过带孔卷积可以任意控制encoder feature的resolution,有较好的尺度适应性;3. 采用modified Xception主干网络,并在ASPP(带孔卷积模块)和decoder模块采用depthwise separable convolution;
总之一句话,之前各种文章创新点的堆叠,加上大量的结构调参。
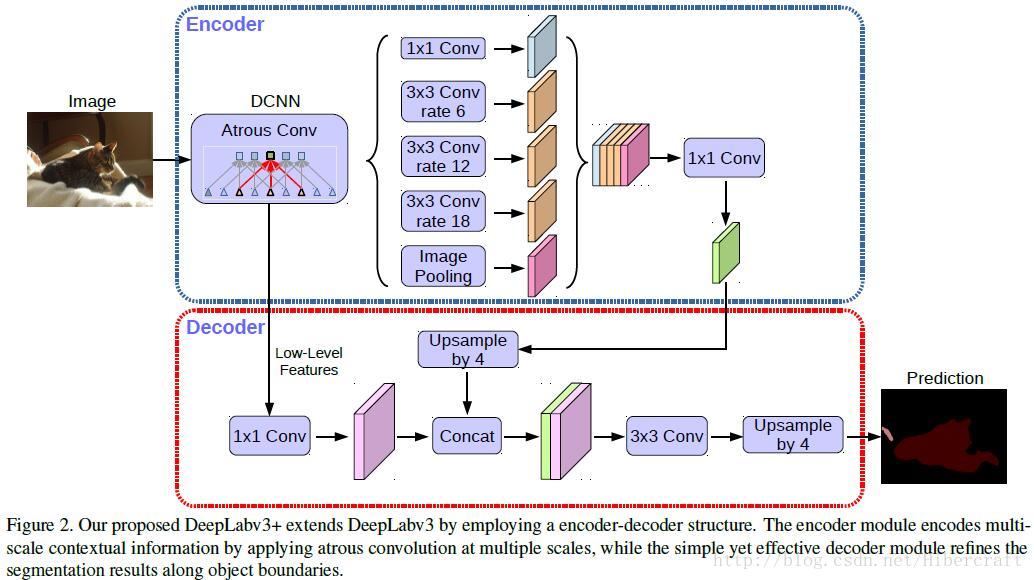
encoder-decoder和带孔卷积就不讲了,重点在它怎么合并 。如图在decoder部分,它是双线性上采样x4之后,和浅层通过1x1conv,拥有相同spatial resolution的feature map concatenate,之后再过一个3x3 conv,算是一次stage,这样多来几次回到原图大小。
在Xception的修改上,1. 更
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 489
489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









