






 本文探讨了大型语言模型在医疗领域的潜力与挑战,如GPT-3和Med-PaLM2在医疗问答中的表现,以及Med-LLM排行榜对模型性能的评估。文章强调了准确性和伦理问题,指出未来研究应关注模型训练、数据增强、多模态学习和伦理安全性。
本文探讨了大型语言模型在医疗领域的潜力与挑战,如GPT-3和Med-PaLM2在医疗问答中的表现,以及Med-LLM排行榜对模型性能的评估。文章强调了准确性和伦理问题,指出未来研究应关注模型训练、数据增强、多模态学习和伦理安全性。
多年來,大型語言模型(LLMs)已成為一項突破性技術,在醫療保健的各個方面都有巨大的潛力。這些模型,如GPT-3、GPT-4和Med-PaLM 2,在理解和生成類人文本方面表現出卓越的能力,使其成為應對復雜醫療任務和改善患者護理的寶貴工具。它們在各種醫療應用中都顯示出前景,例如醫療問答(QA)、對話系統和文本生成。此外,隨著電子健康記錄(EHRs)、醫學文獻和患者生成數據的指數級增長,LLMs可以幫助醫療專業人員提取有價值的見解並做出明智的決策。 然而,儘管大型語言模型(LLMs)在醫療保健中有巨大的潛力,但仍存在需要解決的重大和特定挑戰。 當模型被用於娛樂性對話時,錯誤很少會產生影響;然而,在醫療領域的應用中情況並非如此,錯誤的解釋和答案可能對患者護理和結果產生嚴重後果。語言模型提供的信息的準確性和可靠性可能是生死攸關的問題,因為它可能會影響醫療保健決策、診斷和治療計劃。 例如,當給出一個醫療查詢時(見下文),GPT-3錯誤地建議孕婦使用四環素,儘管它正確解釋了由於可能對胎兒造成傷害而禁忌使用四環素。按照這一錯誤建議行事可能導致嬰兒骨骼生長問題。
医疗大型语言模型公开排行榜旨在追踪、排名和评估大型语言模型(LLMs)在医疗问答任务上的表现。它评估LLMs在各种医疗数据集上的表现,包括MedQA(USMLE)、PubMedQA、MedMCQA,以及与医学和生物学相关的MMLU子集。该排行榜全面评估了每个模型的医学知识和问答能力。
这些数据集涵盖了医学的各个方面,如一般医学知识、临床知识、解剖学、遗传学等。它们包含需要医学推理和理解的选择题和开放式问题。有关数据集的更多详细信息,请参见下面的"LLM基准测试细节"部分。
主要评估指标为准确率(ACC)。
医疗大型语言模型公开排行榜的后端使用Eleuther AI语言模型评估工具。为LLMs提供60多个标准学术基准,实现了数百个子任务和变体:
- 支持通过transformers加载模型(包括通过AutoGPTQ进行量化)、GPT-NeoX和Megatron-DeepSpeed,具有灵活的tokenizers无关接口。
- 支持使用vLLM进行快速和内存高效的推理。
- 支持商业API,包括OpenAI和TextSynth。
- 支持在HuggingFace的PEFT库中支持的适配器(例如LoRA)上进行评估。
- 支持本地模型和基准。
- 使用公开可用的提示进行评估,确保论文之间的可重复性和可比性。
- 易于支持自定义提示和评估指标。
- 基于配置的任务创建和配置更容易从外部定义的任务配置YAML中导入和共享
- 支持Jinja2提示设计,易于修改提示+从Promptsource导入提示
- 更高级的配置选项,包括输出后处理、答案提取和每个文档多个LM生成、可配置的少样本设置等
- 支持加速和新的建模库,包括:更快的数据并行HF模型使用、vLLM支持、使用HuggingFace的MPS支持等
- 日志记录和可用性变更
- 新任务,包括CoT BIG-Bench-Hard、Belebele、用户定义的任务分组等
语言模型评估工具是Hugging Face广受欢迎的Open LLM排行榜的后端,已在数百篇论文中使用,并被包括NVIDIA、Cohere、BigScience、BigCode、Nous Research和Mosaic ML在内的数十家组织内部使用。
GPT-4和Med-PaLM-2的结果取自其官方论文。由于Med-PaLM没有提供零样本准确性,我们使用其论文中的5样本准确性进行比较。除了Med-PaLM-2使用5样本准确性外,所有呈现的结果都是在零样本设置下获得的。Gemini的结果取自最近的Clinical-NLP(NAACL 24)论文。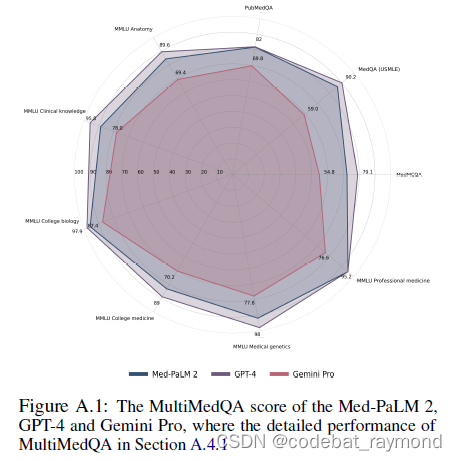
该论文采用三个基准测试来评估Gemini在医疗领域的表现:
1. **MultiMedQA**:涵盖多个医疗QA数据集,包含需要复杂推理的多面向问题,用于评估模型在不同医学专科的临床推理能力。
2. **Med-HALT**:专门测试医疗语言模型的幻觉(hallucination)倾向,分为推理型幻觉测试(RHT)和记忆型幻觉测试(MHT)。前者评估模型在面对挑战性诊断场景时的逻辑分析与不确定性处理能力,后者考察模型对医学文献的精确记忆与检索能力。
3. **医疗视觉问答(VQA)**:评估模型在整合视觉与文本理解方面的能力,要求模型根据医学图像回答复杂的多选题。
此外,研究还采用了多种先进的prompt工程技术,如直接少样本(few-shot)、思维链(CoT)、自我一致性(SC)和整体优化(ER)等,以提升模型在医疗任务上的表现。
在MultiMedQA基准测试中,Gemini展现出对各种医学主题的广泛理解,但在诊断准确性方面仍不及Med-PaLM2和GPT-4等顶尖模型。Gemini在MedQA、MedMCQA和PubMedQA等数据集上的得分分别为67%、62.2%和70.7%,落后于Med-PaLM2的86.5%、72.3%和81.8%。
Med-HALT基准测试揭示了Gemini在面对具有挑战性的诊断场景时,容易产生过度自信的幻觉(RHT中的FCT测试只有36.21%的准确率)。此外,在检索和匹配详细的生物医学信息方面,Gemini也表现出显著的困难(MHT中多个任务的准确率低于40%)。这凸显了Gemini在可靠性和可信度方面存在不足。
在VQA任务中,Gemini取得了61.45%的准确率,远低于GPT-4V的88%,反映出其在整合视觉和文本理解以进行医学图像分析方面的局限性。Gemini难以突出异常、缺乏诊断词汇,并在临床知识方面存在不足。
通过对Gemini在不同医学专科的表现进行细粒度分析,我们发现它在生物统计学、细胞生物学和流行病学等数据密集型和程序化的领域表现出色(达到100%的准确率),但在需要复杂推理或专业知识的领域如心脏病学(26.67%)和皮肤科(58.82%)则表现不佳。
医疗大型语言模型(Medical-LLM)排行榜旨在解决这些挑战和限制,提供一个标准化的平台来评估和比较各种大型语言模型在不同医疗任务和数据集上的表现。通过对每个模型的医学知识和问答能力进行全面评估,该排行榜旨在促进更有效、更可靠的医疗LLMs的发展。
这个平台使研究人员和从业者能够
识别不同方法的优缺点,推动该领域的进一步发展,最终为更好的患者护理和治疗结果做出贡献。
**数据集、任务和评估设置**
Medical-LLM排行榜包括各种任务,并使用准确度作为主要评估指标(准确度衡量语言模型在各种医疗QA数据集上提供正确答案的百分比)。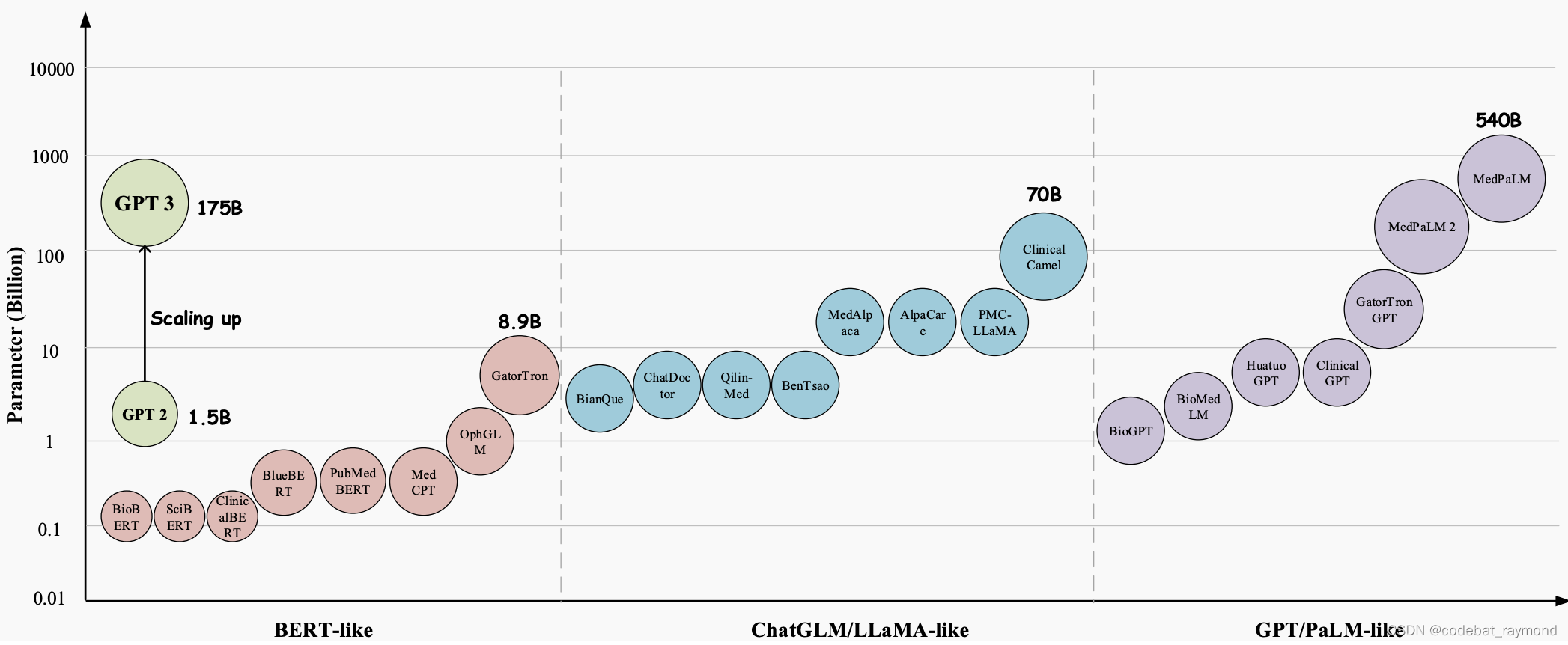
### MedQA
MedQA数据集由美国医师执照考试(USMLE)的选择题组成。它涵盖了一般医学知识,包括开发集中的11,450个问题和测试集中的1,273个问题。每个问题有4或5个答案选项,该数据集旨在评估在美国获得医师执照所需的医学知识和推理技能。
### MedMCQA
MedMCQA是一个大规模的多项选择题QA数据集,源自印度医学入学考试(AIIMS/NEET)。它涵盖了2.4k个医疗主题和21个医学科目,开发集中有超过18.7万个问题,测试集中有6,100个问题。每个问题有4个答案选项,并附有解释。MedMCQA评估模型的一般医学知识和推理能力。
### PubMedQA
PubMedQA是一个封闭领域的QA数据集,其中每个问题都可以通过查看相关的上下文(PubMed摘要)来回答。它由1,000对专家标注的问答对组成。每个问题都附有一个PubMed摘要作为上下文,任务是根据摘要中的信息提供是/否/可能的答案。数据集分为500个开发问题和500个测试问题。PubMedQA评估模型理解和推理科学生物医学文献的能力。
### MMLU子集(医学和生物学)
MMLU基准(测量大规模多任务语言理解)包括来自各个领域的多项选择题。对于Medical-LLM排行榜,我们专注于与医学知识最相关的子集:
- 临床知识:265个问题,评估临床知识和决策技能。
- 医学遗传学:100个问题,涵盖与医学遗传学相关的主题。
- 解剖学:135个问题,评估人体解剖学知识。
- 专业医学:272个问题,评估医疗专业人员所需的知识。
- 大学生物学:144个问题,涵盖大学水平的生物学概念。
- 大学医学:173个问题,评估大学水平的医学知识。
每个MMLU子集都由4个答案选项的多项选择题组成,旨在评估模型对特定医学和生物学领域的理解。
**Medical-LLM排行榜全面评估了模型在医学知识和推理的各个方面的表现**,为进一步提高医疗大型语言模型的质量和可靠性提供了坚实的基础。
通过这些详细的评估和排行,研究人员和从业者可以更全面地理解不同模型在处理复杂医疗问题时的能力和局限,从而指导未来的研究方向和技术发展。
**洞见和分析**
通过Medical-LLM排行榜的评估,我们能够获取多个重要的洞见,这些洞见有助于推动大型语言模型在医疗领域的应用和发展: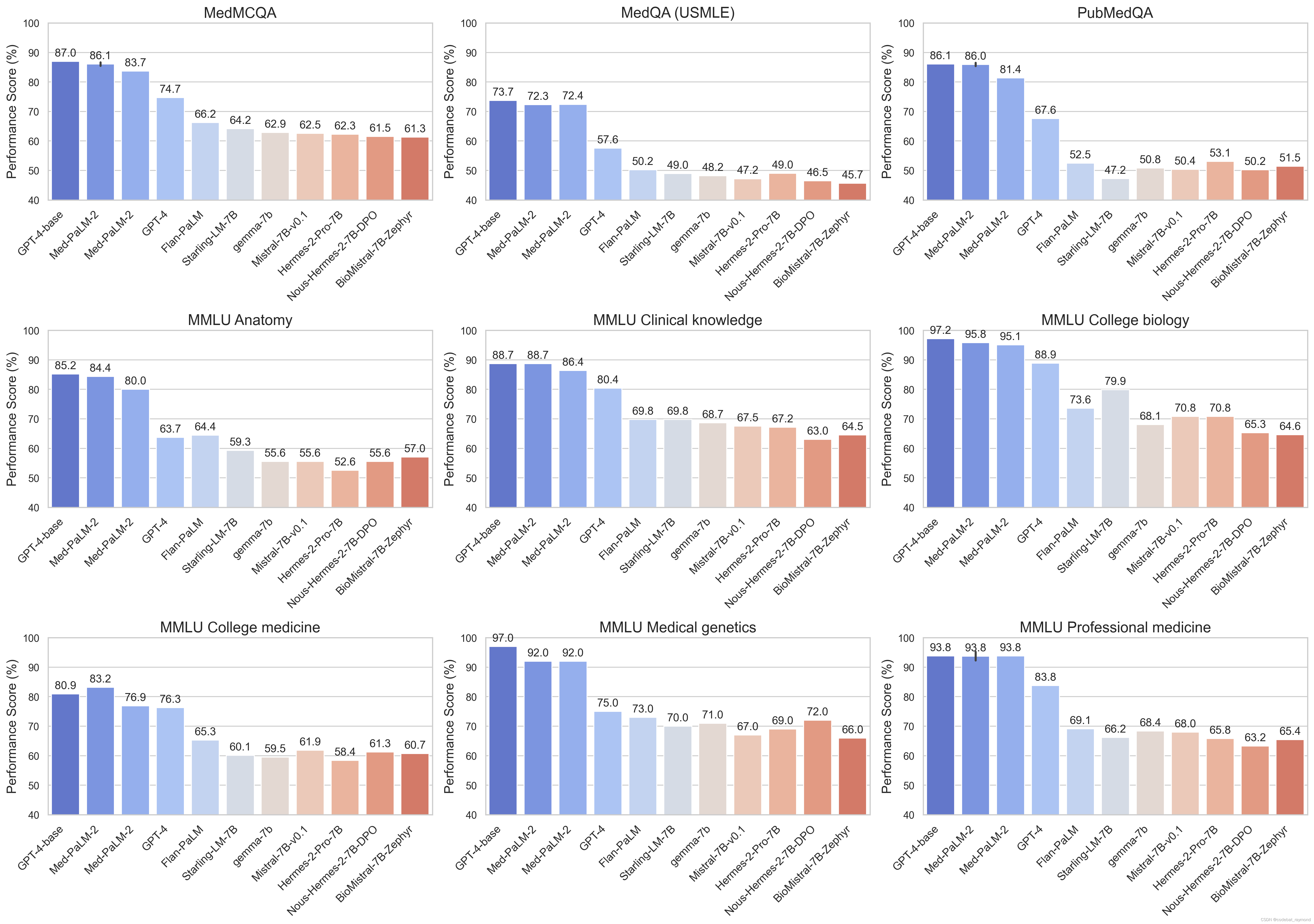
1. **模型性能的多样性**:不同的大型语言模型在各种医疗问答任务中表现出显著的性能差异。一些模型在特定类型的任务(如基于事实的简单查询)中表现出色,而在需要高级推理或专业知识的任务中则表现不佳。
2. **专业医学知识的重要性**:在高级医学领域的任务,如解剖学或心脏病学问题上,即使是最先进的模型也可能挣扎,显示出在这些领域需要更精细的训练和优化。
3. **培训数据的影响**:模型的训练数据对其在特定医学问答任务上的表现至关重要。数据集的质量、多样性和覆盖范围直接影响模型的有效性和适应性。
4. **幻觉的挑战**:在Med-HALT测试中,一些模型表现出对某些情景产生不切实际或不准确回答的倾向,称为"幻觉",这在医疗应用中尤其危险,因为它可能导致错误的医疗决策。
5. **整合多模态数据的潜力**:在医疗视觉问答(VQA)任务中,模型必须处理图像和文本信息,展示了整合多模态数据的重要性和潜力。这表明在未来的医疗模型开发中,融合视觉数据和文本数据的能力将是一个重要的发展方向。
**未来的研究方向**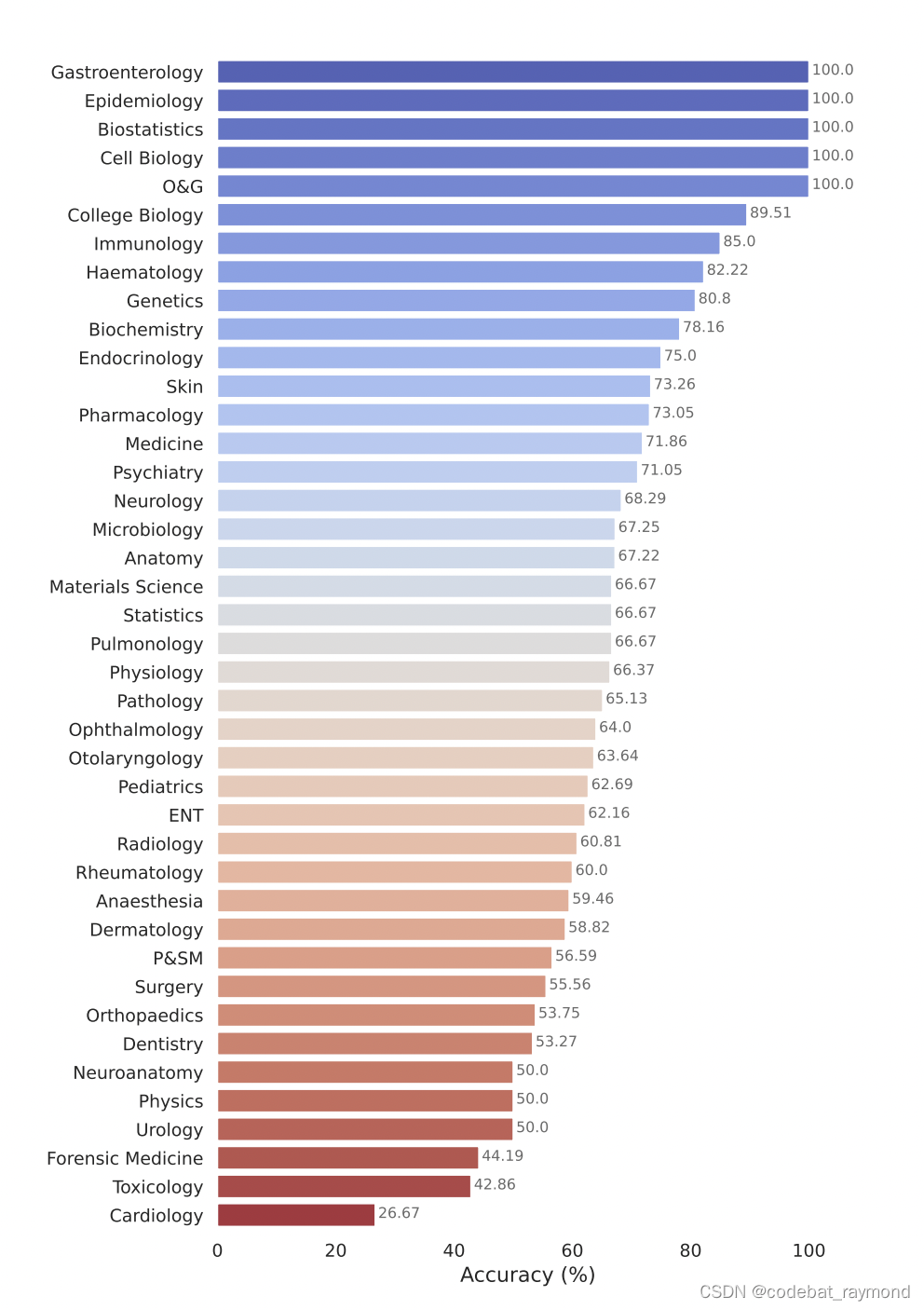
基于Medical-LLM排行榜的结果,以下是一些未来研究和开发的重要方向:
- **改进模型训练**:开发更高级的训练方法,特别是针对需要复杂推理和深度医学知识的任务,以提高模型在这些领域的表现。
- **增强数据集**:构建和利用更高质量和更多样化的医学数据集来训练模型,尤其是那些包含罕见病症或特定医学领域的数据集。
- **多模态学习**:进一步探索和开发能够处理和整合来自不同来源(如文本、图像和可能的实时数据)的信息的模型。
- **可解释性和透明度**:提高模型的可解释性,使医疗从业者能够理解模型的推理过程和决策依据,增加对模型的信任并促进其在实际医疗环境中的应用。
- **伦理和安全性**:加强对模型在医疗环境中应用的伦理和安全性研究,确保它们的使用不会对患者造成伤害,同时遵守相关的医疗法规和隐私
法。
通过这些研究方向的深入探索,我们可以期待未来大型语言模型在医疗领域的更广泛和更有效的应用。医疗大型语言模型不仅能提供高效的诊断支持,还可以在患者管理和治疗规划中扮演关键角色,极大地提升医疗服务的质量和效率。
**技术和工具的发展**
随着技术的进步,特别是在自然语言处理和机器学习领域,新的工具和技术也在不断地被开发和优化。这些技术可以帮助更准确地解析和处理医疗文献、临床记录以及患者提供的信息,进而提高模型的性能和适应性。
例如,深度学习算法的改进、语言模型的预训练技术、以及自适应学习方法等,都可能成为推动医疗语言模型发展的关键因素。此外,高效的计算资源管理和模型微调技术也将对实现更广泛的临床应用至关重要。
**合作与跨学科研究**
医疗大型语言模型的发展不仅是计算机科学的任务,也需要医学、生物学、伦理学和法律等领域的知识和专长。因此,加强跨学科合作,汇聚不同领域的专家来共同研究和解决问题,将是实现有效和安全应用的关键。
此外,与临床医生和医疗机构的紧密合作可以确保开发出的解决方案能够真正满足临床需求,并在实际的医疗环境中得到有效验证和改进。
**政策和规范的制定**
随着医疗大型语言模型在实际医疗活动中的应用越来越广泛,相应的政策和规范也需要更新以适应这些技术的发展。这包括确保模型的使用符合医疗伦理标准,保护患者隐私,以及防止潜在的偏见和不公正行为。
制定明确的指导方针和标准,不仅可以帮助模型开发者和用户了解如何安全有效地使用这些技术,也可以帮助监管机构确保这些技术的应用不会对患者或公众造成伤害。
**结论**
通过持续的研究、技术创新、跨学科合作以及严格的伦理和法规遵守,医疗大型语言模型有望在未来为医疗领域带来革命性的变革。它们不仅能够提高医疗服务的质量和效率,还可以在全球范围内提供更公平、更普惠的医疗服务,从而改善亿万患者的健康与福祉。

















 170
170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









