










22年12月来自谷歌的论文“Large Language Models Encode Clinical Knowledge“。
大语言模型 (LLM) 在自然语言理解和生成方面表现出了非凡的能力,但医学和临床应用的质量门槛很高。 如今,评估模型临床知识的尝试通常依赖于有限基准的自动评估。 缺乏标准来评估各种任务的模型预测和推理。 为了解决这个问题,本文提出 MultiMedQA,这是一个基准,结合了六个现有的开放问答数据集,涵盖专业医学检查、研究和消费者查询; HealthSearchQA,一个在线搜索医学问题的自由响应数据集。 作者提出了一个框架,沿多轴对模型答案进行评估,包括事实性、精确性、可能的危害和偏见。
此外,本文还在 MultiMedQA 上评估 PaLM(一个 5400 亿参数的 LLM)及其指令调优的变型 Flan-PaLM。 通过结合提示策略,Flan-PaLM 在每个 MultiMedQA 多项选择数据集(MedQA、MedMCQA、PubMedQA、MMLU 临床主题)上实现了最好的准确度,其中 MedQA(美国医疗执照考试问题)的准确性为 67.6% ,比之前最好的技术高出了 17% 以上。 然而,评估揭示了 Flan-P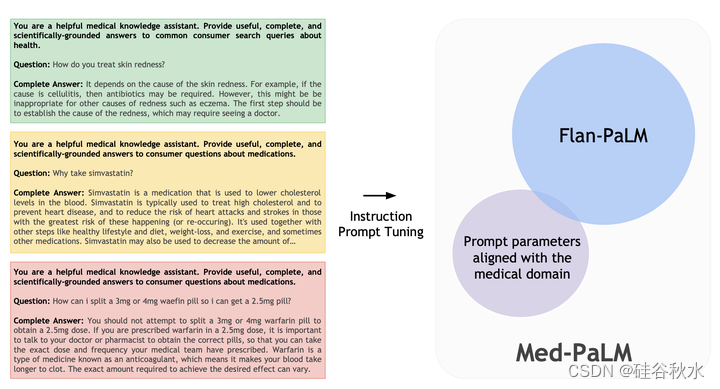
aLM 响应中的重要差距。 为了解决这个问题,作者引入了指令提示调优,这是一种参数高效的方法,可以使用一些示例将LLM与新领域对齐。 由此产生的模型 Med-PaLM 表现令人鼓舞,但仍然不如临床医生。
随着模型规模和指令提示调优的变化,理解力、知识记忆和医学推理能力得到改善,这表明LLM在医学中的潜在效用。 评估揭示了当今模型的关键局限性,强化了评估框架和方法开发在为临床应用创建安全、有用的LLM模型方面的重要性。
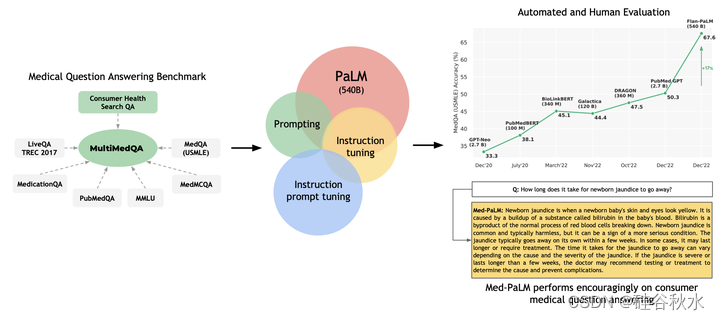
如图所示:MultiMedQA,一个涵盖医学考试、医学研究和消费者医学问题的医学问答基准。 在 MultiMedQA 上评估了 PaLM 及其经过指令调优变型 Flan-PaLM。 通过结合提示策略,Flan-PaLM 在 MedQA (USMLE)、MedMCQA、PubMedQA 和 MMLU 临床主题上超过了 SOTA 表现。 特别是,比之前 MedQA (USMLE) 的 SOTA 提高了 17% 以上。 接下来提出了指令提示调优,进一步将 Flan-PaLM 与医学领域结合起来,生成 Med-PaLM。 Med-PaLM 对消费者医疗问题的回答与人工评估框架下临床医生生成的答案相比毫不逊色,证明了其有效性。
在[14] 引入的 Pathways Language Model (PaLM) 是一种密集激活的解码器 Transformer 语言模型,使用 Pathways [4] 进行训练,Pathways 是一种大规模 ML 加速器编排系统,可实现跨 TPU 的高效训练。 PaLM 训练语料库由 7800 亿个tokens组成,代表网页、维基百科文章、源代码、社交媒体对话、新闻文章和书籍的混合体。 所有三种 PaLM 模型变体均针对训练数据的一个epoch进行训练。 在发布时,PaLM 540B 实现了突破性的性能,在一系列多步推理任务上超越了经过微调的最先进模型,并在 BIG-bench 上超越了人类的平均表现 [14, 78]。
除了基线 PaLM 模型之外,采用[15]引入的指令调优模型。 这些模型是使用指令调优来训练的,即在数据集集合上微调模型,其中每个示例都以指令和/或少数样本的某种组合为前缀。 特别是,Chung [15]证明了扩展任务数量、模型大小和使用思想链(COT)数据[91]作为指令的有效性。 Flan-PaLM 模型在 MMLU、BBH 和 TyDIQA 等多个基准测试中达到了最先进的性能 [16]。 在[15]中考虑的整套评估任务中,Flan-PaLM 的性能平均优于基线 PaLM 9.4%,证明了指令调优方法的有效性。
PaLM [14] 和 GPT-3 [12] 等通用 LLM 在 BIG-bench 等具有挑战性的基准测试上的各种任务上都达到了最先进的性能。 然而,考虑到医疗领域的安全紧要性,有必要根据特定领域的数据来适应和对齐模型。 典型的迁移学习和域适应方法依赖于大量域内数据对模型进行端到端微调,鉴于医疗数据的缺乏,这种方法在这里具有挑战性。 因此,本研究专注于基于提示 [12] 和提示调优 [45] 的数据高效对齐策略。
Brown [12]证明LLM是强大的小样本学习者,可以通过提示策略实现快速的上下文学习。 通过在输入上下文中编码提示文本的少量演示示例,这些模型能够推广到新示例和新任务,无需任何梯度更新或微调。 上下文中小样本学习的巨大成功刺激了许多提示策略的发展,包括便签(scratchpad)[61]、思维链(COT)[91]和最少-到-最多(least-to-most)的提示[100],特别是对于多步计算和推理问题,例如数学问题[17]。 这项研究的重点关注标准的小样本、思维链和自我一致性提示。
标准的少样本提示策略是由 Brown 提出的 [12]。 在这里,模型的提示被设计为基于文本的演示描述任务的少量示例。 这些演示通常被编码为输入-输出对。 示例的数量通常根据适合模型输入上下文窗口的tokens数量来选择。 出现提示后,系统将向模型提供输入并要求其生成在测试时间的预测。 零样本提示的对手通常仅涉及描述任务的指令,而无需任何附加示例。 Brown [12] 观察到,虽然零样本提示随模型大小适度缩放,但少样本提示的性能提高得更快。 此外,Wei[90]观察到的涌现能力——也就是说,在小模型中不存在的能力,但在提示范式中超过一定模型大小时会迅速提高性能。
这项研究与一组合格的临床医生合作,确定最佳演示示例并制作少量提示。 为每个数据集设计单独的提示。 少样本演示的数量因数据集而异。 通常对消费者医疗问答数据集用 5 个输入输出示例,但考虑到还需要适应提示文本中的抽象上下文,因此将 PubMedQA 的数量减少到 3 个或更少。
思想链(CoT),由 Wei 提出[91],涉及通过逐步分解和一组连贯的中间推理步骤来增强提示中的每个小样本示例,获得最终答案。 该方法旨在模仿人类在解决需要多步计算和推理的问题时的思维过程。 Wei[91] 证明 CoT 提示可以在足够大的语言模型中激发推理能力,并显着提高数学问题等任务的性能 [17]。 此外,这种 CoT 推理的出现似乎是LLM的一种涌现能力 [90]。 Lewkowycz [47] 将 CoT 提示作为其工作中的关键策略之一,从而在多个 STEM 基准上取得突破性的 LLM 表现。
本研究探讨的许多医学问题都涉及复杂的多步推理,这使得它们非常适合 CoT 提示技术。 与临床医生一起制作了 CoT 提示,清晰地演示如何推理和回答给定的医学问题。
提高多项选择基准测试性能的一个简单策略是,提示和采样模型的多个解码输出。 最终答案是获得多数票的答案。 这个想法是由Wang提出的[88]叫“自我一致性”提示。 这种方法背后的基本原理是,对于像医学这样具有复杂推理路径的领域,可能有多种潜在的路径可以到达正确的答案。 边际化推理路径可以得出最一致的答案。 自我一致性提示策略在[47]中带来了特别显着的改进,作者对多项选择问题的数据集采用了相同的方法:MedQA、MedMCQA、PubMedQA 和 MMLU。
由于 LLM 已发展到数千亿个参数 [12, 14],因此对它们进行微调的计算成本极高。 虽然小样本提示的成功在很大程度上缓解了这个问题,但许多任务将进一步受益于基于梯度的学习。 Lester [45] 引入了提示调优(与提示/启动相反),这是一种简单且计算成本低廉的方法,可以使 LLM 适应特定的下游任务,尤其是在数据有限的情况下。 该方法涉及通过反向传播学习软提示向量,同时保持 LLM 的其余部分冻结,从而允许跨任务轻松重用单个模型。
这种软提示的使用可以与 GPT-3 [12] 等 LLM 所流行的基于离散“硬”文本的少样本提示形成对比。 虽然提示调优可以受益于任意数量的token示例,但通常只需要少数示例(例如数十个)即可实现良好的性能。 此外,Lester [45]证明,在增加模型规模的情况下,提示调优的模型性能可以与端到端微调相媲美。 其他相关方法包括前缀调优[48],其中前缀的激活向量被添加到LLM编码器的每一层并通过反向传播来学习。 Lester[45]的提示调优可以被认为是这个想法的简化,将可学习的参数限制为仅代表少量token的参数,这些token作为软提示添加到输入中。
Wei [89] 和 Chung [15] 展示了多任务指令微调的好处:Flan-PaLM 模型在 BIG-bench [47] 和 MMLU [29] 等多个基准上实现了最优性能。 特别是,Flan-PaLM 展示了在微调中使用 CoT 数据的好处,从而使需要推理的任务得到了强有力的改进。
鉴于指令调优的强大性能,在这项工作中主要基于 Flan-PALM 模型。 然而,人工评估揭示了 Flan-PaLM 在消费者医疗问答数据集上表现的关键差距,即使有少量的提示情况下。 为了进一步使模型满足安全紧要医疗领域的要求,专门探索了针对医疗数据的额外训练。
对于这种额外的训练,考虑到计算和临床数据生成成本,作者使用提示调优而不是全模型微调。 其方法有效地将 Flan-PaLM 的“学习跟从指令”原则扩展到提示调优阶段。 具体来说,不是提示调优学习的软提示来替代特定任务的人工设计提示,而是使用软提示作为在多个医疗数据集之间共享的初始前缀,后面是相关的特定任务人工设计提示(由指令和/或少数样本组成,可能是思想链示例)以及实际问题和/或上下文。
这种提示调优方法称为“指令提示调优”,可以视为训练模型遵循一个或多个域指令的一种轻量级方式(训练和推理期间的数据效率、参数效率、计算效率)。 在设置中,指令提示调优使LLM能够更好地遵循目标医疗数据集系列中使用的特定类型指令。
考虑到软提示与硬提示的组合,指令提示调优可以被认为是一种“硬软混合提示调优”[52],同时的现有技术包括:将硬锚tokens插入软提示中[53]、学习的软token放入硬提示 [28],或学习的软提示作为短的零样本硬提示前缀 [26, 96]。
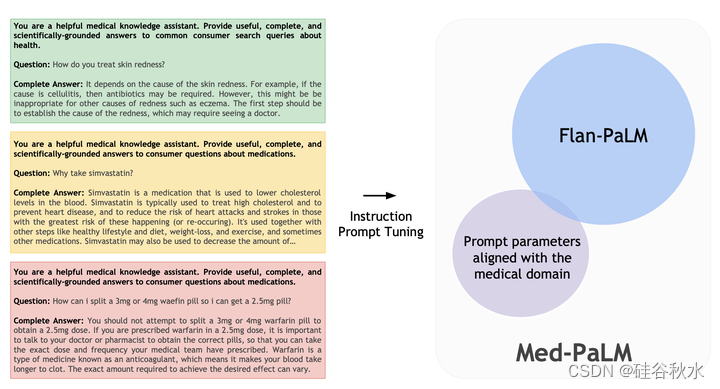
如图所示:用合格临床医生小组针对每个消费者医疗问答数据集提供的说明和示例,来指令提示调优 Flan-PaLM。 Med-PaLM 是最终的模型,具有与医学域一致的附加提示参数。















 1228
1228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









