









Actor-critic algorithm
本笔记整理自 (作者: Shusen Wang):
https://www.bilibili.com/video/BV1rv41167yx?from=search&seid=18272266068137655483&spm_id_from=333.337.0.0
Actor-critic algorithm
Value network and policy network
注意这里的符号
- π ( a ∣ s ) \pi(a|s) π(a∣s): 指的是policy分布,是精确的分布,只是我们不知道具体形式
- π ( a ∣ s , θ ) \pi(a|s, \theta) π(a∣s,θ): 指的是用一个神经网络去近似 π ( a ∣ s ) \pi(a|s) π(a∣s),其中 θ \theta θ是神经网络的参数。
- Q π ( s , a ) Q_{\pi}(s, a) Qπ(s,a): 是指策略函数为 π \pi π,状态为 s s s, 动作为 a a a的时候的动作价值函数。
- q ( s , a ; w ) q(s, a; \mathbf{w}) q(s,a;w): 指用一个神经网络 q ( s , a ; w ) q(s, a; \mathbf{w}) q(s,a;w)去近似动作价值函数 Q π ( s , a ) Q_{\pi}(s, a) Qπ(s,a)。其中 w \mathbf{w} w是神经网络的参数。

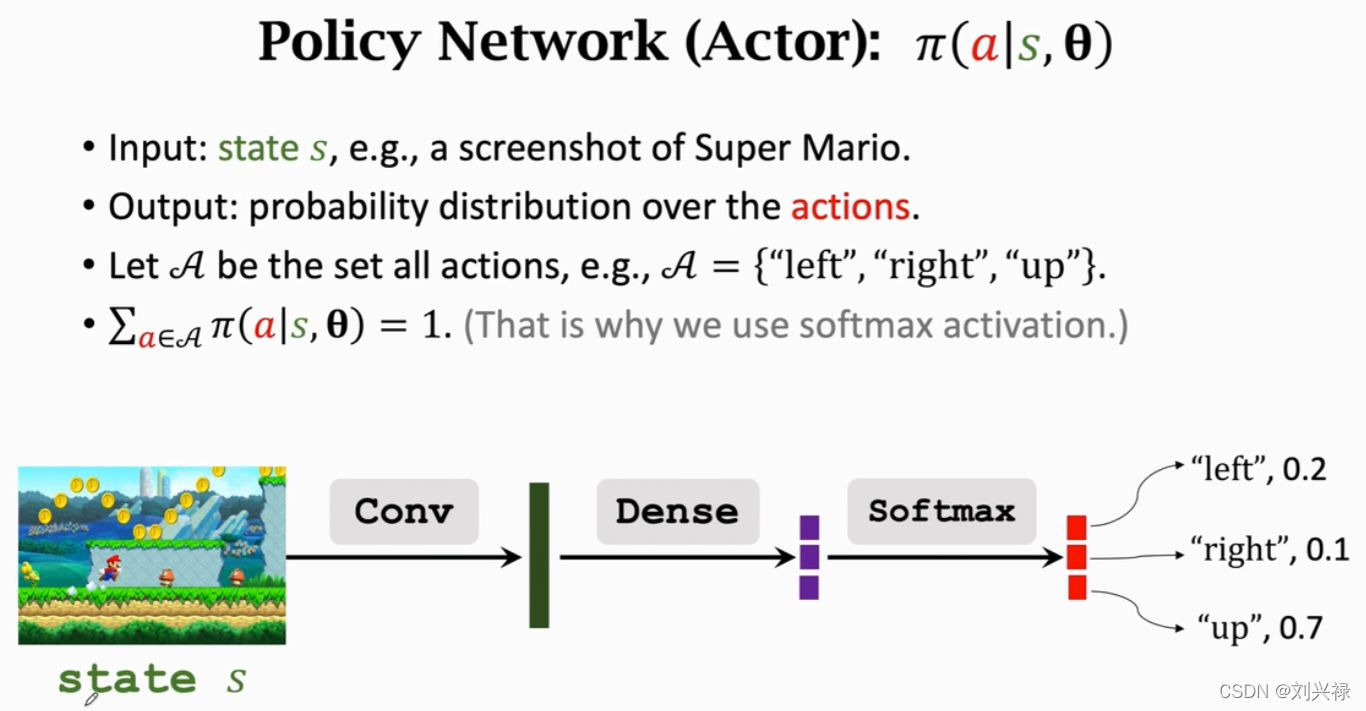
输入:可以是一帧或者好几帧frame

- 注意,value network q ( s , a ; w ) q(s, a; \mathbf{w}) q(s,a;w)可以和策略网络 policy network π ( s , a ; θ ) \pi(s, a; \theta) π(s,a;θ)共享相同的卷积层 conv, 但是也可以是完全独立的,各自有各自的参数。
- 同时训练 value network q ( s , a ; w ) q(s, a; \mathbf{w}) q(s,a;w)和策略网络 policy network π ( s , a ; θ ) \pi(s, a; \theta) π(s,a;θ)就叫做Actor critic algorithm.
- 训练的目的,是让运动员的平均分越来越高,并且让裁判的评分越来越精准

训练神经网络





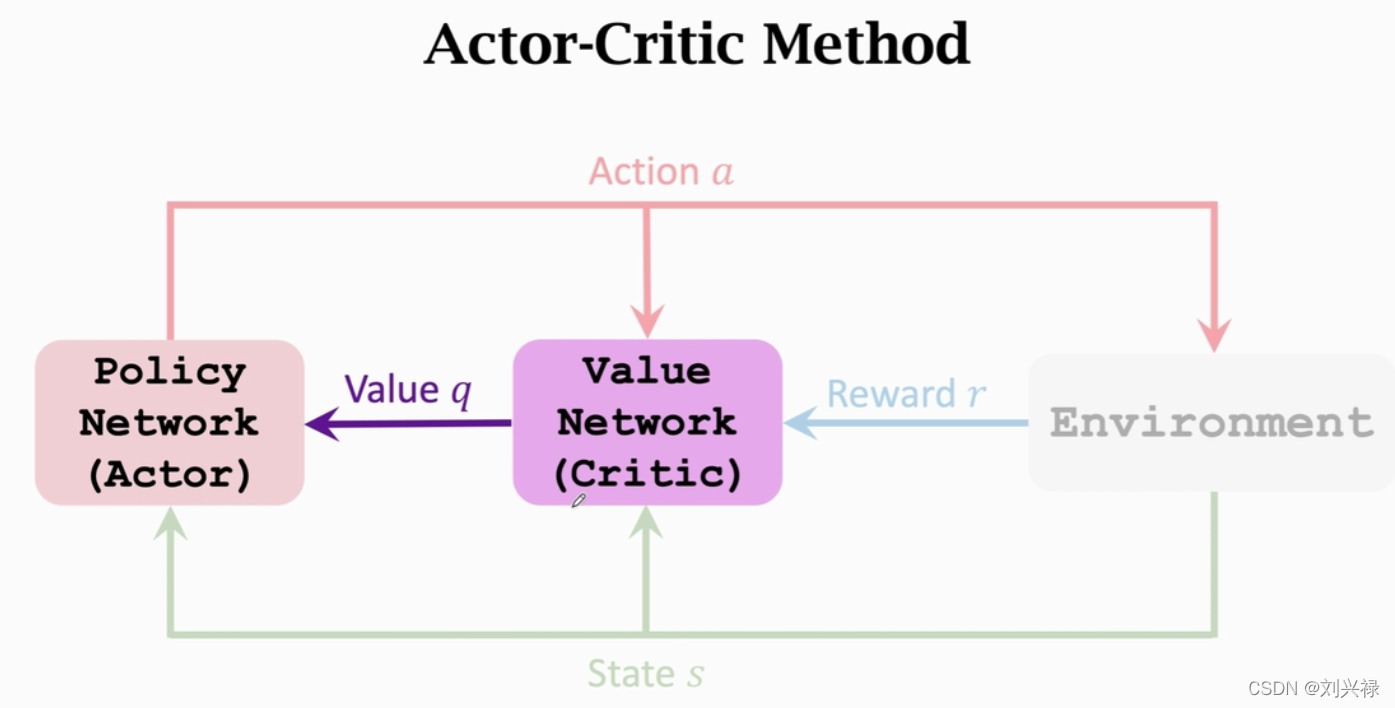
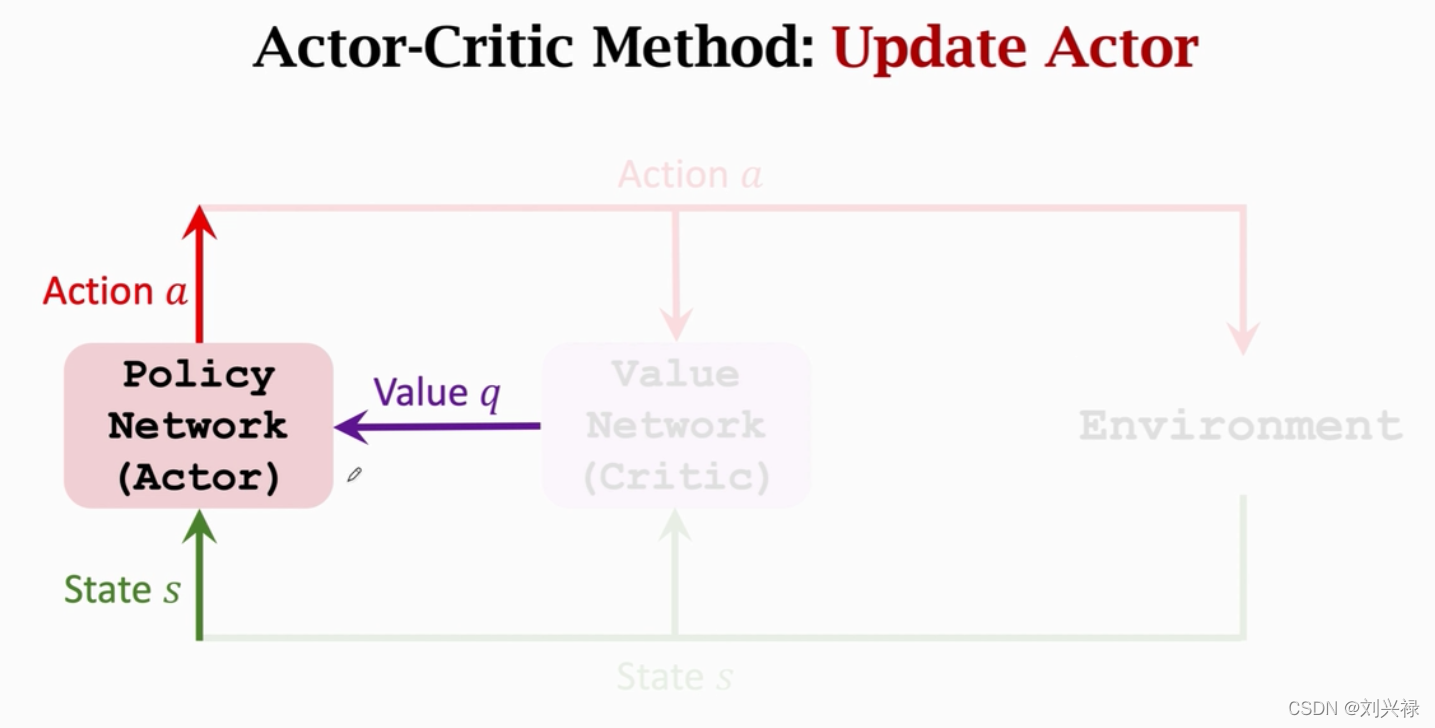
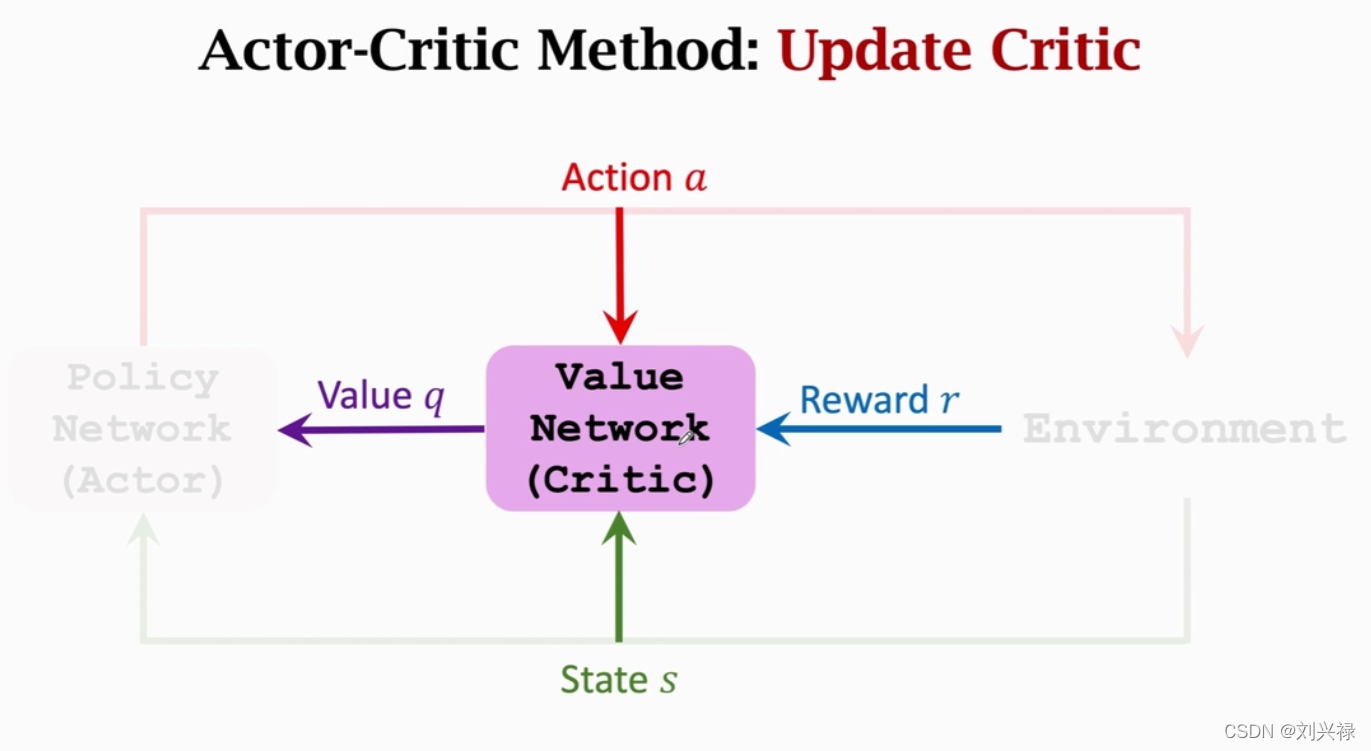






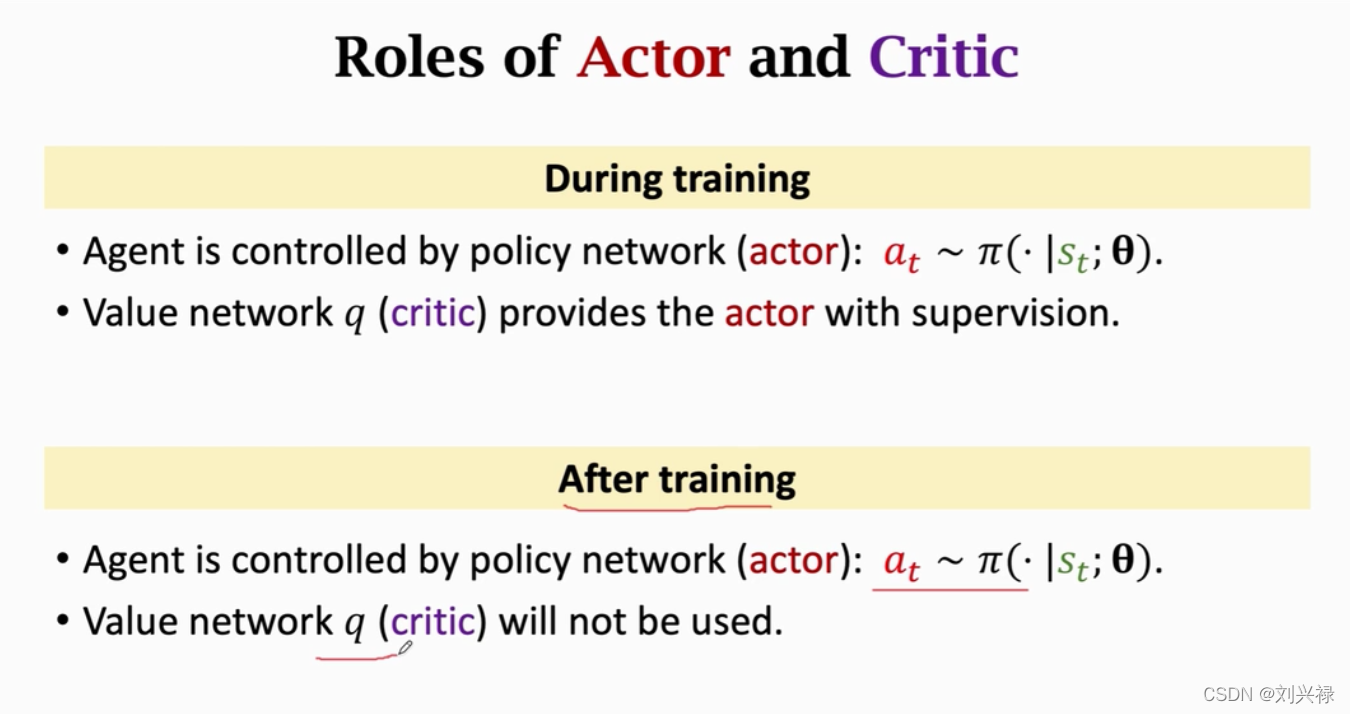
- 注意:value network只是起辅助作用,训练完成之后就不再被用了。最后被使用的还是policy network.
Summary
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









