







 本文介绍了决策树的生成过程,强调了其作为分类模型的解释性和效率。通过水果分类的例子阐述了如何利用特征(如形状、大小)进行递归划分。讨论了信息熵的概念,它是衡量样本集合纯度的指标,用于确定最佳划分属性。信息增益公式用于比较不同特征的重要性。此外,文章还提及了决策树可能存在的过度拟合问题及其解决方法——剪枝,包括预剪枝和后剪枝。最后,作者指出这仅是决策树的基础,后续会涉及更多相关内容。
本文介绍了决策树的生成过程,强调了其作为分类模型的解释性和效率。通过水果分类的例子阐述了如何利用特征(如形状、大小)进行递归划分。讨论了信息熵的概念,它是衡量样本集合纯度的指标,用于确定最佳划分属性。信息增益公式用于比较不同特征的重要性。此外,文章还提及了决策树可能存在的过度拟合问题及其解决方法——剪枝,包括预剪枝和后剪枝。最后,作者指出这仅是决策树的基础,后续会涉及更多相关内容。
决策树生成是一个递归过程,是一种简单高效并且具有强解释性的模型,广泛应用于数据分析领域。其本质是一颗由多个判断节点组成的“树”。
有一堆水果,其中有香蕉,苹果,杏这三类,现在要对它们分类,可以选择的特征有两个:形状和大小,其中形状的取值有个:圆形和不规则形,大小的取值有:相对大和相对小。现在要对其做分类,我们可以这样做:
首先根据特征:形状,如果不是圆形,那么一定是香蕉,这个就是叶子节点;
如果是圆形,
再进一步根据大小这个特征判断,如果是相对大的,则是苹果,如果否,则是杏子,至此我们又得到两个叶子节点,并且到此分类位置,都得到了正确划分三种水果的方法。
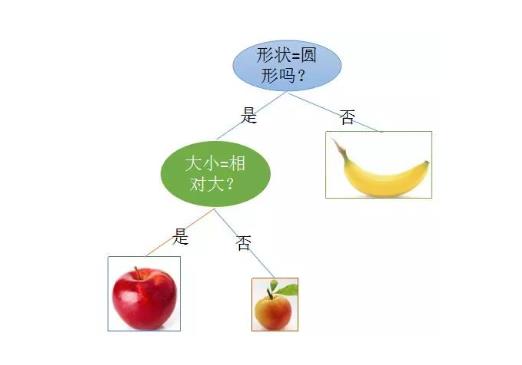
这就是一个决策分类,构建树的一个过程,说成是树,显得有点高大上,再仔细想想就是一些列 if 和 else 的嵌套,说是树只不过是逻辑上的一种神似罢了。
刚才举的这个例子,有两个特征:形状和大小,并且选择了第一个特征:形状作为第一个分裂点,大小作为第二个分裂点,那么不能选择第二个特征作为第一分裂点吗? 这样选择有没有公式依据呢?
先提一个概念:信息熵。是度量样本集合纯度最常用的一种指标。其实就是纯度
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7204
7204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









