









一、树
1. 树的定义和术语
(1) 树的定义和术语

- 树是一种分层次组织结构,这种结构在管理上具有更高的效率
- 数据管理的基本操作之一:查找
- 空树:包含零个结点
- 根(root):用
r表示。是每棵树(包括子树)的最上面的结点 - 子树(SubTree):根以外的结点可以分为若干互不相交的有限集,每个集合本身又是一棵树,称为原来树的子树(SubTree)
- 结点的度(Degree):结点的子树个数
- 树的度:树的所有结点中最大的度
- 叶节点(Leaf):度为0的结点。如
F、L等 - 父结点(Parent):有子树的结点是其子树的根结点的父结点。如
B是G的父结点 - 子结点(Child):也成为孩子结点。如
G是B的子节点 - 兄弟结点(Sibling):具有同一父结点的各结点彼此是兄弟结点。如
B、C、D互为兄弟结点 - 路径:从结点 n 1 n_1 n1 到 n k n_k nk 的路径可以看做一个结点序列 n 1 , n 2 , . . . , n k n_1,n_2,...,n_k n1,n2,...,nk ,该序列中相邻的结点时父子结点的关系
- 路径的长度:路径所包含的边的个数
- 祖先结点(Ancestor):沿树根到某一结点路径上的所有结点都是这个结点的祖先结点
- 子孙结点(Descendant):某一结点的子树中所有结点时这个结点的子孙
- 结点的层次(Level):规定根结点在 1 层,其他任何结点的层数是其父结点的层数加 1。即结点所在的层数
- 树的深度(Length):树中所有结点中的最大层次是这棵树的深度
(2) 树的规则
- 在由查找方法导出的判定树中,树上的每个结点需要查找的次数刚好为该结点所在的层数
- 查找成功时,查找次数不会超过树的深度
- n n n 个结点的判定树的深度是 [ l o g 2 n ] + 1 [log_2n]+1 [log2n]+1
- 平均查找次数(ASL):
若树的第 n i n_i ni 层有 m j m_j mj 个结点,且一共有 p p p 个元素,则平均查找次数如下
A S L = ∑ i j n i m j p ASL = \frac{\sum_{ij}n_im_j}{p} ASL=p∑ijnimj
(3) 查找
- 查找,指根据某个给定的关键字 K K K,从集合 R R R 中找出内容中与 K K K 相符的记录
- 查找的分类
- 静态查找:集合中的记录是固定的
不进行插入和删除操作,只是查找 - 动态查找:集合中的记录是变化的
有查找、插入和删除操作
- 静态查找:集合中的记录是固定的
- 子树互不相交
- 除了根结点外,每个结点有且仅有一个父结点。根结点没有父结点
- 一棵 N N N 个结点的树有 N − 1 N-1 N−1 条边
(4) 静态查找
问题情境:在数组中查找某元素
方法1:顺序查找
顺序查找算法的时间复杂度为 O ( n ) O(n) O(n)
struct LNode {
ElementType Element[MAXSIZE]; // 存放数组元素
int length; // 数组中元素的个数
};
typedef struct LNode *List;
/* 功能:在Element[1]~Element[n]中查找关键字为K的数据元素
* 输入:List Tbl 数组的首地址。下标为0的元素是哨兵,剩下的元素是数据元素
* ElementType K 要查找的关键字
* 输出:int i 查找的数据元素的下标。没有找到时返回 0
*/
int SequentialSearch(List Tbl, ElementType K) {
int i;
Tbl->Element[0] = K; // 建立哨兵。使下面的for语句的判断中不需要对i>0进行判断
// 从length开始,到1结束,查找数组里的元素
for (i = Tbl->length; Tbl->Element[i] != K; i--) {};
return i;
}
方法2:二分查找(Binary Search)
前提: n n n 个数据元素的关键字是有序的,且存放在连续存储结构中(如数组)
/* 功能:二分查找算法。在表Tbl中查找关键字为K的数据元素
* 输入:List Tbl 数组首地址
* ElementType K 要查找的关键字
* 输出:int mid 查找到的元素下标。-1表示没有找到
* 注意:数组中的元素按照从左到右,从小到大的顺序排列的
*/
int BinarySearch(List Tbl, ElementType K) {
int left, right, mid, NoFound = -1;
left = 1; // 初始左边界
right = Tbl->Length; // 初始右边界
while (Tbl->length) {
mid = left + (right - left) / 2; /* 计算中间元素下标,
同时防止left和right太大导致mid溢出 */
if (K < Tbl->Element[mid]) {
right = mid - 1; // 调整右边界
} else if (K > Tbl->Element[mid]) {
left = mid + 1; // 调整左边界
} else {
return mid; // 查找成功,返回数据元素下标
}
}
return NoFound;
}
2. 二叉树
树最好使用链表存储,且链表需要使用儿子-兄弟表示法构造结点


(1) 二叉树的定义
- 二叉树
T:一个有穷的结点集合- 这个集合可以为空
- 若不为空,则它是由根结点和称为器左子树 T L T_L TL 和右子树 T R T_R TR 的两个互不相交的二叉树组成
- 二叉树的子树有左右顺序之分
- 二叉树
T的五种基本形态:- 空树
- 只有一个结点
- 一个结点和对应的左子树,右子树为空
- 一个结点和对应的右子树,左子树为空
- 一个结点和对应的左右子树
(2) 特殊二叉树
- 斜二叉树(Skewed Binary Tree)

- 完美二叉树(Perfect Binary Tree)或满二叉树(Full Binary Tree)

- 完全二叉树(Complete Binary Tree)
- 按从上到下、从左到右的顺序存储 n n n 个结点的完全二叉树的结点父子关系
- 相当于满二叉树的叶结点那一层不完全,但缺少的那一层有特殊要求
上图的满二叉树中,若11到15删掉,则成为完全二叉树;若9和后面的其他任意若干叶结点删掉,则不是完全二叉树
(3) 二叉树的重要性质
- 一个二叉树第 i 层的最大结点数为: 2 i − 1 , i ≥ 1 2^{i-1},i≥1 2i−1,i≥1
- 深度为 k 的二叉树有最大结点总数: 2 k − 1 , k ≥ 1 2^k-1,k≥1 2k−1,k≥1
- 对任何非空二叉树
T,叶结点个数 = 度为 2 的非叶结点个数 + 1 - 非根结点(序号 i > 1)的父结点的序号为 [ i / 2 ] [i/2] [i/2]
- 结点(序号为 i)的左孩子结点的序号是 2 i 2i 2i(若 2 i ≥ 2i≥ 2i≥总结点数,则没有左孩子)
- 结点(序号为 i)的右孩子结点的序号是 2 i + 1 2i +1 2i+1(若 2 i + 1 ≥ 2i+1≥ 2i+1≥总结点数,则没有右孩子)
2. 二叉树的抽象数据类型
类型名称:二叉树
数据对象集:一个有穷的结点集合。若不为空结点,则由根结点和其左、右二叉子树组成
操作集:BT ∈ BinTree,Item ∈ ElementType,重要操作如下:Boolean IsEmpty(BinTree BT); // 判断BT是否为空树 void Traversal(BinTree BT); // 遍历树中的结点,按某顺序访问每个结点 BinTree CreatBinTree(); // 创建一个二叉树
- 二叉树遍历的核心问题:二维结构的线性化
- 从结点访问其左、右儿子结点
- 访问左儿子后,右儿子结点需要得到合适的处理
- 需要一个存储结构保存暂时不访问的结点
- 可用的存储结构:堆栈、队列
- 常用的遍历方法:
void PreOrderTraversal(BinTree BT); // 先序遍历:根、左子树、右子树
void InOrderTraversal(BinTree BT); // 中序遍历:左子树、根、右子树
void PostOrderTraversal(BinTree BT); // 后序遍历:左子树、右子树、根
void LevelOrderTraversal(BinTree BT); // 层次遍历(或 层序遍历):从上到下,从左到右
3. 二叉树的存储结构
(1) 顺序存储结构
- 可以用数组存储二叉树
- 一般二叉树可以补全为完全二叉树,但造成了许多空间的浪费

(2) 链表存储
struct TreeNode {
ElementType Data;
BinTree Left;
BinTree Right;
};
typedef struct TreeNode *BinTree;
typedef BinTree Position;


4. 链式存储结构二叉树的递归遍历
(1) 先序遍历
- 遍历过程为:
- 访问根结点
- 先序遍历其左子树
- 先序遍历其右子树
/* 功能:先序遍历二叉树
* 输入:BinTree BT 要遍历的树的首地址
* 输出:void
*/
void PreOrderTraversal(BinTree BT) {
if (BT) { // 若不是空树
printf("%d", BT->Data); // 遍历根结点
PreOrderTraversal(BT->Left); // 遍历左结点
PreOrderTraversal(BT->Right); // 遍历右节点
}
}
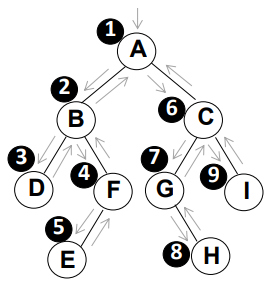
上图中黑底白字的数字表示遍历的先后顺序
(2) 中序遍历
- 遍历过程:
- 中序遍历其左子树
- 访问根结点
- 中序遍历其右子树
/* 功能:中序遍历二叉树
* 输入:BinTree BT 要遍历的树的首地址
* 输出:void
*/
void InOrderTraversal(BinTree BT) {
if (BT) {
InOrderTraversal(Bt->Left);
printf("%d", BT->Data);
InOrderTraversal(Bt->Right);
}
}
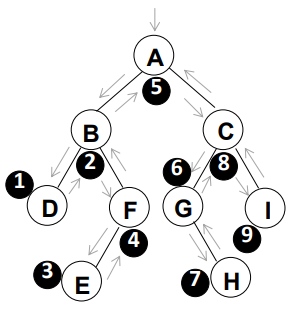
(3) 后序遍历
- 遍历过程:
- 后序遍历其左子树
- 后序遍历其右子树
- 访问根结点
/* 功能:后序遍历二叉树
* 输入:BinTree BT 要遍历的树的首地址
* 输出:void
*/
void PostOrderTraversal(BinTree BT) {
if (BT) {
PostOrderTraversal(Bt->Left);
PostOrderTraversal(Bt->Right);
printf("%d", BT->Data);
}
}

先序、中序和后序遍历过程中经过结点的路线一致,只是访问各结点(即各子树的根结点和叶结点)的时机不同
下图为结果结点的路线。可知,每一棵子树的根结点都经过了三次。
- 第一次经过根结点,就访问其中的数据,是先序遍历
- 第二次经过根结点,就访问其中的数据,是中序遍历
- 第三次经过根结点,就访问其中的数据,是后序遍历

5. 链式存储结构二叉树的非递归遍历
- 下面以中序遍历非递归遍历为例,关键是使用堆栈实现遍历
- 先序遍历、后序遍历同理
- 算法逻辑:
- 遇到一个结点,就把它压栈,并遍历其左子树
- 当左子树遍历结束后,从栈顶弹出这个结点,并访问它
- 然后按其右指针再去中序遍历该结点的右子树
/* 功能:链式存储结构二叉树的中序非递归遍历
* 输入:要遍历的二叉树
* 输出:void
*/
void InOrderTraversal(BinTree BT) {
BinTree T = BT; // T是临时变量
Stack S = CreatStack(MaxSize); // 创建并初始化堆栈
while (T || !IsEmpty(S)) { // 若树不空或堆栈不空
/* 一直向左并将沿途结点压入堆栈 */
while (T) { // 若堆栈不空
Push(S, T); // 经过的结点入栈
T = T->Left; // 当T=NULL时退出本循环
}
/* 已经定位到左子树的第一个要输出的结点,之后按照中序遍历的顺序输出 */
if (!IsEmpty(S)) { // 若堆栈不空
T = Pop(S); // 栈顶结点出栈。栈顶结点是二叉树中最左边的结点(简记为A)
printf("%5d", T->Data); // 访问结点A
T = T->Right; // 转向右子树。当T=NULL,但堆栈不为空时,最外层的大循环继续执行
}
}
}
6. 层序遍历
- 使用队列实现:遍历从根结点开始,先将根结点入队,然后开始执行循环:结点出队、访问该结点、其左右儿子结点入队

- 算法逻辑:先将根结点入队,然后执行下列操作
- 从队列中取出一个元素
- 访问该元素所指结点
- 若该元素所指结点的左、右孩子结点非空,则将其左、右孩子的指针顺序入队
/* 功能:队列实现层序遍历
* 输入:BinTree BT 要遍历的目标树的首地址
* 输出:void
*/
void LevelOrderTraversal(BinTree BT) {
Queue Q;
BinTree T;
if (!BT) { // 若目标对象是空树
return; // 则直接退出函数
}
Q = CreatQueue(MaxSize); // 创建并初始化队列Q
AddQ(Q, BT); // 将根结点添加到队列中去
while (!IsEmptyQ(Q)) {
T = DeleteQ(Q); // 队头结点出队
printf("%d\n", T->Data); // 访问出队的结点
if (T->Left) {
AddQ(Q, T->Left); // 将左儿子结点添加到队列中
}
if (T->Right) {
AddQ(Q, T->Right); // 将右儿子结点添加到队列中
}
}
}
7. 遍历二叉树的应用
(1) 输出二叉树中的叶子结点
/* 功能:输出二叉树中的叶子结点
* 输入:BinTree BT 叶子结点所在的树
* 输出:void
*/
void PreOrderPrintLeaves(BinTree BT) {
if (BT) {
if (!BT->Left && !BT->Right) {
printf("%d", BT->Data); // 某结点的左右结点为空,表明该结点是叶子结点
}
PreOrderPrintLeaves(BT->Left);
PreOrderPrintLeaves(BT->Right);
}
}
(2) 求二叉树的高度
/* 功能:求二叉树的高度(深度)
* 输入:BinTree BT 求深度的树
* 输出:int 树的深度
*/
int PostOrderGetHeight(BinTree BT) {
int HL, HR, MaxH;
if (BT) {
HL = PostOrderGetHeight(BT->Left); // 求左子树的深度
HL = PostOrderGetHeight(BT->right); // 求右子树的深度
MaxH = (HL > HR) ? HL : HR; // 取左右子树深度的最大值
return (Max + 1); // 返回整棵树的深度
} else {
return 0; // 定义空树的深度为0
}
}
(3) 运算表达式树及其遍历
- 叶子结点表示运算数或者是字母
- 根结点表示运算符

- 上图中,不同的遍历得到不同的表达式:
- 先序遍历得到前缀表达式: + + a ∗ b c ∗ + ∗ d e f g ++a*bc*+*defg ++a∗bc∗+∗defg
- 中序遍历得到中缀表达式:
a
+
b
∗
c
+
d
∗
e
+
f
∗
g
a+b*c+d*e+f*g
a+b∗c+d∗e+f∗g
- 由于中缀表达式需要考虑运算符的优先级,所以在遍历左右子树时,在遍历子树前加左括号,在遍历子树后加右括号
- 后序遍历得到后缀表达式: a b c ∗ + d e ∗ f + g ∗ + abc*+de*f+g*+ abc∗+de∗f+g∗+
(4) 由先序、中序、后序遍历确定二叉树结构
- 方法是,从这三种遍历方式中,取中序遍历和其余两种中任何一种遍历方式,即可确定二叉树的结构
- 只根据先序和后序遍历无法准确确定二叉树的结构
情景1:先序和中序遍历序列确定一棵二叉树
- 方法
- 根据先序遍历序列第一个结点确定根结点;
- 根据根结点在中序遍历序列中分割出左右两个子序列;
- 对左子树和右子树分别递归,使用相同的方法继续分解
情景2:后序和中序遍历序列确定一棵二叉树
(5) 树的同构问题:判断某两棵树是否为同构的
- 同构:给定两棵树
T1和T2。若T1可以通过若干次左右孩子互换就变成了T2,则我们称两棵树是“同构”的

题目:输入两棵二叉树的信息,比较他们是否是同构
输入要求:
- 先在一行中给出该树的结点数
- 第
i(从零开始计数)行对应编号第i个结点,给出该结点中存储的字母、其左孩子结点的编号、右孩子结点的编号- 若孩子结点为空,则在相应位置上给出
-- 输入样例如下:
关键:
- 二叉树的表示
- 建立二叉树
- 同构的判别


0x00 二叉树的表示
- 用链表结构表示
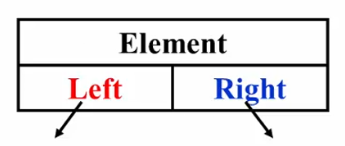
- 用数组结构表示
-
一般数组:将给定的二叉树看成完全二叉树存储

-
结构数组(物理存储结构是数组,组成思想是静态链表)
- 存储结构如下
- 第一行是该结点的信息,第二行是左结点,第三行是右结点,第二三行存储结点的编号。
-1表示为空

由上图可知,一共有四个结点,分别用0、1、2、3表示,而表格中左右结点编号中只出现1、2、3,所以编号为0的结点就是根结点,即A是根结点
- 第一行是该结点的信息,第二行是左结点,第三行是右结点,第二三行存储结点的编号。
- 存储结构如下
-
#define MaxTree 10
#define ElementType char
#define Tree int
#define Null -1
struct TreeNode {
ElementType Element;
Tree Left; // 左结点编号
Tree Right; // 右结点编号
} T1[MaxTree], T2[MaxTree];
0x01 程序框架搭建
int main(void) {
Tree R1, R2;
R1 = BuildTree(T1); // 建立二叉树T1
R2 = BuildTree(T2); // 建立二叉树T2
if (Isomorphic(R1, R2)) { // 判断是否同构
printf("Yes\n");
} else {
printf("No\n");
}
return 0;
}
/* 功能:建立二叉树
* 输入:struct TreeNode T[] 二叉树首地址
* 输出:Tree Root 根结点的编号
*/
Tree BuildTree(struct TreeNode T[]) {
Tree Root, i;
scanf("%d\n", &N); // 输入二叉树的结点个数
if (N) {
for (i = 0; i < N; i++) {
check[i] = 0;
}
for (i = 0; i < N; i++) {
scanf("%c %c% %c\n", &T[i].Element, &cl, &cr); // 输入各结点信息
if (cl != '-') { // 若结点的左结点不为空
T[i].Left = cl - '0'; // 将数字字符转换为对应的数值,表示现在处于的结点编号
check[T[i].Left] = 1; // 当前结点的左结点不为空,表示当前结点不是根结点,标记为1
} else { // 左结点为空
T[i].Left = Null;
}
if (cr != '-') { // 若结点的右结点不为空
T[i].Left = cr - '0'; // 将数字字符转换为对应的数值,表示现在处于的结点编号
check[T[i].Right] = 1;
} else { // 右结点为空
T[i].Right = Null;
}
}
for (i = 0; i < N; i++) { // 遍历check数组,i代表结点编号,check[i]表示结点是否为根结点,值为0时表示跟结点
if (!check[i]) {
break;
}
}
Root = i; // 找到了根结点的编号,并返回
}
return Root;
}
/* 功能:判断两个二叉树是否同构
* 输入:Tree R1 第1棵树当前的结点编号
* Tree R2 第2棵树当前的结点编号
* 输出:1 同构
* 0 不同构
*/
int Isomorphic(Tree R1, Tree R2) {
if ((R1 == Null) && (R2 == Null)) { // 两棵树均为空树,则他们同构
return 1;
}
if (((R1 == Null) && (R2 != Null)) || ((R1 != Null) && (R2 != Null))) { // 若两棵树中有一棵树为空树,则他们不同构
return 0;
}
if (T1[R1].Element != T2[R2].Element) { // 两棵树的根结点不相等,则他们不同构
return 0;
}
if ((T1[R1].Left == Null) && (T2[R2].Left == Null)) { // 若两棵树的当前节点都没有左子树
return Isomorphic(T1[R1].Right, T2[R2].Right); // 根据两棵树的右子树判断是否同构
}
if ((T1[R1].Left != Null) && (T2[R2].Left != Null) && (T1[T1[R1].Left].Element == T2[T2[R2].Left].Element)) {
// 若两棵树的当前节点的左结点相等且非空
return (Isomorphic(T1[R1].Left, T2[R2].Left) && Isomorphic(T1[R1].Right, T2[R2].Right)); /* 目前遍历过的结点的
位置和内容都相同,则继续判断 */
} else {
return (Isomorphic(T1[R1].Left, T2[R2].Right) && Isomorphic(T1[R1].Right, T2[R2].Left)); /* 判断是否可能是一棵树的
左子树与另一棵树的右子树同构 */
}
}















 403
403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









