







Boosting Adversarial Attacks with Momentum(CVPR2018)
Source Code:
https://github.com/dongyp13/Non-Targeted-Adversarial-Attacks
https://github.com/dongyp13/Targeted-Adversarial-Attacks.
文章概述: 本文提出了一种基于动量法(Momentum)的迭代生成对抗样本的方法,这种方法可以在迭代过程中稳定更新方向并避免糟糕的局部最大值(local maxima),从而产生更可转移(transferable)的对抗性示例,并且不仅对"白盒"模型攻击有效,对"黑盒"模型攻击也同样有效。
本文方法生成的对抗样本初览:
可以看出,对抗样本在一定程度上是增加了奇奇怪怪的纹路,对于常人而言,只会觉得是的"这张图不够清晰",并且会主动过滤掉,而只对总体图像进行分析,所以对常人而言,是不会误判的。而对于CNN,其实对于每一个卷积核,其实在某种程度上是一种"算子",提取的是图像中的纹理特征,对于卷积核而言,可能更加关注的是纹理特征,而无法把握总体特征,因此会误判。
我的猜想:会不会有一种可能,是因为卷积核的性质才导致了网络的不稳定性?大一点的卷积核是否在一定程度上因为关注的区域变大而忽略细小纹理从而变得更加robust?

文中猜想(或结论、现有研究的优缺点)的整理:
- 可转移性(transferable)现象是由于不同的机器学习模型在一个数据点周围学习相似的决策边界,使得为一个模型设计的对抗性示例对其他模型也有效。
- optimization-based和iterative方法产生的对抗样本在可转移性上表现比较差,因此对黑盒模型的攻击比较低效;one-step gradient方法能产生更可转移的对抗性例子,但是它们通常对白盒模型的成功率较低,使得它对黑盒攻击无效。
- 已经有研究表明,对于白盒模型而言,iterative方法比one-step方法有更高的成功率,但是这是以更差的可以转移性作为代价的。
- optimization-based方法的缺点是无法保证对抗样本的 “保真性”,即可能增加的扰动足以让人眼明显感觉到(其优化的目标函数如下)。
arg min x ∗ λ ⋅ ∣ ∣ x ∗ − x ∣ ∣ p − J ( x ∗ , y ) \mathop{\arg\min}\limits_{x^*} \lambda \cdot||x^* - x||_p - J(x^*, y) x∗argminλ⋅∣∣x∗−x∣∣p−J(x∗,y)
本文的方法:
case 1:MI-FGSM
[无聊的补充知识]: MI即为Momentum iterative的缩写
作者的思路来源: 借鉴物理学上的动量思想,在优化时越过local maxima,增大到达global maxima的机会。其实不太理解的是,对于这种迭代的更新步骤,local maxima和global maxima到底意味着什么? 为什么减小陷入local maxima的几率就能让攻击效果更好(主要是这里并未出现所谓的目标函数)
与iterative FGSM的对比: 其主要的不同点在于iterative FGSM方法中,sign函数中的内容为
▽ X J ( X , y ) \triangledown_X J(X, y) ▽XJ(X,y)
而本文sign函数中的内容,则为下图中的公式(6)。这种动量的思想,其实包含了一种指数衰减平均的思想,其好处在于,能够使目标函数优化方向振幅减小,更易朝着global maxima目标前进,此外还不容易陷入local maxima。
此外,通过L1范数的约束,能够使各个方向的偏导数归一化,因为作者注意到,每次迭代时,这个损失函数的梯度变化量级非常大。

case 2: ensemble
作者尝试了三种集成的策略,分别是
l
(
x
)
=
∑
k
=
1
K
w
k
l
k
(
x
)
l(x) = \sum_{k=1}^{K} w_k l_k(x)
l(x)=k=1∑Kwklk(x)
p
(
x
)
=
∑
k
=
1
K
w
k
p
k
(
x
)
p(x) = \sum_{k=1}^{K} w_k p_k(x)
p(x)=k=1∑Kwkpk(x)
J
(
x
)
=
∑
k
=
1
K
w
k
J
k
(
x
)
J(x) = \sum_{k=1}^{K} w_k J_k(x)
J(x)=k=1∑KwkJk(x)
其中
w
k
w_k
wk是第k个模型对应的权重
l
k
(
x
)
l_k(x)
lk(x)表示的是,第k个模型输入softmax的logits
p
k
(
x
)
p_k(x)
pk(x)表示的是,第k个模型softmax输出的prediciton
J
k
(
x
)
J_k(x)
Jk(x)表示的是,第k个模型计算得到的loss
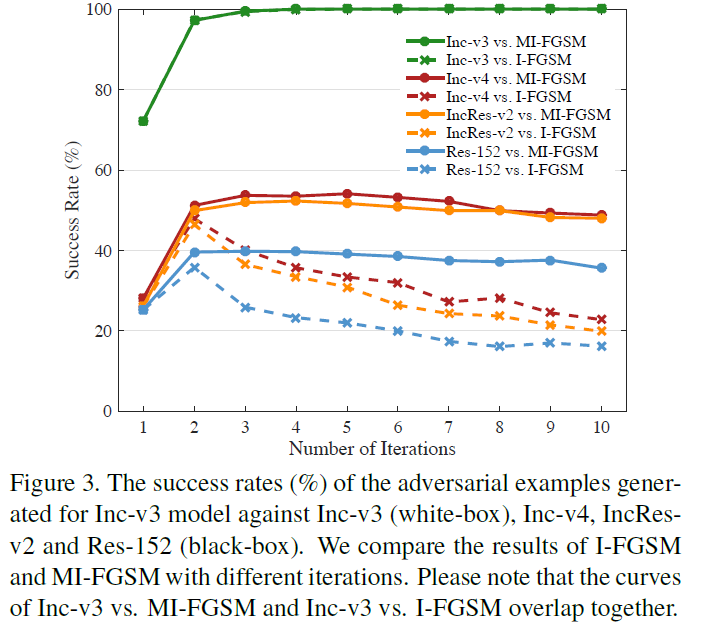
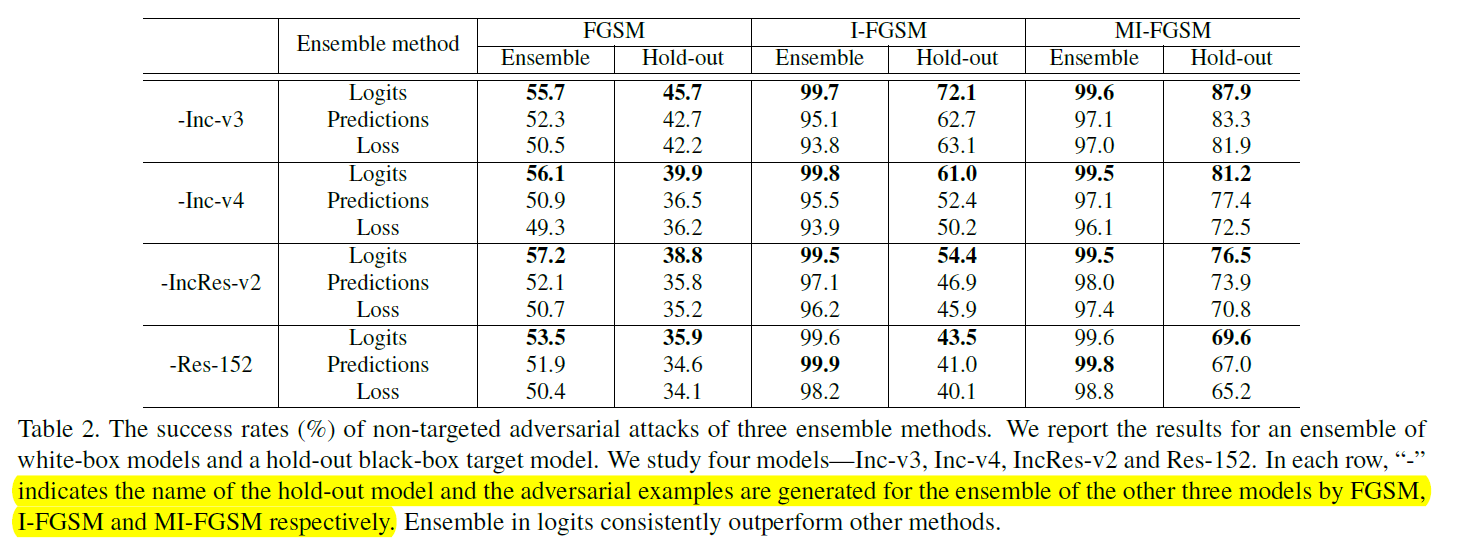
不同策略的攻击效果如下。其中hand-out表示的是不参与训练对抗样本的黑盒模型。从下图中可以获得以下结论:
- 采用
logits集成的策略在总体攻击效果上比其他两者更加有效。 - 本文提出的
MI-FGSM对白盒和黑盒模型都具有更好的攻击效果,即可迁移性(transferable)更好(因为其对黑盒模型的攻击效果远好于I-FGSM方法)。

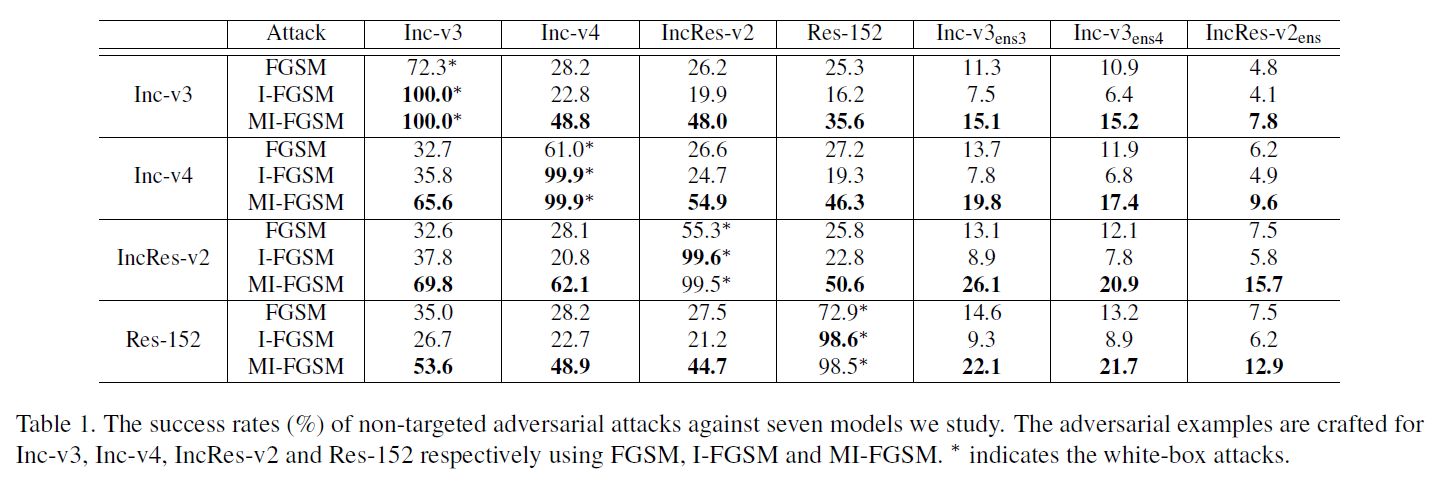
且相比于不采用ensemble策略的MI-FGSM而言,可迁移性也更强!下图为不采用ensemble策略的MI-FGSM效果。
由于这些笔记是之前整理的,所以可能会参考其他博文的见解,如果引用了您的文章的内容请告知我,我将把引用出处加上~
如果觉得我有地方讲的不好的或者有错误的欢迎给我留言,谢谢大家阅读(点个赞我可是会很开心的哦)~















 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









