







 本文介绍了一种结合动量的迭代算法,用于增强对抗样本的生成,尤其是在黑盒模型上的效果。通过累加速度矢量,算法能稳定更新方向,避免局部最优点,提高对抗样本的可迁移性。研究发现,尽管模型间的决策边界相似导致对抗样本的迁移性,但深度神经网络的非线性结构可能导致局部最大值,影响迁移。论文提供了与FGSM和MI-FGSM的对比,并给出了源代码链接。
本文介绍了一种结合动量的迭代算法,用于增强对抗样本的生成,尤其是在黑盒模型上的效果。通过累加速度矢量,算法能稳定更新方向,避免局部最优点,提高对抗样本的可迁移性。研究发现,尽管模型间的决策边界相似导致对抗样本的迁移性,但深度神经网络的非线性结构可能导致局部最大值,影响迁移。论文提供了与FGSM和MI-FGSM的对比,并给出了源代码链接。
本文提出一个基于动量(Momentum)的迭代算法,该方法通过梯度以迭代的方式对输入进行扰动以最大化损失函数,并且该方法还会在迭代过程中沿损失函数的梯度方向累加速度矢量,目的是稳定更新方向并避免糟糕的局部最大值。从而产生更好的可迁移(transferable)的对抗样本,解决了对抗样本生成算法对于黑盒模型的低成功率问题。
文中提到:
- 对抗样本迁移性的现象是由于不同的机器学习模型在数据点周围学习到相似的决策边界这一特性导致的,使得针对一种模型设计的对抗样本也对其他模型有效。
- 基于优化的方法以及基于迭代的方法生成的对抗样本可转移性都较差,对于黑盒攻击的成功率也较低。
- 基于单步梯度的方法虽然能生成更具迁移性的对抗样本,但由于对白盒模型的成功率较低,使得对于黑盒攻击基本无效。
- 集成对抗训练( Ensemble adversarial training )可以显著的增加模型对对抗样本的鲁棒性。
MI-FGSM算法:

动量法是一种通过在迭代过程中沿损失函数的梯度方向累加速度矢量来加速梯度下降算法的技术。动量法也显示出其在随机梯度下降中稳定更新的有效性。
生成不定向对抗样本的优化问题为:
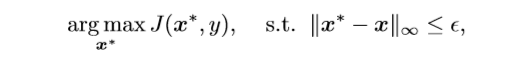
针对集成模型的MI-FGSM算
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1009
1009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









