










这篇论文是facebook AI在2017年的ICLR会议上发表的,文章提出了Recurrent Entity Network的模型用来对world state进行建模,根据模型的输入对记忆单元进行实时的更新,从而得到对world的一个即时的认识。该模型可以用于机器阅读理解、QA等领域。本文参考了Google团队的NTM和其他的神经计算单元,能够基于内容和位置对记忆单元进行读写操作。本文在babi-10k的数据集和Children’s Book Test(CBT)的数据集上实现了最优的结果。
在github上已经有实现babi-10k数据集的entity network的代码,因此便不再自己实现,而把精力主要集中在模型的构建上。
数据处理
babi数据集的处理,在本专栏的前几篇文章中已经叙述很多了,这里不再赘述。
模型构建
和之前的模型一样,Entity Network模型共分为Input Encoder、Dynamic Memory和Output Model三个部分。如下图的架构图所示:
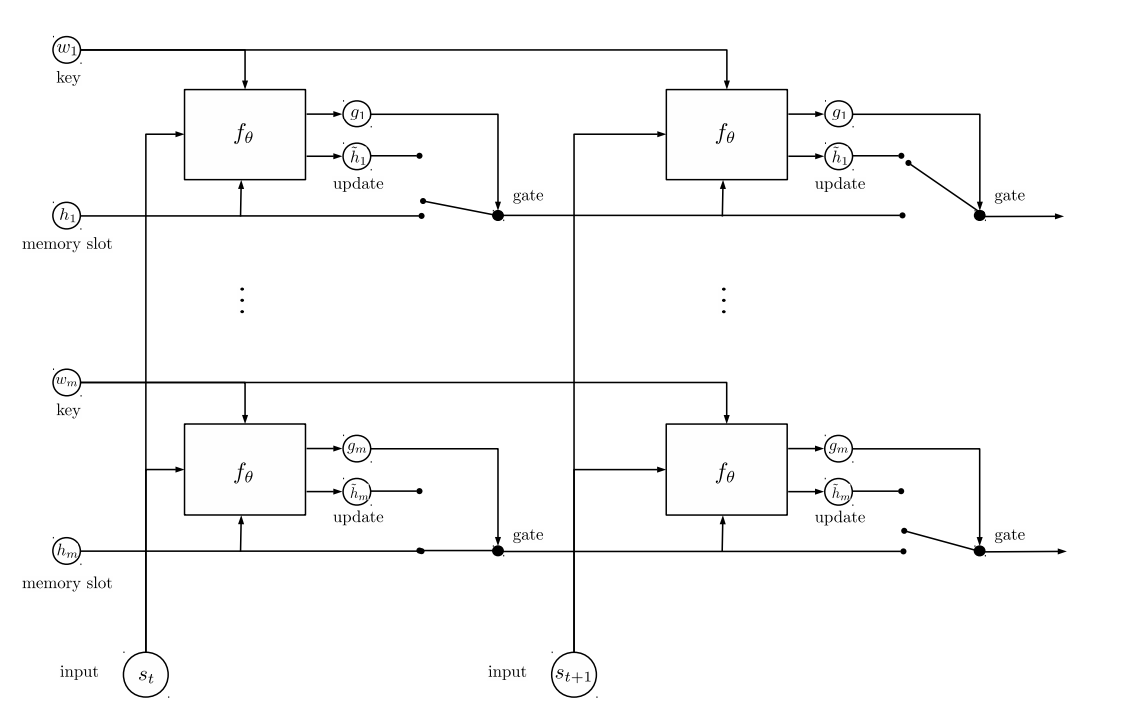
Input Encoder
Input Encoder部分将输入的句子序列编码为一个固定长度的向量,此时典型的对句子的处理方式有:
- 词袋子编码向量(对于词表vocab和句子s,对于句子中的所有词w1/s2/…/wn赋权值,但是如果vocab很大的话效率就特别低)
- 利用RNN或者LSTM等时序神经网络模型,使用最后一个时间步长的状态作为句子编码
- 本文中采用将w1/s2/…/wn分别通过嵌入层,得到嵌入向量,然后进行位置编码,得到句子的向量表示,具体的句子位置编码的介绍在end to end memory network。
如下图:
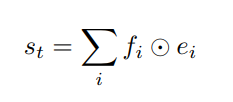
e1,...,ek e 1 , . . . , e k 为在时间步长t时输入的单词序列的嵌入表示, f1,...,fk f 1 , . . . , f k 是每一个位置的权重,得到的st就是固定长度的句子的向量表示。
Dynamic Memory
Entity network中,在时间步长t得到了t时刻句子的向量表示St。在St之上,有类似于多层GRU的单元即w1,h1,w2,h2,…wm,hm。其中,{w}是key,负责记录实体;{h}是value,负责记录该实体的状态。在时间步长t,{h}由{w}和st两者进行更新,更新公式如下:
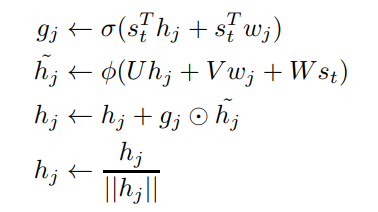
gj是一个sigmoid的门函数,用来决定第j层的记忆有多少需要被更新,由{w}和{h}共同决定;
hj˜ h j ~ 是记忆的候选值,由 hj,wj和st h j , w j 和 s t 共同决定,此处的 ϕ ϕ 可以是任意一个激活函数,本文中选定的是ReLU;
hj h j 就由门限函数gj和候选记忆 hj˜ h j ~ 来决定;
然后将hj进行正则化,至于为什么正则化,我猜想应该是保证 hj˜ h j ~ 和 hj h j 在同一个区间内,这样进行更新才有意义。
论文中第三章给出了一个非常具体的例子:
- Mary picked up the ball.
- Mary went to the garden.
- Where is the ball?
前两句是文本,最后一句是问题。由第一句得到在时间步长t的句子表达st,由第二句得到时间步长t+1的句子表达st+1。以st和st+1来说明动态实体网络是如何捕捉输入从而对记忆单元进行实时的更新。
- 当st被读取,w1记录实体Mary,h1记录实体状态Mary拿了一个ball;
- w2记录实体ball,h2记录实体状态ball被Mary拿着;
- 然后st+1被读取,读取到Mary,因为w1是记录Mary的key,位置寻址项 sTt+1w1 s t + 1 T w 1 变化,门函数被激活,更新h1实体状态Mary去了garden;
- 因为h2记录ball被mary拿着,因此内容寻址项 sTt+1h2 s t + 1 T h 2 变化,门函数被激活,更新h2的实体状态球被mary拿着,球在garden。
即使 st+1 s t + 1 中没有提到和球有关的内容,在时间步长t+1,h2依然会被更新,是因为内容寻址项起了作用。我们称 sTtwj s t T w j 为位置寻址, sTthj s t T h j 为内容寻址。
Output Model
在原文中使用了一层的记忆网络,因此得到最后一个时间步长的隐层向量 hj h j 以后,就可以直接输出了:
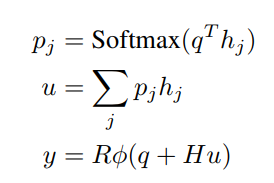
H是一个[hidden_size, hidden_size]的待训练矩阵;
R是一个[hidden_size, vocab_size]的待训练矩阵。
最后得到的y是一个vocab大小的向量,代表输出单词的概率,模型的部分也就到此结束了。
前文中已经提到,entity-network的结构类似于一个多层的GRU,因此在实现的时候,更改一下tensorflow中的cell的源码,使每一个cell都成为一个DynamicMemory,那么entity-network也就实现了。
class DynamicMemory(tf.contrib.rnn.RNNCell):
def __init__(self, memory_slots, memory_size, keys, activation=prelu,
initializer=tf.random_normal_initializer(stddev=0.1)):
"""
Instantiate a DynamicMemory Cell, with the given number of memory slots, and key vectors.
:param memory_slots: Number of memory slots to initialize.
:param memory_size: Dimensionality of memories => tied to embedding size.
:param keys: List of keys to seed the Dynamic Memory with (can be random).
:param initializer: Variable Initializer for Cell Parameters.
"""
self.m, self.mem_sz, self.keys = memory_slots, memory_size, keys
self.activation, self.init = activation, initializer
# Instantiate Dynamic Memory Parameters => CONSTRAIN HERE
self.U = tf.get_variable("U", [self.mem_sz, self.mem_sz], initializer=self.init)
self.V = tf.get_variable("V", [self.mem_sz, self.mem_sz], initializer=self.init)
self.W = tf.get_variable("W", [self.mem_sz, self.mem_sz], initializer=self.init)
@property
def state_size(self):
"""
Return size of DynamicMemory State - for now, just M x d.
"""
return [self.mem_sz for _ in range(self.m)]
@property
def output_size(self):
return [self.mem_sz for _ in range(self.m)]
def zero_state(self, batch_size, dtype):
"""
Initialize Memory to start as Key Values
"""
return [tf.tile(tf.expand_dims(key, 0), [batch_size, 1]) for key in self.keys]
def __call__(self, inputs, state, scope=None):
"""
Run the Dynamic Memory Cell on the inputs, updating the memories with each new time step.
:param inputs: 2D Tensor of shape [bsz, mem_sz] representing a story sentence.
:param states: List of length M, each with 2D Tensor [bsz, mem_sz] => h_j (starts as key).
"""
new_states = []
for block_id, h in enumerate(state):
# Gating Function
content_g = tf.reduce_sum(tf.multiply(inputs, h), axis=[1]) # Shape: [bsz]
address_g = tf.reduce_sum(tf.multiply(inputs,
tf.expand_dims(self.keys[block_id], 0)), axis=[1]) # Shape: [bsz]
g = sigmoid(content_g + address_g)
# New State Candidate
h_component = tf.matmul(h, self.U) # Shape: [bsz, mem_sz]
w_component = tf.matmul(tf.expand_dims(self.keys[block_id], 0), self.V) # Shape: [1, mem_sz]
s_component = tf.matmul(inputs, self.W) # Shape: [bsz, mem_sz]
candidate = self.activation(h_component + w_component + s_component) # Shape: [bsz, mem_sz]
# State Update
new_h = h + tf.multiply(tf.expand_dims(g, -1), candidate) # Shape: [bsz, mem_sz]
# Unit Normalize State
new_h_norm = tf.nn.l2_normalize(new_h, -1) # Shape: [bsz, mem_sz]
new_states.append(new_h_norm)
return new_states, new_states总结
实体网络提供了一种根据模型的输入对记忆单元进行实时的更新的记忆模型,在BABI和CBT数据集上都实现了最佳的效果。在论文的表4中,提供了在CBT数据集上EntNet与其他几个问答系统的模型的对比结果:
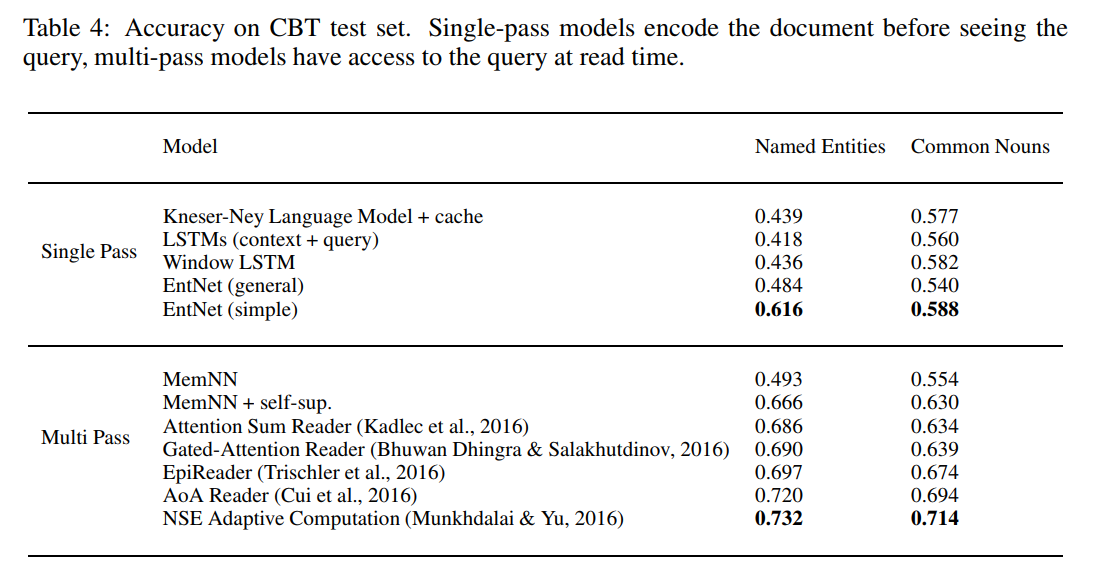
论文提供了两种模型构造的思路:单轮阅读和多轮阅读。
- 单轮阅读必须按顺序读story和query然后立即产生输出
- 多轮阅读可以使用通过多轮的阅读,使用query来构造story的attention。
因此单轮阅读是更有挑战性的,因为模型事先并不知道query是什么,所以必须学习保留对各种潜在query有用的信息,因此单轮阅读可以看作通用的(即不知道query的情况下)对模型构建“current state of story”能力的测试。而多轮阅读因为知道了问题,所以可以根据问题来选择性的读取story。
从上表中可以看出,在CBT数据集上一向表现不好的NE和CN两个子数据集,通过EntNet表现可以有很大的提升,但还是无法和更复杂的多轮阅读相提并论。多轮阅读中的MemNN
在前面已经做过讲解,接下来的几篇都是2016年各个自然语言处理顶会上的优秀模型,接下来的重点可以用来读一下这几篇论文,然后和EntNet在CBT数据集上的表现做一个对比。

















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









