







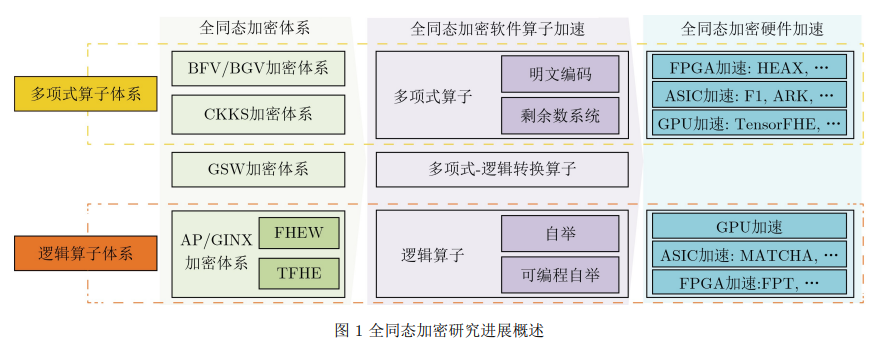
主流的全同态加密方案基于容错学习问题(Learning With Errors, LWE)及其代数变体环容错学习问题 (Ring Learning With Errors, RLWE),
包括 BFV[7]、BGV[8]、CKKS[9]、GSW[10]和TFHE[11]等。这些方案各自具有优点和局限性。
BGV和BFV方案适用于有限域上的计算,并具备高效的打包功能,但其不适用于具有大型乘法深度的电路或需要实现非线性函数的电路;
CKKS方案可以处理实数域上的计算,但是对于整数域上的精确计算存在局限性;
TFHE方案能够快速评估布尔电路,但其不支持批处理操作,无法同时处理同时大量数组。- 归类为AP/GINX加密体系。

软件
多项式方案主要基于RLWE 加密,包括BFV[7] , BGV[8]和CKKS[9],能够使用单指令-多数据(Single Instruction-Multiple Data, SIMD)对整数向量进行计算,从而实现快速的多项式运算。这些方案可以将多个明文打包成一个密码文本以提高并行度。为了进一步提升多项式函数的评估效率,不同的明文编码方式被提出以应对不同的计算需求。同时,为了解决密文模数Q 过大的问题,Garner等人[19]提出了剩余数系统(Residue Number System, RNS)方法。
明文编码
全同态加密中多项式算子的明文编码相关研究,包括频域编码和时域编码两种方式,具体内容如下:
-
频域编码
-
编码原理与应用:RLWE的明文空间多项式商环允许将复数域上的明文信息向量编码到环
上,频域编码可将输入信息从复数域映射到整数环上的多项式,如BFV体系中的数论变换(NTT)和CKKS体系中的离散傅里叶变换(DFT)都可视为频域编码,这种编码方法在CKKS自举中广泛应用。
- 计算优势与优化:频域编码支持密文的逐元素SIMD加法与乘法,可通过同态旋转操作实现同态求和、内积和卷积等计算,其中密文上的矩阵 - 向量乘在CKKS自举中有重要应用。为减少旋转操作耗时,提出了如将矩阵表示为对角矩阵并使用小步大步算法(BSGS)以及扩展对角线化思想到矩形矩阵等优化算法。
-
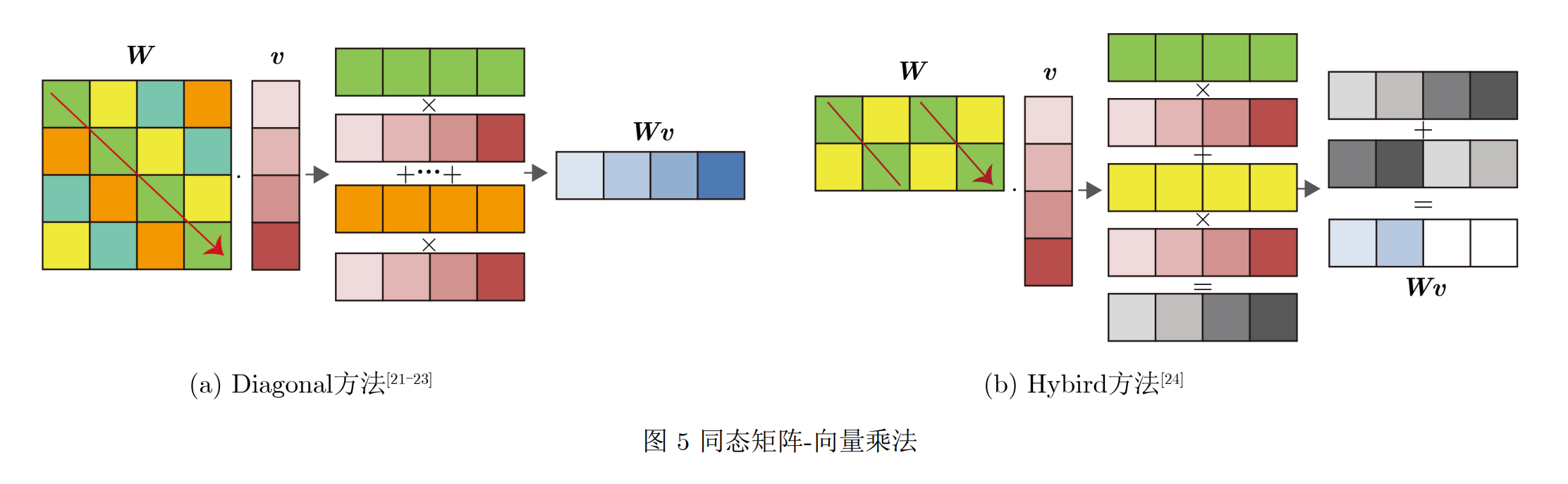
- 时域编码
- 编码定义与特点:消息
的明文编码多项式
定义为特定形式,通过这种编码可在不执行昂贵的同态旋转的情况下计算同态卷积和内积。
- 相关应用与改进:基于时域编码,Bian等人提出通用线性变换方法,通过修改加解密函数,可在不使用NTT和同态旋转算法的情况下同态评估线性变换,提高了同态卷积的计算和通信效率;文献[4]提出新型线性运算方法,通过适当排列多项式系数,将多项式乘法视为一系列内积运算,进一步提升了计算效率。
- 编码定义与特点:消息
以卷积为例,对于卷积操作作用在核为4维张量的3维张量
上生成3维张量
的情况,可以通过环
上的多项式乘积
来求解。其中,两个多项式
和
满足特定的系数排列方式,使得卷积操作能够转化为一系列内积运算。
剩余数系统(RNS)
阐述了为解决RLWE密文模数过大问题而引入的剩余数系统(RNS),包括其原理、在多项式运算中的实现方式以及在不同加密方案中的应用和改进,具体内容如下:
-
RNS原理与作用:为解决RLWE密文模数Q过大不适合实际计算的问题,利用中国剩余定理(CRT)将模数分解为互质因子的积,即
,可在表示为向量
的系数上进行算术操作,避免对大整数直接计算。
-
在多项式运算中的实现:Gentry等人提出基于双中国剩余定理的分圆多项式表示方案,将多项式分解为小模数的多项式分量,通过FFT转换为整数向量,多项式运算通过对不同分量进行模运算实现,类似方法也用于其他文献中。
-
在不同加密方案中的应用与改进
-
BFV方案扩展:Barjard等人将BFV中的密钥切换方法扩展到RNS中。
-
CKKS方案改进:Cheon等人提出CKKS自举及RNS变体,Han和Ki、Lee等人、Bossuat等人、Kim等人等分别对RNS - CKKS自举进行改进,包括同态模归约、三角函数逼近、并行工作、计算特定缩放因子、最小化计算误差等,提高了精度、效率和安全性。
-
硬件
依托可编程门阵列(Field-Programmable Gate Array, FPGA)、专用集成电路(Application-Specific Integrated Circuit, ASIC)、图形处理器(Graphics Processing Unit, GPU)等平台高并行性、高吞吐量的特点,提供全同态加密加速方案。
经典格密码同态加密方案硬件加速
-
最早可以追溯到2012年,Göttert等人[56]首次提出基于FPGA 的格密码硬件实现方案。Göttert等人先对基于RLWE的格密码方案进行了软件实现,从而验证了该方案的可行性;然后利用硬件描述性语言设计, 在
Xilinx Virtex-6 FPGA芯片上实现了同态加密中的格密码算法,该方案为同态加密开创了硬件加速架构设计的先河。 -
2012年,Pöppelmann等人[57]面向格密码设计了基于快速傅里叶变换/数论变换(Number Theoretic Transforms, NTT)的多项式高效模乘器并进行了FPGA实现测试,指出多项式环模乘运算是影响格密码等同态加密方案效率的核心因素之一,因此利用NTT计算电路大幅降低多项式模乘的算法复杂度,能够有效提高同态加密方案的运算效率。
-
2014年,Pöppelmann等人[58]利用基于FFT/NTT的多项式高效模乘器,在FPGA平台上实现了基于RLWE的格密码加密方案,并进行占用资源与性能评估。该实验结果证实了利用快速NTT多项式模乘器可以有效降低格密码硬件实现方案中的计算资源,并对基于格密码的同态加密方案提供了可观的加速效果。
BFV、BGV、CKKS主流同态加密方案硬件加速
硬件加速研究开始从FPGA扩展到了ASIC与GPU
-
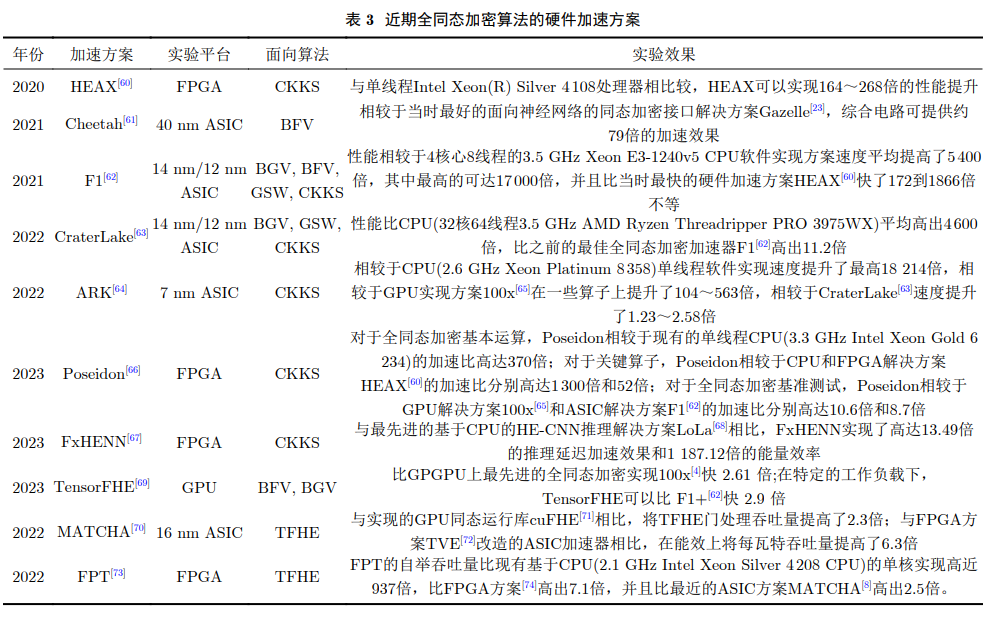
2020年,Riazi[60]等人提出了一种用于全同态加密的新型硬件架构HEAX,该架构有效加速了CKKS方案。Riazi等人首先提出了一种新的高度可并行化的数论变换架构,并在NTT引擎的基础上, 设计了一种用于同态加密数据计算的新型架构。通过在可重构硬件FPGA上进行实现,结果表明在全同态加密参数较大范围内,与单线程Intel Xeon(R) Silver 4 108处理器相比较,HEAX可以实现164- 268倍的性能提升。
-
2021年Reagen等人[61]提出了一种面向服务器端基于同态加密的深度神经网络 (Deep Neural Network, DNN)硬件加速架构Cheetah,该架构针对BFV同态加密方案进行加速,利用同态加密参数调整与算子调度优化技术,使用商用的40 nm单元库并以400 MHz为目标频率进行综合,相较于当时最好的面向神经网络的同态加密接口解决方案Gazelle[23],综合电路可提供约79倍的加速效果。
-
2021上,Samardzic等人[62]提出了一种支持多种同态加密算法的硬件加速器F1,该架构支持包括 BGV, BFV, GSW以及CKKS在内的多种主流的基 于RLWE的同态加密算法,为现在大部分同态加密方案提供加速服务。
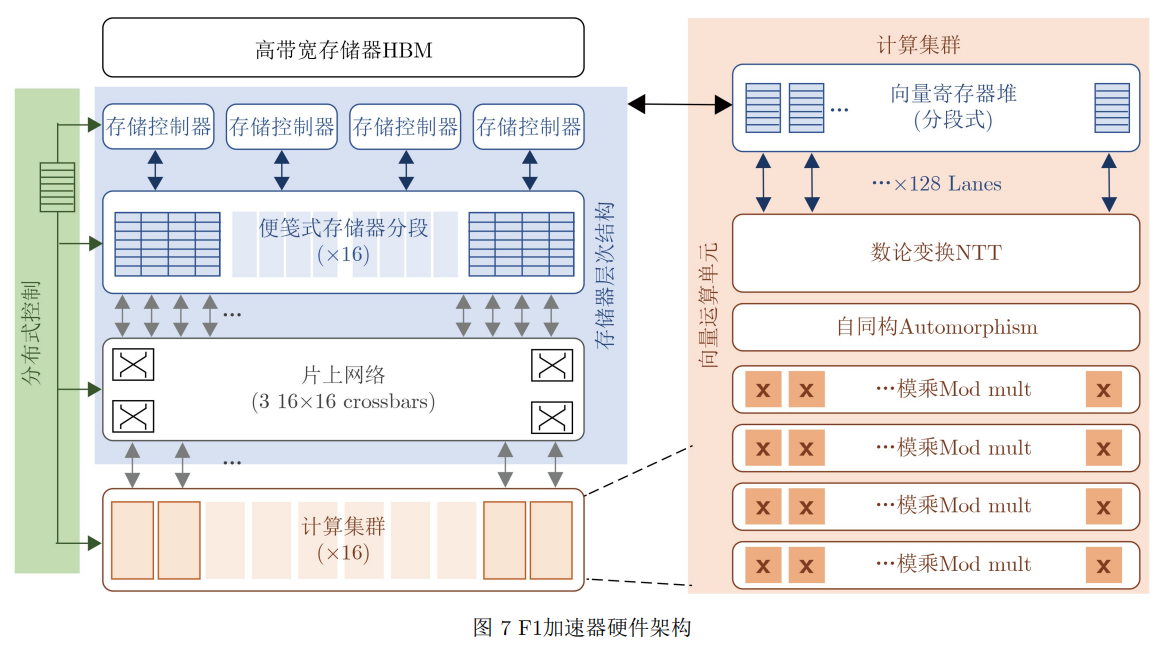
-
2022年,Samardzic等人[63]在研究了F1架构的基础上,提出了一种能够支持无限计算深度(即无限乘法深度)全同态加密方案的加速器CraterLake,支持BGV,GSW与CKKS方案。
-
Kim等人[64]于2022年提出了一种能够在程序运行时动态生成数据并重复使用内部运算密钥的全同态加速架构ARK,支持CKKS方案。
-
2023年最新的研究进展中,Yang等人[66]提出并在Xilinx AIveoU280 FPGA上实现了一种面向 CKKS方案的实用全同态加密加速器—Poseidon。
-
Zhu等人[67]于2023年提出了第1个用于基于全同态加密的卷积神经网络 (HE-CNN) 推理的完整 FPGA加速框架FxHENN,支持CKKS方案。
-
Fan等人[69]于2023年面向CKKS方案提出了一种基于GPGPU的全同态加密加速解决方案TensorFHE,该方案也可支持BFV与BGV方案, 比GPGPU上最先进的全同态加密实现100x[65]快 2.61倍。TensorFHE这 种基于高性能商用硬件的纯软件加速器的提出,为在实际系统中使用最先进的全同态加密算法提供了可能性。




















 679
679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









