







今日号外:🔥🔥🔥 DeepSeek开源周:炸场!DeepSeek开源FlashMLA,提升GPU效率

下面我们开始今天的主题,deepseek官方明确表示deepseek-r1目前不支持json输出/function call,可点击跳转至deepseek api查看。从deepseek-r1论文《DeepSeek-R1如何通过强化学习有效提升大型语言模型的推理能力》末尾对未来工作的展望中,我们知道deepseek团队将在deepseek-r1的通用能力上继续探索加强,包括函数调用、多轮对话、复杂角色扮演和json输出等任务上的能力。

如何解决DeepSeek-R1结构化输出问题,本文将使用PydanticAl和DeepSeek构建结构化Agent。
安装依赖
pip -q install pydantic-ai
pip -q install nest_asyncio
pip -q install devtools
pip -q install tavily-python# Jupyter环境,启用嵌套的异步事件循环
import nest_asyncio
nest_asyncio.apply()设置搜索Tavily
from tavily import TavilyClient, AsyncTavilyclient
#设置 Tavily客户端
tavily_client = AsyncTavilyClient(api_key=os.environ["TAVILY_API_KEY"])
#简单搜索
response=await tavily_client.search("介绍一下什么是deepseek R1?", max_results=3)
print(response['results'])设置DeepSeek模型
from pydantic_ai import Agent
from pydantic_ai.models.openai import OpenAIModel
# DeepSeekV3
deepseek_chat_model = OpenAIModel(
'deepseek-chat',
base_url='https://api.deepseek.com',
api_key=os.environ["DEEPSEEK_API_KEY"],
)
# DeepSeekR1
deepseek_reasoner_model = OpenAIModel(
'deepseek-reasoner',
base_url='https://api.deepseek.com',
api_key=os.environ["DEEPSEEK_API_KEY"],
)DeepSeekV3模型
首先我们来尝试使用DeepSeekV3模型来完成function call和json格式化输出问题。
from _future import annotations as annotations
import asyncio
import os
from dataclasses import dataclass
from typing import Any
from devtools import debug
from httpx import AsyncClient
import datetime
from pydantic_ai import Agent, ModelRetry, RunContext
from pydantic import BaseModel, Field
@dataclass
class SearchDataclass:
max_results: int
todays_date:str
@dataclass
class ResearchDependencies:
todays_date: str
class ResearchResult(BaseModel):
research_title:str=Field(description='这是一个顶级Markdown标题,涵盖查询和答案的主题,并以#作为前缀')
research_main:str=Field(description='这是一个主要部分,提供查询和研究的答案')
research_bullets:str=Field(description='这是一组要点,用于总结查询的答案')
## 创建代理
search_agent = Agent(deepseek_chat_model,
deps_type=ResearchDependencies,
result_type=ResearchResult,
system_prompt="你是一个乐于助人的研究助手,并且是研究方面的专家。
如果你收到一个问题,你需要写出强有力的关键词来进行总共3-5次搜索
(每次都有一个query_number),然后结合结果")
@search_agent.tool #Tavily
async def get_search(search_data:RunContext[SearchDataclass],query: str,query_number: int) -> dict[str,Any]
"""获取关键词查询的搜索结果。
Args:
query:要搜索的关键词。
"""
print(f"Search query {query_number}:{query}")
max_results = search_data.deps.max_results
results = await tavily_client.get_search_context(query=query, max_results=max_results)
return results
## 设置依赖项
# 获取当前日期
current_date=datetime.date.today()
# 将日期转换为字符串
date_string = current_date.strftime("%Y-%m-%d")
deps = SearchDataclass(max_results=3, todays_date=date_string)
result = await search_agent.run('你能给我用中文详细分析一下 DeepSeekR1模型吗', deps=deps)
print(result.data.research_title)
print(result.data.research_main)
print(result.data.research_bullets) DeepSeek-R1模型
class LifeMeaningStructuredResult(BaseModel):
life_meaning_title:str = Field(description='这是一个顶级的Markdown标题,涵盖查询的主题和答案,以#开头')
life_meaning_main: str = Field(description='这是提供查询和问题答案的主要部分')
life_meaning_bullets: str= Field(description='这是一组总结查询答案的要点')
##创建代理
reasoner_agent = Agent(deepseek_reasoner_model,
deps_type=ResearchDependencies,
result_type=LifeMeaningStructuredResult,
system_prompt='你是一个有帮助且智慧的推理助手,你擅长思考
如果你被问到一个问题,你会仔细思考,然后回复一个标题、你的思考过程、
一组要点总结和一个最终答案')
result = await reasoner_agent.run('什么是人工智能?')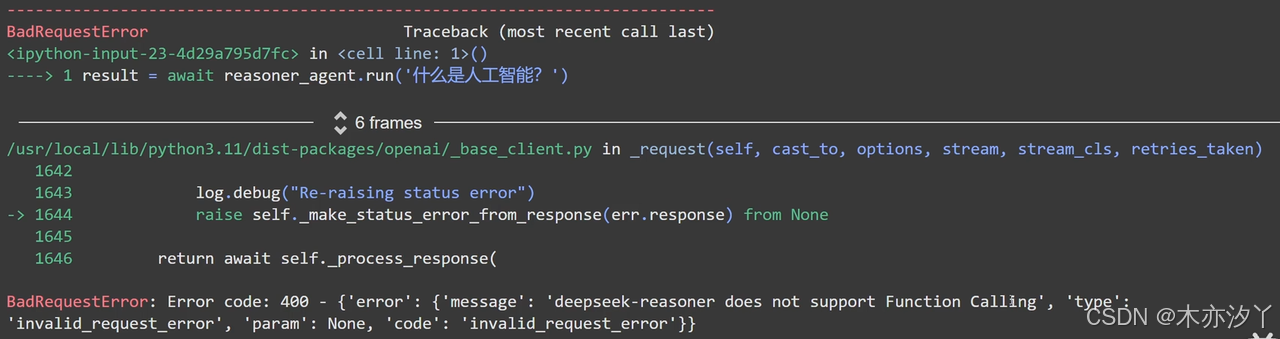
和官方文档描述一致,不支持Function Calling。
方法一、设置第二个LLM帮忙解析并输出
from pydantic_ai import Agent
class LifeMeaningStructuredResult(BaseModel):
title:str=Field(description='这是一个顶级的Markdown标题,涵盖查询的主题和答案,以#开头')
answer:str=Field(description='这是提供查询和问题答案的主要部分'
bullets:str=Field(description='这是一组总结查询答案的要点')
thinking:str=Field(description='这是一个字符串,涵盖答案背后的思考过程')
##创建代理
reasoner_agent = Agent(deepseek_reasoner_model,
# deps_type=ResearchDependencies,
# result_type=LifeMeaningStructuredResult,
system_prompt='你是一个有帮助且智慧的推理助手,你擅长思考
如果你被问到一个问题,你会仔细思考,然后回复一个标题、你的思考过程、
一组要点总结和一个最终答案')
result = await reasoner_agent.run('什么是人工智能')
from pydantic_ai.models.openai import OpenAIModel
ollama_model = OpenAIModel(model_name='qwen2.5:32b', base_url='http://localhost:11434/v1')
formatting_agent = Agent(ollama_model,
result_type=LifeMeaningStructuredResult,
system_prompt='你是一个有帮助的格式化助手,你从不发表自己的意见
你只是接收给定的输入,并将其转换为结构化结果以返回,'
)
structured_results = await formatting_agent.run(result.data)
print(structured_results.data.title)
print(structured_results.data.answer)
print(structured_results.data.bullets)
print(structured_results.data.thinking)方法二、把推理模型当成一个tool
ORCHESTRATOR_PROMPT="""你是一个协调系统,在专用工具之间间进行协调以产生全面的响应。请遵循以下确切顺序,不要跳过:
一旦你有了搜索信息,总是返回到推理模型进行综合
1.关键词生成
输入:用户查询
工具:推理引擎
操作:生成3-5个搜索关键词/短语
输出格式:{关键词,查询ID}列表
2.搜索执行
输入:来自步骤1的关键词
工具:搜索工具
操作:使用每个关键词执行并行搜索
输出格式:{查询ID,搜索结果[]}列表
3.综合
输入:
- 原始用户查询
- 所有搜索结果
工具:推理引擎
操作:分析和综合信息,如果你需要更多信息,请要求进行更多搜索
输出格式:结构化报告,包含:
- 主要发现
- 支持证据
- 可信度
4.响应格式化
输入:综合报告
操作:格式化为用户友好的响应,包含:
- 清晰的章节
- 引用
- 相关指标
输出:最终格式化的响应
每个步骤都需要验证:
-验证工具输出是否与预期格式匹配
-记录任何失败的步骤以便重试
-保持信息来源的可追溯性
"""@dataclass
class TaskData:
task: str
@dataclass
class SearchDataclass:
max_results: int
class ReportStructuredResult(BaseModel):
title:str=Field(description='这是一个顶级的Markdoown标题,涵盖查询的主题和答案,以#开头')
answer:str=Field(description='这是提供查询和问题答案的主要部分')
bullets:str=Field(description='这是一组总结查询答案的要点')
thinking:str=Field(description='这是一个字符串,涵盖答案背后的思考过程')
from pydantic_ai.models.openai import OpenAIModel
ollama_model = OpenAIModel(model_name='qwen2.5:32b', base_url='http://localhost:11434/v1')
orchestrator_agent = Agent(ollama_model,
result_type=ReportStructuredResult,
system_prompt=ORCHESTRATOR_PROMPT
)
deps = SearchDataclass(max_results=3)
SYSTEM PROMPT="""你是一个有帮助且智慧的推理助手,你擅长思考
如果你被问到一个问题,你会仔细思考,然后回复一个标题、
一组要点总结和一个最终答案"""
@orchestrator_agent.tool_plain
async def get_reasoning_answers(task: str) -> dict[str, Any]
"""获取任何任务的强大推理答案。
Args:
task:用于推理的任务
"""
client = OpenAI(api_key=os.environ["DEEPSEEK_API_KEY"]
base_url="https://api.deepseek.com")
messages = [{"role": "system", "content": SYSTEM PROMPT},
{"role": "user", "content": task}]
response = client.chat.completions.create(model="deepseek-reasoner", messages=messages)
reasoning_content = response.choices[0].message.reasoning_content
content = response.choices[0].message.content
formatted_response = "<thinking>" + reasoning_content + "</thinking>" + "\n\n" + content
return formatted_response
@orchestrator_agent.tool #Tavily
async def get_search(search_data:RunContext[SearchDataclass],query: str, query_number: int) -> dict[str, Any]:
"""获取关键词查询的搜索结果。
Args:
query:要搜索的关键词。
"""
print(f"Search query {query_number}: {query}")
max_results = search_data.deps.max_results
results = await tavily_client.get_search_context(query=query, max_results=max_results)
return results
structured_results = await orchestrator_agent.run(
"请用P中文为我创建一份关于DeepSeekR1-Zero模型中使用的GRPO、RL的的报告",
deps=deps)
print(structured_results.data.title)
print(structured_results.data.answer)
print(structured_results.data.bullets)
print(structured_results.data.thinking)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









