







近日,AI 工程师和技术作家 Andriy Burkov 发布了一份「从头开始写 GRPO 代码」的教程,其中介绍了如何基于 Qwen2.5-1.5B-Instruct 模型构建一个使用 GRPO 的分布式强化学习流程。以下是项目对应的github代码仓:
这篇文章主要从数据格式角度讲解其中的关键模块作用,部分内容来自《丁师兄大模型》
如有问题,欢迎评论区指正
背景知识:
1. 本文将展示如何使用 GRPO 方法构建分布式强化学习(RL)流程,从而可以针对数学、逻辑和编程任务对语言模型进行微调,上述任务的特点在于存在一个唯一且正确的 ground truth 答案,可通过简单的字符串比较轻松加以验证,所以本教程的目标是将通用语言模型 Qwen2.5-1.5B-Instruct 转换为数学问题求解器。
2. GRPO相对于普通的PPO创新点在于省去了critic model的构建与训练,大大节省了内存开销,降低了训练难度。具体来说,它将token粒度上的预期收益(依托critic model预测得到)转变为 nums_generations个输出对应的rewards的均值。
3. 一般做PPO/DPO/GRPO等强化学习训练,关键点分为三部分:
- 输入输出数据与答案标签处理
- loss设置(PPO/GRPO关键点在于rewards model)
- 调参训练
本文也将按照这个结构来分析
一、输入输出数据与答案标签处理
-
项目定义了数据格式,以及模型如何从输出和数据集中提取答案段落。为了确保模型输出格式一致,项目还定义了一个系统提示。该提示指示模型生成包含 < reasoning > 和 < answer > 标签的输出。这一步通过两个函数完成:extract_answer_from_model_output:此函数获取模型的输出文本,并提取 < answer > 标签内的内容;extract_answer_from_dataset:此函数从 GSM8K 数据集中提取预期答案,该数据集使用 “####” 分隔符来分隔答案:
SYSTEM_PROMPT = """ Respond in the following format: <reasoning> ... </reasoning> <answer> ... </answer> """ def extract_answer_from_model_output(text): """ Extracts the value from the last <answer> tag in the text. Args: text (str): The model-generated text containing XML-style <answer> tags. Returns: str or None: The content inside the <answer> tags, or None if no valid answer is found. Explanation: 1. Splits the text on the <answer> tag to isolate content after the tag. 2. Checks if at least one <answer> tag exists in the text. 3. For the last <answer> segment: - Verifies it contains a closing </answer> tag. - Extracts only the content between the tags. 4. Returns None if the answer is empty (just "...") or if tags are missing. """ # Split on <answer> and take everything after the last occurrence parts = text.split("<answer>") if len(parts) < 2: # No <answer> tag found return None last_part = parts[-1] # Extract content up to </answer> if "</answer>" not in last_part: return None answer = last_part.split("</answer>")[0].strip() return None if answer == "..." else answer def extract_answer_from_dataset(text): """ Extracts the answer from the GSM8K dataset examples. Args: text (str): The dataset example text containing a question and answer. Returns: str or None: The extracted answer part after the '####' delimiter, or None if not found. Explanation: 1. Checks if the text contains the '####' delimiter that separates question from answer. 2. If found, splits the text at this delimiter and returns the second part (the answer). 3. The answer is stripped of leading/trailing whitespace. 4. Returns None if no delimiter is present. """ if "####" not in text: return None return text.split("####")[1].strip() - 加载数据集GSM8K,格式化每个示例,包括系统提示和用户提示。

二、Loss设置
在PPO/GRPO中,loss设置的关键在于advantages,而advantages的关键在于rewards的计算,在GRPO中,rewards的计算与之前不同,不再需要用初始化sft后的模型,依靠构造的打分数据集进行fine-tuning,而是简单的通过答案准确性和格式准确性进行打分
1. 奖励模型构建
correctness_reward:这个函数根据生成的答案是否正确来分配奖励。
采用两种方式:精确的字符串匹配和数值等价检查,将模型输出的答案与预期答案进行比较。
完全匹配会获得更高的奖励(2.0),而基于数值等价的匹配会获得较小的奖励(1.5)
format_reward:这个函数鼓励模型遵循所需的类似 XML 的输出格式。
它为生成文本中存在 < reasoning>、</reasoning>、<answer > 和 </answer > 标签提供小额奖励。
## part of correctness_reward
for r, a in zip(extracted, answer):
if r == a: # Exact match case
rewards.append(2.0)
else:
# Try numeric equivalence
r_num = extract_single_number(str(r))
a_num = extract_single_number(str(a))
if r_num is not None and a_num is not None and r_num == a_num:
rewards.append(1.5)
else:
rewards.append(0.0)
## part of format_reward
for response in responses:
score = 0.0
if "<reasoning>" in response: score += 0.2
if "</reasoning>" in response: score += 0.2
if "<answer>" in response: score += 0.2
if "</answer>" in response: score += 0.2
rewards.append(score)
format_scores.append(score)
## combined reward
combined_rewards = []
for c_score, f_score in zip(correctness_scores, format_scores):
# Correctness score range: 0.0 to 2.0
# Format score range: 0.0 to 0.8
# Total range: 0.0 to 2.8
combined_rewards.append(c_score + f_score)2. 优势advantages计算
有了每个completion的rewards之后,advantages就很好计算了!
GRPO对应的advantages计算如下:

简单举个例子:
假设batch_size = 2, num_generations = 3,也就是GRPO模型每次产生三个输出
rewards = tensor([[1.0, 2.0, 3.0], # 样本 1 的 3 个奖励值
[4.0, 5.0, 6.0]]) # 样本 2 的 3 个奖励值
rewards.mean(dim=1) = tensor([2.0, 5.0]) # 样本 1 的平均奖励为 2.0,样本 2 的平均奖励为 5.0
mean_rewards = tensor([2.0, 2.0, 2.0, 5.0, 5.0, 5.0])
std_rewards = tensor([1.0, 1.0, 1.0, 1.0, 1.0, 1.0])
advantages = tensor([-1.0, 0.0, 1.0, -1.0, 0.0, 1.0])最后advantages形状为(batch_size * num_generations,1)
3. 根据目标函数构建loss
DeepSeekMath 的技术报告里给出了 GRPO 的目标函数(省略部分符号细节):

所以这个项目中的grpo_loss也是完全参照这个公式进行复现的,函数中的关键部分如下:
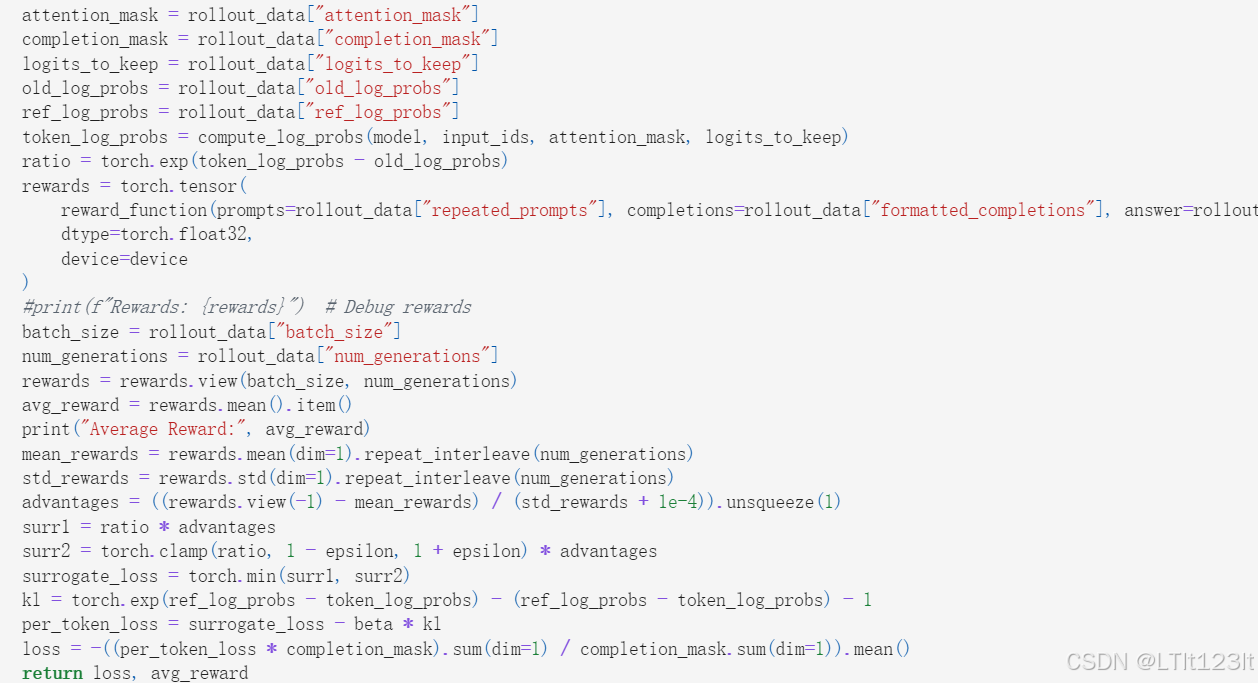
其中old_log_probs, ref_log_probs, token_log_probs都是通过compute_log_probs函数计算对数概率得来的,而这一函数的关键参数在于attention_mask(decoder模型生成需要的mask)以及logit_to_keep(指示了最终需要参与计算loss的token位置)
至于为何在softmax之后要接对数概率:
-
对数概率将概率值映射到对数空间,避免了数值下溢问题。
-
对数概率是单调递增的函数,因此比较对数概率的大小等价于比较原始概率的大小。
per_token_loss = surrogate_loss - beta * kl
这里的beta代表对于kl散度参与loss更新的惩罚系数
最后loss在(batch_size * num_generations,)维度上进行求和并平均。
三、调参开训
- num_iterations=1:从当前策略模型创建新参考模型的外部迭代次数。一次迭代是指在整个数据集上执行一次通过。
- num_steps=500:训练循环将执行最多 500 步,每个步骤处理一批样本。
- num_generations=4:对于训练数据中的每个提示词,训练器将生成4个不同的完成结果。如果你的 GPU 的 VRAM 较少,请减少此数字。
- max_completion_length=400:在生成完成结果(序列的 response 部分)时,生成上限为 400 个 token。
- mu=3:对每个batch数据执行的策略更新次数。这里表示每个batch更新三次策略函数。
- epsilon=0.2:GRPO 的 PPO 组件的 clipping 参数。这可以防止策略在单次更新中发生太大的变化。
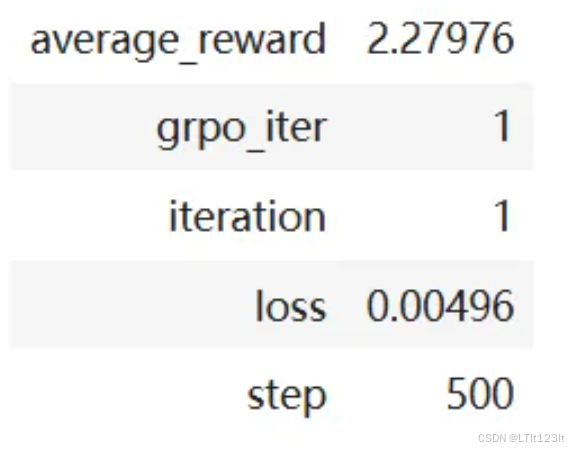
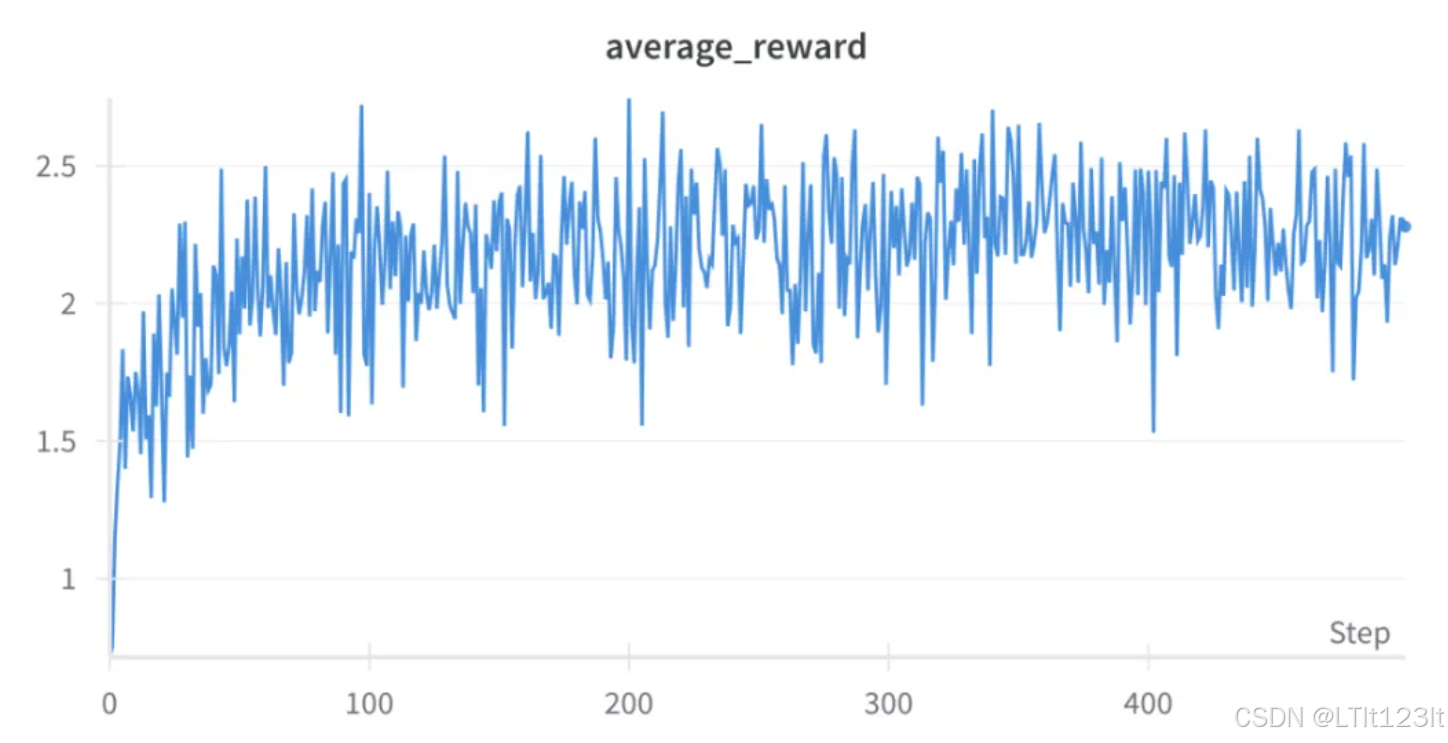
训练后的一些指标如下:

















 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









