








这个专栏围绕着大模型的基本知识点深入浅出,章节之间的联系较为紧密。若在某个环节出现卡点,可以回到大模型必备腔调重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于如果构建生成级别的AI架构则可以关注AI架构设计专栏。技术宅麻烦死磕LLM背后的基础模型。

激活函数
接着上节的内容,数学激活函数用于神经网络中人工神经元的输出,使模型具备非线性。这些函数输入函数然后按照函数的曲线输出对应的数值,输出的数值决定是否激活神经元。它们是神经网络的重要组成部分。在神经网络中,通常使用不同的激活函数,包括:
-
Sigmoid激活函数为输入分配0到1之间的值。它在二元分类情况下有效,但存在梯度消失问题,很少在深度网络中使用。
-
Softmax在多分类问题中,此激活函数将输入转换为跨多类概率分布。
-
Tanh激活函数将输入映射到-1到1之间的值。它与sigmoid函数类似,它生成以零为中心的结果。
-
ReLU将负输入调整为零,并将正输入传输至自身。由于其简单性和有效性,它经常被用于深度神经网络。
激活函数的选择在机器学习中价值百万美元,那么如何选取合适的激活函数。起手式可以是基于ReLU的激活函数,因为经验证明它这个家族几乎对于所有的任务都非常有效。若任务是二分类,则选择S型激活函数,对于多类分类,则选择Softmax的激活函数,因为它输出每个种类的预测概率。
在卷积神经网络中,激活函数可以基于ReLU来提高收敛速度。而某些架构需要特定的激活函数,例如循环神经网络和LSTM利用σ函数和tanh函数。

Massive Activations

这个统计图x轴为Token序列,y轴位每个Token的向量维度,z轴位触发激活函数的次数。例如llama为5120维,mxtral为4096维。图中在LLAMA2(2100和4743)两个维度中固定触发激活函数。
上图则展示了大型语言模型中观察到的一种现象,称为“Massive Activations 大激活”。其特点是很少数的激活值明显活跃于其他的激活,有时候高于其他激活100,000倍以上。通过分析,在模型中的大部分中间层中存在这种现象,且保持恒定值。它出现在最初的层中,并在最后几层中开始减少(下图)。

那么这些激活中涉及的维度是什么,从特征向量的维度,大量激活始终存在于极少特定的维度。站在输入序列的角度,根据大量激活出现的位置在不同的大模型类型中代表不同的含义:
-
仅起始令牌。型号包括LLaMA2-13B、MPT和GPT-2。
-
起始标记和第一个“强”分隔符标记(即“.”或“\n”)型号包括LLaMA2-7B 和LLaMA2-7B-Chat。
-
起始标记、分隔符标记(例如“.”、“\n”、“’”或“,”)以及某些弱单词标记语义(例如“and”、“from”、“of”或“2”)型号包括LLaMA2-70B、Mistral-7B、Mixtral-8x7B、Falcon-40B 和 Phi-2。
实验证明“大激活”这种现象在各种LLMs中广泛存在。这表明它不限于特定模型,而是这些模型的共同特征之一。尽管输入数据有所变化,这些大的激活值在很大程度上保持不变。这表明它们不受输入数据的影响,而是作为模型的固有属性存在。大激活充当LLMs中不可或缺的偏置项,它影响着模型的注意力机制,决定一些特定的部分获得更多的关注。

GLU
GLU是Microsoft在2016年提出的,LSTM序列计算上前后依赖不能很好并行,GLU是在CONV基础上加上了Gate的结构,可以实现stack堆叠,效果上比LSTM更好。它的定义涉及到输入的两个线性变换的向量积,其中一个经过σ函数的处理。
GLU 包含以下组件:输入x,神经网络的输入;权重矩阵W和V,用于线性变换的两个权重矩阵;偏置项b和c:用于调整线性变换的偏置;以及采用了σ激活函数。GLU 的定义公式如下:

|
| 观察左侧的图,这种激活单元其实就是将输入分为两路。 一路为原始输入 一路利用σ作为门控(门控的含义上节已经简述)。σ输出为0-1之间,决定和它做点积计算的信息穿透率。 |
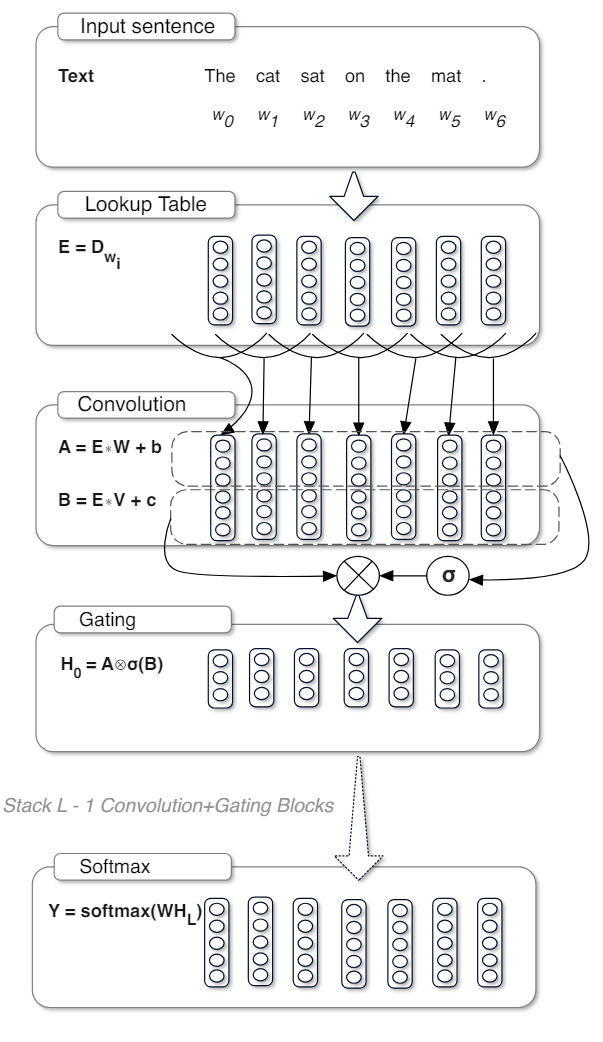
GLU变体是通过在 GLU 的定义中替换激活函数或者引入其他变化来得到的。例如存在以下的一些变体:
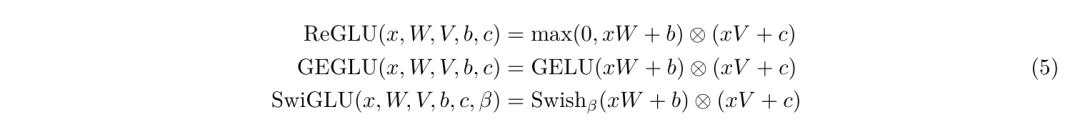
-
ReGLU:使用ReLU激活函数替代GLU中的σ激活函数。
-
GEGLU:使用GELU激活函数替代GLU中的σ激活函数。
-
SwiGLU:使用Swish激活函数替代GLU中的σ激活函数,且引入额外的参数 β。

FFN
前馈神经网络 (FNN) 是一种人工神经网络,其中信息仅在一个方向上移动,从输入层经过任何隐藏层,最后到达输出层。这是最简单的人工神经网络。网络中不存在循环或环路。“前馈”指的是单元之间的连接不形成循环,这与RNN不同。
这种简单的设计使它们非常适合需要简单、单向数据处理的任务,包括模式识别和预测建模。当然FFN的变种很多。下图为其中一种,输入x被放大经过ReLU的激活函数之后再次被压缩回原来大小。

在实际运用过程中,它的FFN层中的第一个线性变换和激活函数会被不同的函数和形态替换,也因此产生了很多变体,尤其是和各种GLU的结合。
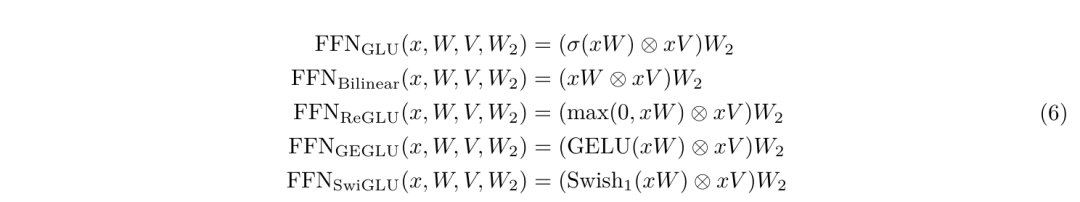
下面是不同变种之间的指标对比:


Swish GLU
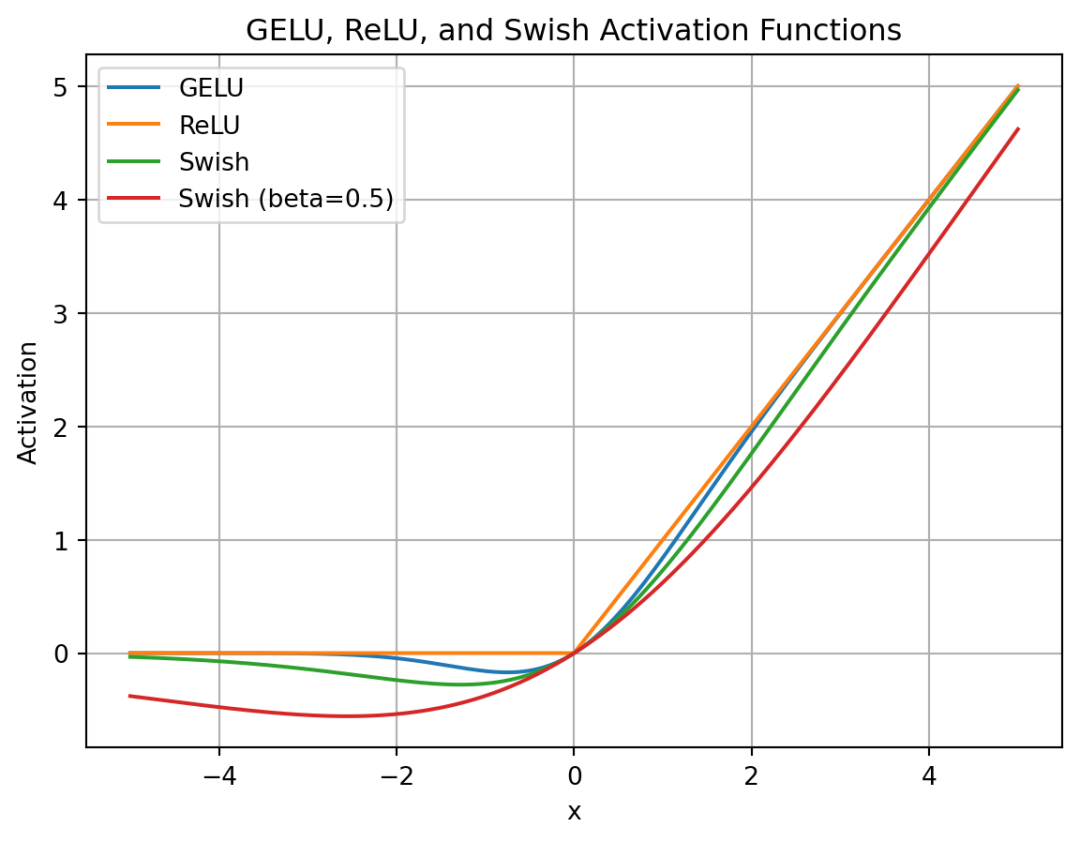
SwiGLU在大模型中运用十分广泛,它是Swish和GLU激活函数的组合,它采用Switch激活函数替换掉GLU模块中的σ激活函数。
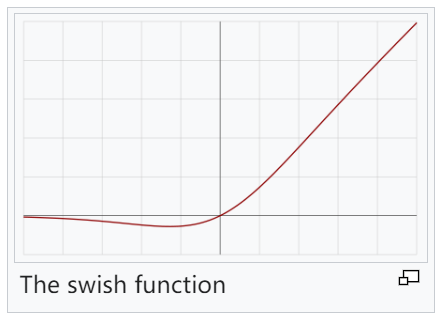
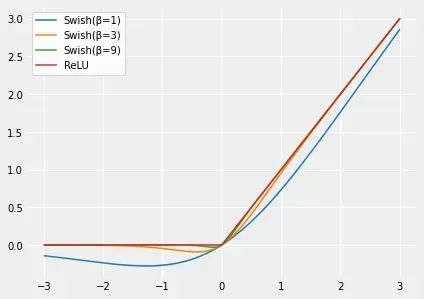
Swish是Google研究人员在2017年提出的一种非单调激活函数。Swish已被证明在许多应用中比ReLU表现更好,尤其是在深度网络中。Swish的主要优点是它比ReLU更平滑,可以带来更好优化和更快的收敛。
|
|
|
|
| 随着β值的增加,Swish相似性变得更接近ReLU。Swish可以粗略地看成在线性函数和ReLU函数之间进行非线性插值的平滑函数。β可以设置为可训练参数,则插值程度由模型控制 |

与其他激活函数相比,SwiGLU 的主要优点是:
-
平滑度:SwiGLU比ReLU更平滑,这可带来更好的优化和更快的收敛。
-
非单调性:SwiGLU是非单调的,这使得它能够捕获输入和输出之间复杂的非线性关系。
-
门控:SwiGLU使用门控机制,使其能够根据接收到的输入选择性地激活神经元。这有助于减少过度拟合并提高泛化能力。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









