









大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。
在过去的十年中,ImageNet预训练的视觉模型显著提高了计算机视觉水平,在各种视觉任务中不断取得突破。ImageNet的成功激发了人们进一步探索从头开始预训练视觉模型的更好方法。最近,预训练的重点已从手动注释数据转移到大规模的网络爬虫图像文本数据。这一转变的一个关键里程碑是CLIP,它利用的图像-文本对的数据比ImageNet大数百倍,在各种任务中提供卓越的性能,并逐渐成为视觉模型预训练的主流方法。
基于这一趋势,人们对探索图像-文本交错的数据的兴趣越来越大,这在互联网上更为普遍。与CLIP中使用的结构化图像-文本对不同,这种交错数据是自由格式和非配对的,规模更大,文本信息更丰富。充分利用这些图像-文本交错的数据对于进一步大规模改进视觉模型预训练是必要的。

一图读懂

这张图片完整的对比了新模型与CLIP的差异。(a)展示了来自CLIP的对比学习框架,而(b)展示了新颖的LCL预训练框架。整体而言,与CLIP相比,LCL可以在训练视觉编码器的时候使用图像和文本交叉的训练数据。值得注意的是这两个框架在训练完毕的时候,可以将其中的text-encoder或者使用的大模型丢弃。
(c)则是展示了多模态的增量训练过程,将训练好的视觉编码器有选择地冻结或微调,然后按照传统的训练模型进行。当然这个过程也是支持图像-文本的交错训练数据。但是,其主要目标是使预训练的视觉编码器和大语言模型保持一致。
研究人员提出这种训练框架的思路在于自然语言处理最近一项研究表明,现代语言模型的成功源于将训练数据集压缩为模型参数。这种压缩学习也适用于多模态领域,只是要压缩的数据从结构化纯文本扩展到图像-文本交错的数据。因为图像是原始像素和非结构化的,通常包含不必要和不可预测的细节。这些细节与高级语义任务无关,应该在压缩学习中丢弃。所以应该调整这种压缩算法,以便于能够适应图像数据的加入。另外文本-图像交错的学习数据的将会更好的提取语义抽象。
整体而言,Latent Compression Learning是一个新的视觉预训练框架,旨在通过最大化因果注意模型输出和输入之间的互信息来进行有效的潜在压缩学习。
两个随机变量的互信息(mutual Information,MI)度量了两个变量之间相互依赖的程度。具体来说,对于两个随机变量,MI是一个随机变量由于已知另一个随机变量而减少的“信息量”(单位通常为比特)。互信息的概念与随机变量的熵紧密相关,熵是信息论中的基本概念,它量化的是随机变量中所包含的“信息量”。
框架的核心思想是通过因果注意模型来实现潜在的信息压缩学习。
因果注意模型通常用于序列预测或生成任务,确保每个输出仅依赖于前面的输入

LCL 时的模型架构概览如上图所示。在交错的图像文本输入序列中,引入特殊标记 <BoI> 和 <EoI>,分别作为图像中视觉嵌入的开始和结束的特殊标记。原文采用 Vision Transformer (ViT) 作为视觉编码器,它输入一系列图像块并输出一系列潜在表示。这最为关键的是损失函数,也就是训练目标的设定。
目前优化目标可以分解为两部分:第一部分为对比学习,就是上图最上面的那根线,对比视觉“潜变量”和先前上下文的语义一致性(对比的对象是<BOI>标识的输出)。第二部分为自回归预测:就是传统文本生成的对比,大白话就是将生成的字符和预期的字符比较。综合两者的差异,反向的微调和训练模型。
这两个训练目标相互补充,学习到的视觉潜变量既保留了可以从先前上下文中预测的信息,又包含了预测后续上下文所需的信息,从而实现了有效的视觉预训练。

潜在压缩学习
自回归语言建模等同于压缩学习。假设 𝑔𝜙 是一个具有可学习参数 𝜙 的语言模型 (LM)。给定一个输入文本序列 𝑥=(</s>,𝑥1,𝑥2,…,𝑥𝑁) ,其中</s>是一个指示文本开头的特殊标记,模型根据前面的上下文输出 𝑦=𝑔𝜙(𝑥)=(𝑦1,𝑦2,…,𝑦𝑁) 预测下一个标记:
而其中x的概率为:

该模型使用NLL损失进行优化,这等于最小化数据分布 𝑝 和模型分布 𝑞 之间的交叉熵:
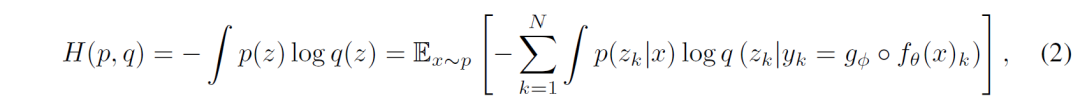
然而在训练的过程中,却出现了塌方。研究人员发现将潜在压缩和最大熵约束相结合,完全等同于最大化模型输入和输出之间的互信息。

因此, 将𝐼使用作为优化目标可以实现潜在压缩,同时通过最大的熵约束避免视觉z的坍缩。压缩𝑧使模型提取有用的信息并丢弃图像的不可预测信息。同时,最大化𝐼要求每个𝑦𝑘能从先前的潜伏𝑧中获得足够的信息来预测 𝑧𝑘 。每个 𝑧𝑘 都应该携带可预测的信息。
这保证了图像表示能够将丰富的语义信息编码,当然这些编码和文本对齐。假设通过图像表示学习到的上述属性是视觉语言预训练所需要的,因此使用方程该方程作为我们的预训练目标。参数 𝜙 和 𝜃 在此目标下共同优化。直观地,视觉编码器 𝑓𝜃 学习通过高级抽象来表示图像,而因果注意力模型 𝑔𝜙 学习压缩数据集的高级抽象。

最终的效果

LCL首次探索了使用交错图像文本数据,进行视觉模型预训练。这篇文章从理论上证明了latent compression等价于最大化因果模型的输入和输出之间的相互信息,并将该目标进一步分解为两个基本的训练任务(对比学习+生成任务),最终得到了更鲁棒的视觉表征。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









