




大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。
过去一年,声称开放的生成式人工智能系统数量急剧增加。但它们到底有多开放?鉴于即将出台的欧盟人工智能法案对开源系统会进行不同进行了不同的监管,生成式人工智能中什么算作开源的问题将变得尤为重要,迫切需要进行实际的开放性评估。
有趣的是研究人员使用一个基于证据的框架,该框架区分了开放性的 14 个维度,从训练数据集到科学和技术文档,从许可到访问方法。通过调查 45 多个生成式人工智能系统(包括文本和图像)。虽然开源一词被广泛使用,但许多模型只是“开放权重”,许多模型的拥有者并没有提供完整的有关训练和微调数据的信息来进行科学、法律和监管审查。
本次的研究调查产生了40个被描述为“开源”或“开放”的文本生成大模型。使用上述的评估框架检查每个系统的开放性,并按开放性分数对系统进行排名。作为参考,我们还添加了ChatGPT。
的确从业人员在选择“开源”大模型的时候,需要考虑很多维度。虽然本次研究,小编私下认为评估模型类型还是不够多,尤其是打分规则的设计值得商榷。但是它最大的贡献在于提出了一套基本的评估标准(方向),这些方向对于企业在进行模型选择的时候能够提供决策依据。为后面大模型使用涉及的应用适配、维护升级以及商业风险都能够提前进行评估。当然还少考虑了免费的因素。!
例如:BloomZ和 Llama均不会通过pypi等有索引和版本控制的公共代码存储库以软件包形式分发模型。相反,两者主要用于本地部署。BloomZ可通过 Petals API获得,而Llama的API仅在注册后可用。
这些模型在许可方面也有所不同。BloomZ有两个相关许可证。其源代码是Apache 2.0,这是OSI批准的开源许可证,而模型权重是在负责任的AI 许可证 (RAIL)下发布的。Llama 2是在Meta自己的社区许可证下发布的。这两个许可证都旨在限制有害用例,但它们在实现模型输出的表示方式上存在一个关键区别。RAIL规定用户不得“在未明确且清晰地声明文本由机器生成的情况下生成内容”,而Llama规定用户不得“表示Llama 2输出由人类生成”。
随着框架可以深入研究生成式AI系统的细节,BloomZ实质上算是开源状态,而Meta的Llama最多是开放权重,并且在几乎所有其他方面都是封闭的。Llama在所有当前可用版本中都是一个典型的例子,该模型声称开放性的好处在于模型权重。
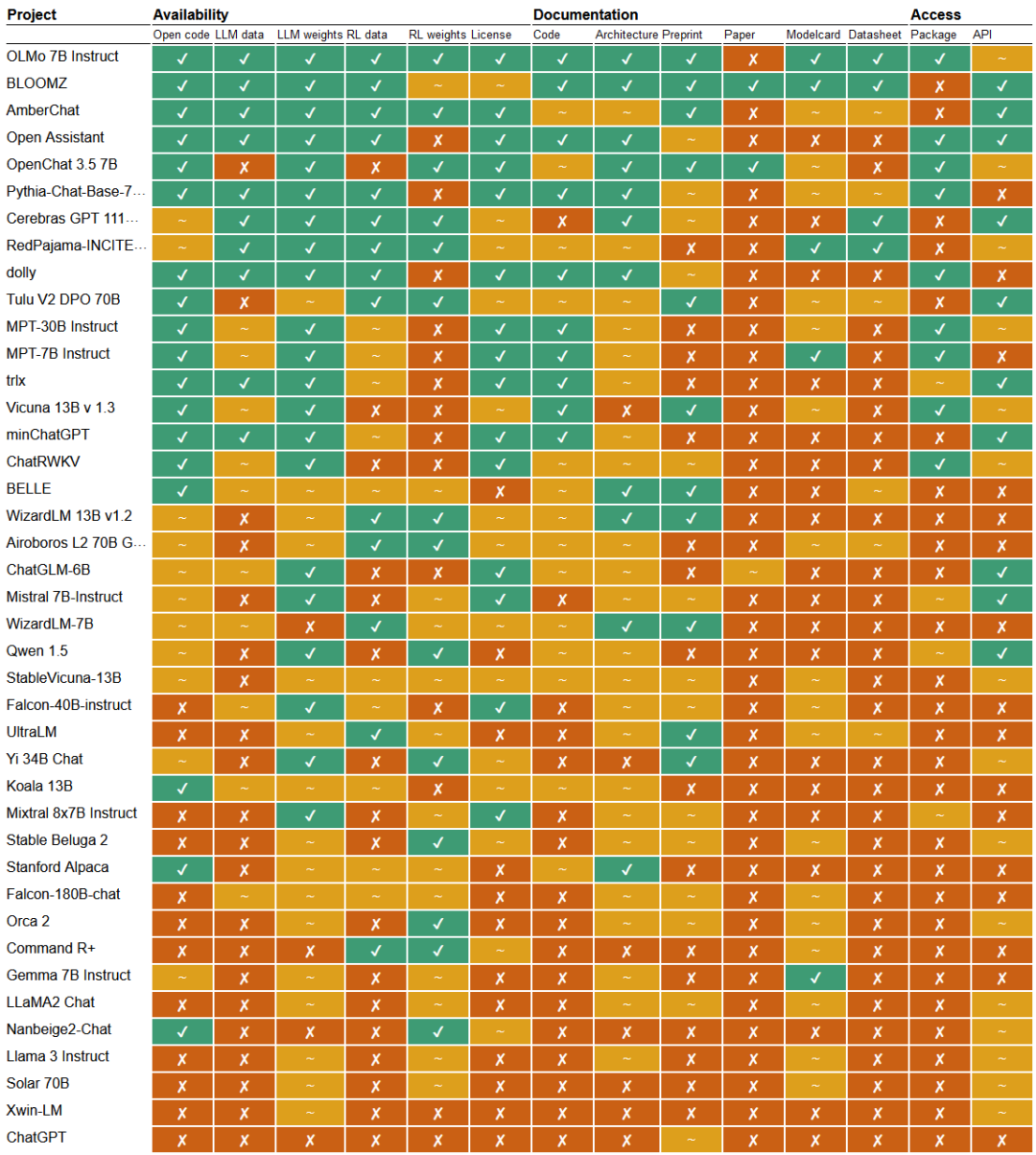
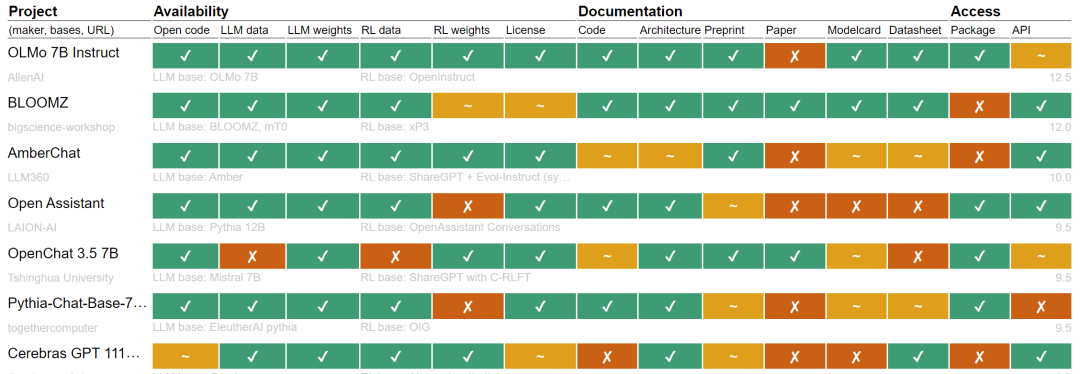
每个单元都记录了一个三级开放性判断(︎ ✔开放、~ 部分或✘封闭)。其中✔︎为 1,~为0.5,✘为0分。请注意,RL可能是指RLHF或其他形式的微调
从上图可以观察到两种广泛的工作方式。一种是AllenAI的OLMo Instruct、BloomZ和LLM360的AmberChat等系统中所见的广泛开源方法,这些系统正在接近完全开放状态并位居开放排行榜榜首。这些系统背后的组织竭尽全力提供训练数据、代码、训练管道和文档。
大量系统(后三分之一)只提供模型权重,但很少或根本不分享有关其系统其他部分的细节。这些系统最好被称为开放权重,而不是开源。
值得注意的是,所有大型商业参与者——Meta、Google、Cohere、Microsoft和Mistral——都处于较低的排名,许多以它们为基础的替代方案也是如此。文本生成器的当前开放状态是混合的。存在一些非常开放的系统,但最著名的模型只是开放权重。许多系统很少共享有关指令调整步骤或元提示技术的信息。用于训练和微调的数据集和方法很少被共享或披露。系统、数据和代码文档通常不完整,缺乏学术严谨性。
训练数据缺乏开放性尤其令人担忧。<小编认为也是合理,毕竟数据才是真正的资产>,下半部分的大多数模型没有提供任何有关数据集的详细信息,除了通用的描述符。

上图为图像生成,与文本生成相比,大模型要少得多。目前可用的图像数据集相对较少,文本转图像生成器在机器学习架构方面也有所不同<可以移步了解!>。
与基于证据的开放性评估最相关的是文本转图像生成器如何实现跟踪合成图像来源的方法,以及设置防止创建不良内容的护栏。一些系统使用水印来实现某种形式的来源跟踪。对于审核,文本转图像系统通常依赖于及时审核的形式,通常是文本过滤或分类。这种来源和安全措施的状态并不总是有记录的。鉴于各种文本转图像的特色,评估框架的各个维度都做相应的调整。
在开放性、透明度和文档方面,Stable Diffusion脱颖而出。其他一些评估系统都是建立在Stable Diffusion的各种模型之上或对其进行了微调。其他一些系统仅是开放权重的。Open AI的DALL-E完全闭源。
其实开放性并不是解决文本生成器的科学和伦理挑战。开放数据不会减轻轻率部署大型语言模型的有害后果,也不会减轻从互联网上抓取所有公开数据的可疑版权影响。然而,开放性确实使原创研究成为可能,包括努力构建可重复的工作流程和理解指令调优LLM架构的基本原理。开放性还实现了制衡,培养了对数据及其管理以及模型及其部署的问责文化。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









