







Hugging Face 宣布发布Transformer 4.42,该版本为流行的机器学习库带来了许多新功能和增强功能。此版本引入了几个高级模型,支持新工具和检索增强生成 (RAG),提供 GGUF 微调,并整合了量化的 KV 缓存,以及其他改进。
随着Transformer 4.42的发布,包括Gemma 2、RT-DETR、InstructBlip 和 LLaVa-NeXT-Video在内的新模型的发布也使其更加值得关注。下面就一起看下这些新的更新。
Gemma 2 模型系列由 Google 的 Gemma2 团队开发,这些模型在 6万亿个代币上进行了训练,并在语言理解、推理和安全方面的各种学术基准中表现出卓越的表现。在 18 个基于文本的任务中,它们在 11 个任务中的表现优于类似大小的开放模型。
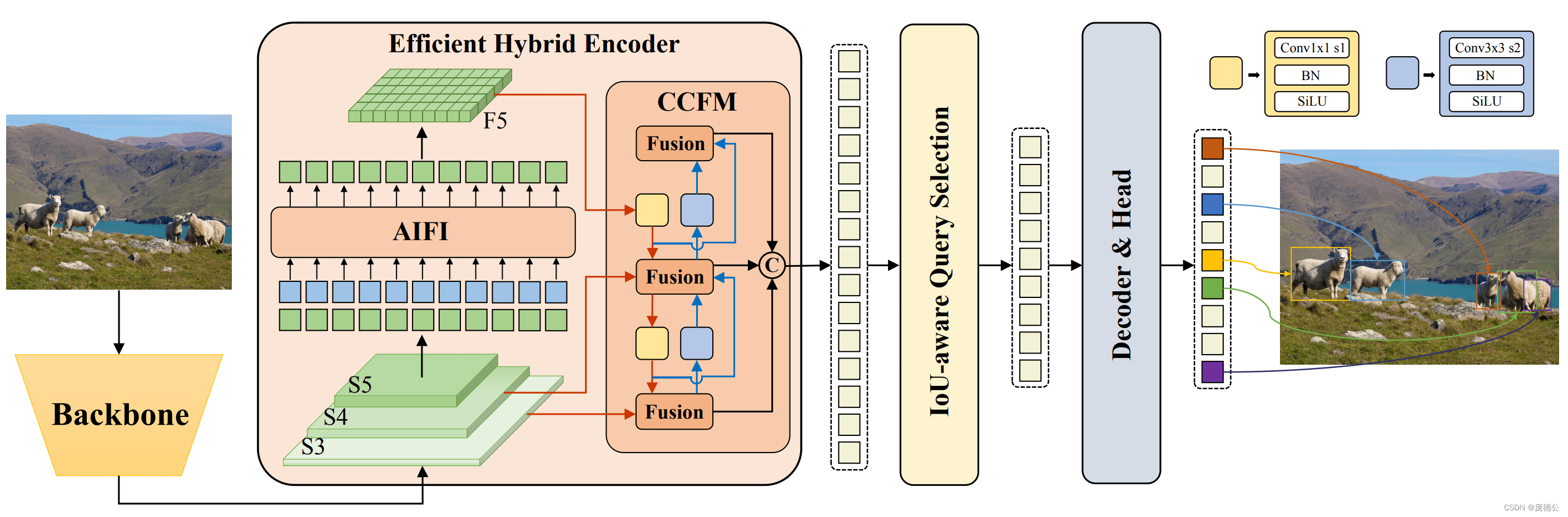
RT-DETR,即实时DEtection Transformer,是另一个重要的补充。该模型专为实时对象检测而设计,利用 transformer 架构快速准确地识别和定位图像中的多个对象。它的发展使其成为目标检测模型的强大竞争对手。
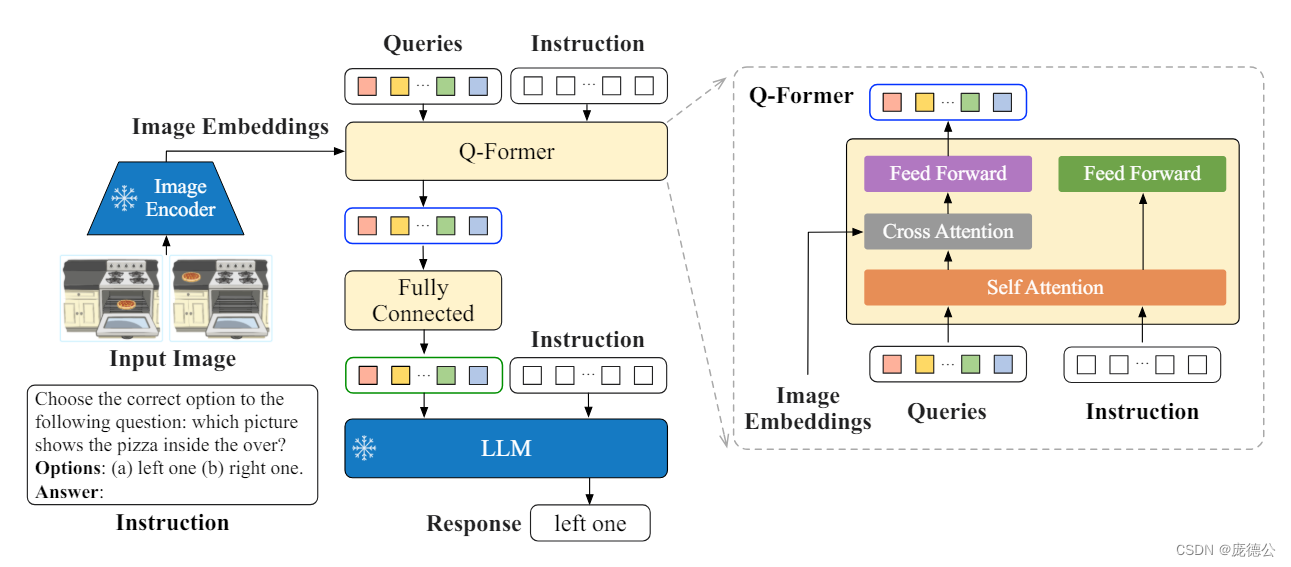
InstructBlip使用BLIP-2架构增强了可视化指令调优。它将文本提示馈送到 Q-Former,从而实现更有效的视觉语言模型交互。该模型有望提高需要视觉和文本理解的任务的性能。
LLaVa-NeXT-Video通过合并视频和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3311
3311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









