






 Jina AI发布开源向量模型jina-embeddings-v2,支持8192个token的输入长度,突破长文本向量瓶颈。该模型提供API免费试用,包含10,000 tokens,作为OpenAI API的低成本高性能替代方案,适用于RAG系统。立即访问https://jina.ai/embeddings/获取API密钥。"
106252391,7039348,JavaScript正则表达式大全,"['javascript', '正则表达式', '验证']
Jina AI发布开源向量模型jina-embeddings-v2,支持8192个token的输入长度,突破长文本向量瓶颈。该模型提供API免费试用,包含10,000 tokens,作为OpenAI API的低成本高性能替代方案,适用于RAG系统。立即访问https://jina.ai/embeddings/获取API密钥。"
106252391,7039348,JavaScript正则表达式大全,"['javascript', '正则表达式', '验证']
 2023 年 10 月 30 号,Jina AI 正式发布了 jina-embeddings-v2,是全球首个唯一支持 8K(8192)输入长度的开源向量大模型,今天,我们趁热打铁,为企业和开发者提供 Embedding API,即插即用!
2023 年 10 月 30 号,Jina AI 正式发布了 jina-embeddings-v2,是全球首个唯一支持 8K(8192)输入长度的开源向量大模型,今天,我们趁热打铁,为企业和开发者提供 Embedding API,即插即用!
借助该 API,开发者可以用于改进检索增强生成 (RAG) 系统的效果,用以解决大型语言模型的上下文长度限制、幻觉问题和知识注入问题。
现在我们提供了其 英文版本 的免费 API 试用方案:
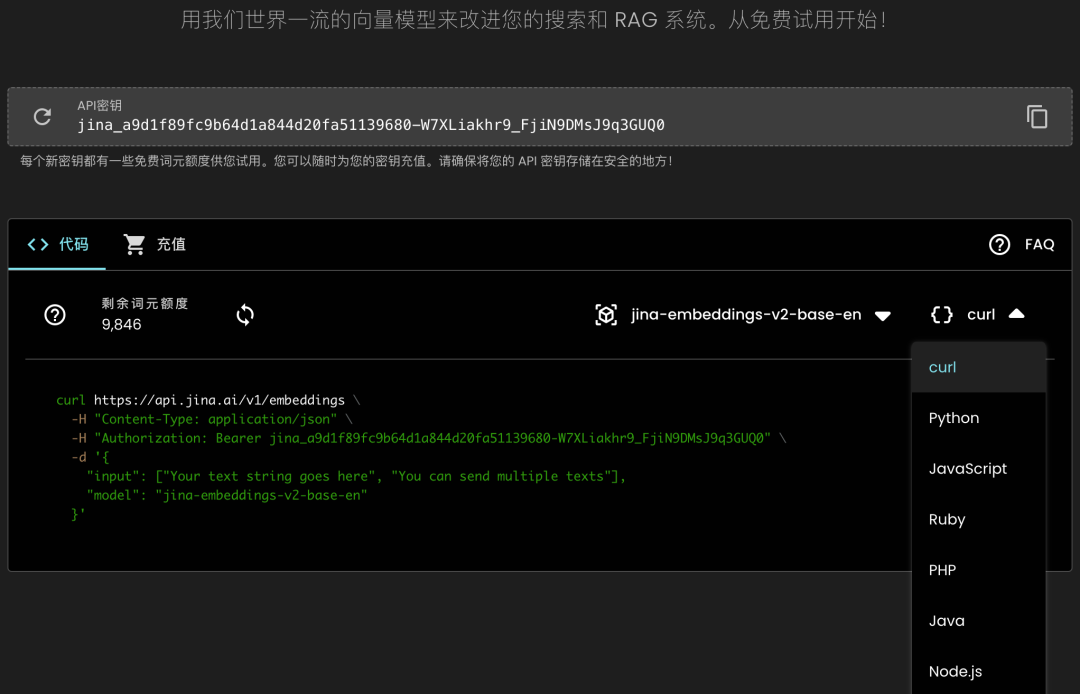
新用户无需注册,打开网页 https://jina.ai/embeddings/,即刻免费获取 API 密钥,该密钥包含 10,000 tokens 的使用额度。
现有模型的限制
现有开源模型的长度限制:当前主流的开源向量模型,如 BERT 和 GPT 系列,受限于最多 512 个 token 的输入长度限制。这意味着长文本必须被截断或分割,从而破坏了文本的完整性和内在的引用关系网络。这种文本切割会直接影响下游任务的效果,如文本分类、问答系统和文本摘要。特别是在信息检索中,我们就只能利用原文档里排名靠前 top-k 的文本片段,送回 LLM 里进行处理,这对于需要全面理解和生成回应的任务来说,远远不够。
商用 8k 长度模型选择受限:目前市面上唯一的商用的长文本向量模型是 OpenAI 的专有模型 text-embedding-ada-002,由于该模型是闭源的,我们无法进行根据具体业务数据做个性化微调。
RAG 系统需要高性能向量模型:通常用于解决大模型的上下文长度限制、幻觉问题和知识注入问题的 RAG 系统,其性能极大依赖于其核心组件——Embedding 模型的效能。如果 Embedding 模型在文本向量的提取过程中表现不佳,则即便 RAG 系统在其他方面设计得当,最终输出也难以达到预期水平。
为什么选择 jina-embeddings-v2
突破长文本向量瓶颈:Jina-embeddings-v2 是目前市场上首个并且唯一支持 8k 输入长度的开源向量模型,有效突破了长文本向量化的技术瓶颈。
更小的维度实现高效的表征:在保持精确表征的同时,jina-embeddings-v2 的向量维度仅为 text-embedding-ada-002 的一半(768 vs 1536),这种高效的向量表征不仅减少了存储需求,同时提高了检索速度。
RAG 应用的最佳选择:jina-embeddings-v2 允许开发者对文本信息进行不同语义颗粒度的完整表示,为长文本提供了完整的语义理解,使其成为优化 RAG 场景下处理长篇文本信息的理想选择。
具体技术细节可以在我们的技术报告里了解:https://arxiv.org/abs/2310.19923
低成本高性能长输入:OpenAI API 的 1:1 替换方案
对于已经在使用 OpenAI Embedding API 的开发者和企业来说,切换到 jina-embeddings-v2 将是非常丝滑的。我们确保了 API 输入输出格式与 OpenAI API 保持完全一致,可以无缝替换 —— 无需修改现有代码,只需将代码中的 openai.com 替换成 jina.ai,就能立刻享受到更低的成本和更长的输入支持。

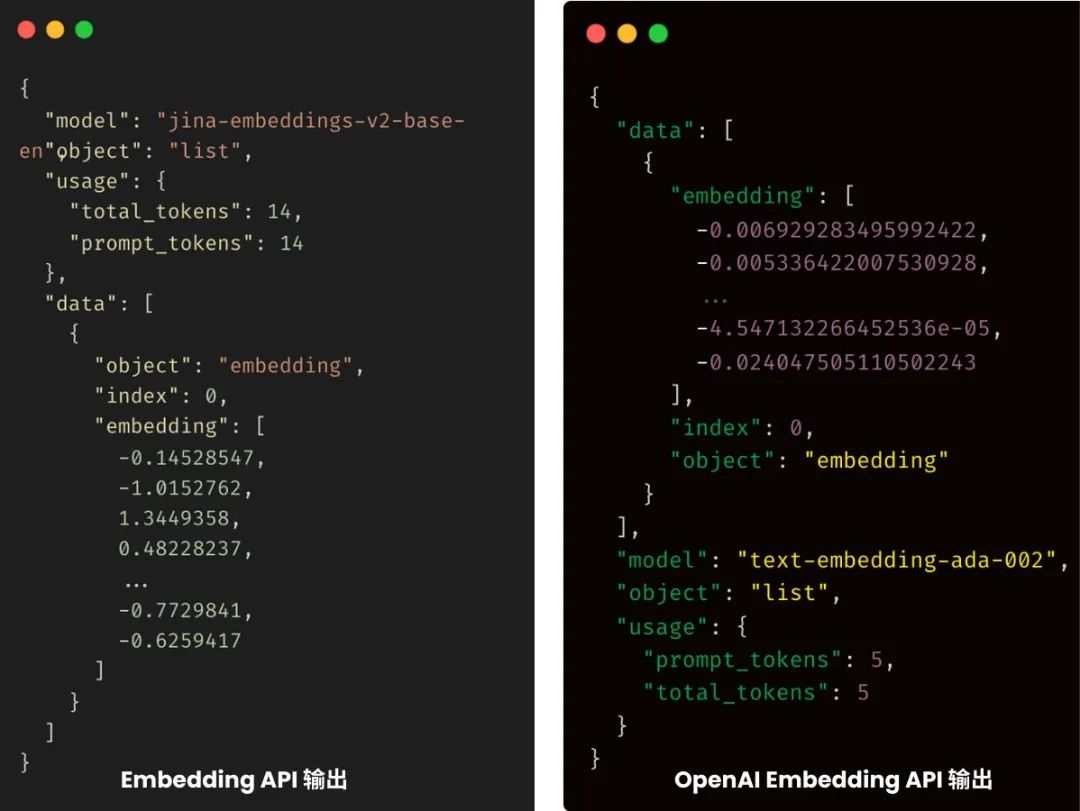
完全兼容的 API,支持众多编程语言,丰富的代码样例 —— jina-embeddings-v2 为你的项目提供了强大的后盾,并且一切简洁明了,开箱即用。所以,不要犹豫,立刻开始免费试用吧!
根据 MTEB 排行榜,与 OpenAI 的 text-embedding-ada-002 相比,jina-embeddings-v2 展现出不俗的实力。值得注意的是,jina-embeddings-v2 在文本分类任务、检索任务、检索重排任务、和文本摘要任务上的得分都超过了 text-embedding-ada-002。
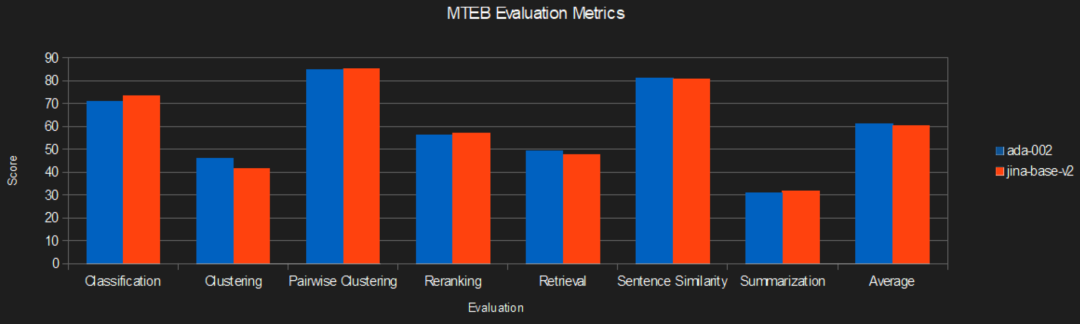
在成本敏感的当下,每分每秒的计算资源都意味着成本。而现在 jina-embeddings-v2,提供比 text-embedding-ada-002 同等甚至更优的服务,但 性价比更高,并且用得越多,省得越多!当数据量攀升,其中的成本差异就转化为了企业和开发者的巨大优势,让他们能够在不牺牲任何性能的前提下,大幅度减少支出。
开局送神装,API 免费试用
为了让你直观体验到 jina-embeddings-v2 的卓越性能,我们提供了 API 免费试用方案:每位用户,无需注册,打开网页即可免费获取 API 密钥,该密钥包含 10,000 tokens 的使用额度。这足够你将我们的模型运用到实际场景中测试,全面检验其性能,确保它能为你的项目带来价值。
访问我们的 https://jina.ai/embeddings/ 以查看更多模型选择、请求参数和返回格式的详细信息。
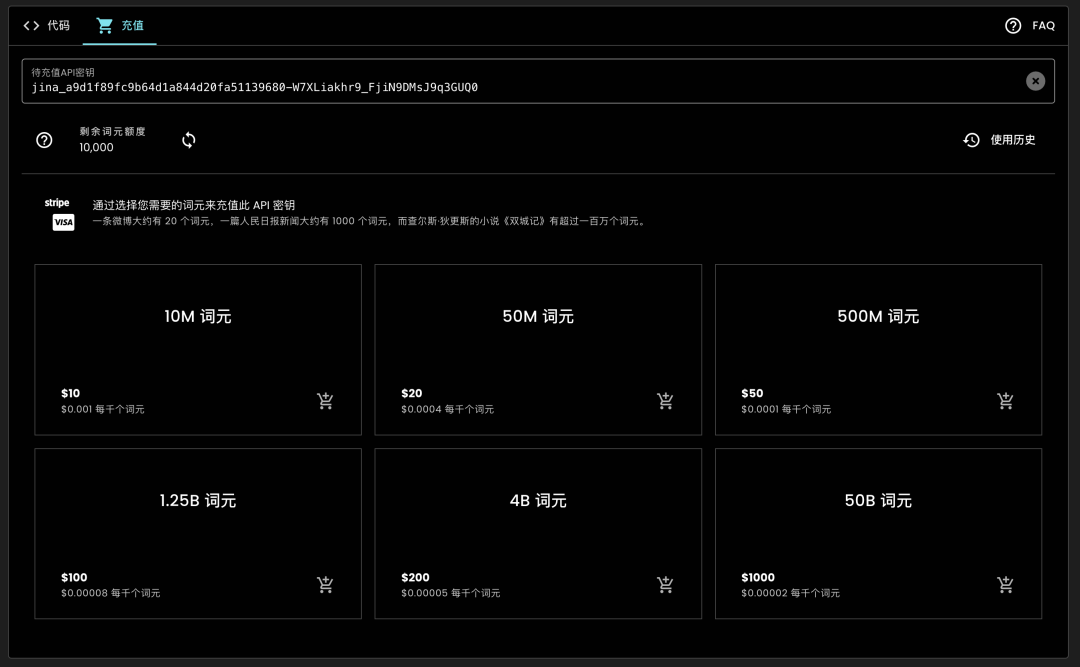
如果您的 API 密钥需要更多 tokens,可以在网页选择“充值”选项,并按需添加 tokens,也可以添加文末小助手,我们的支持团队随时准备帮助您解决任何问题。


















 829
829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









