







在nnUNet中,batch_size和patchsize会在预处理时自动默认设置好,具体可以查看 “nnUNet_preprocessed” 文件夹的.pkl文件:
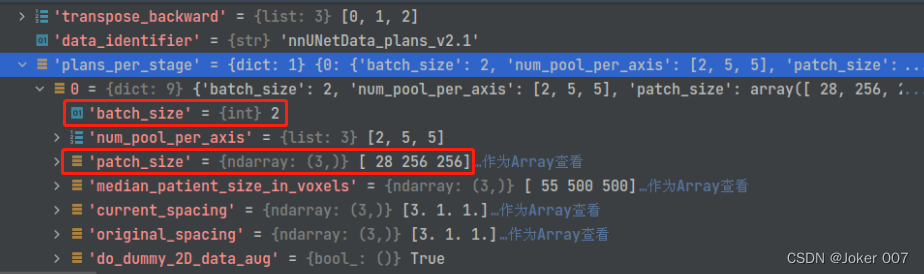
如图是nnUNetPlansv2.1_plans_3D.pkl文件的设置,batch_size=2,patch_size=[28, 256, 256]
 下面修改参数的两种方法:
下面修改参数的两种方法:
方法一、直接修改数据验证和预处理阶段的代码
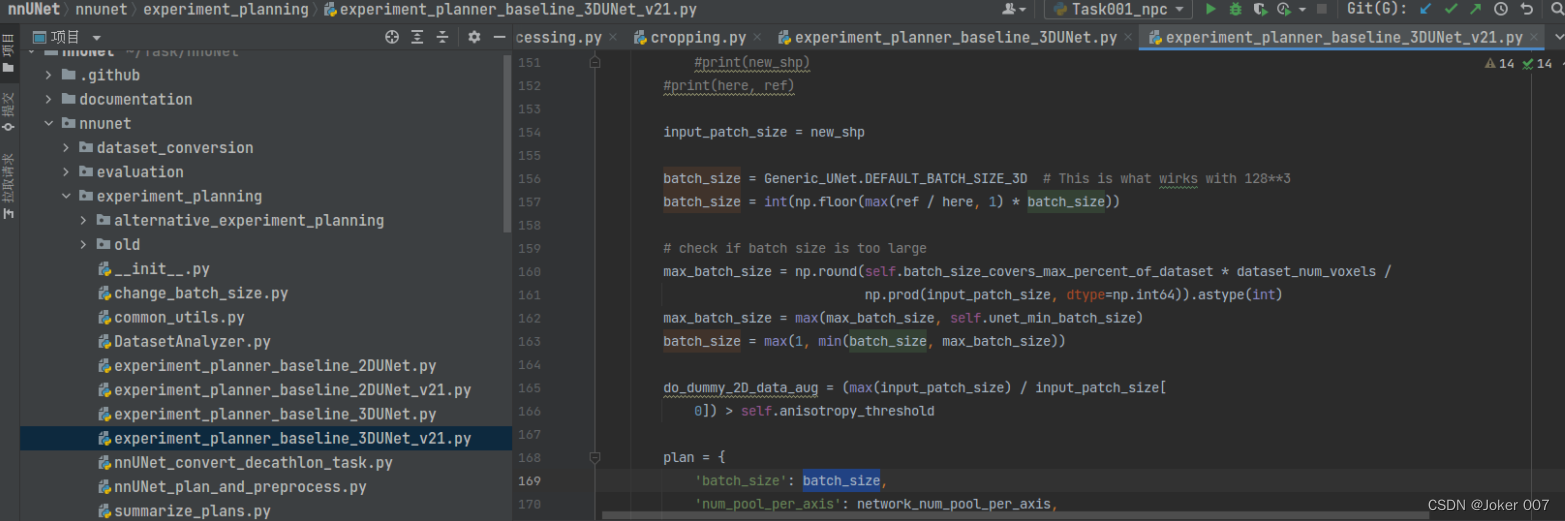
方法二、直接修改.pkl文件
修改.pkl文件的代码如下:
import numpy as np
import pickle as pkl
from batchgenerators.utilities.file_and_folder_operations import *
path = r'/home/amax/Task/nnUnet_data/nnUNet_preprocessed/Task001_npc/nnUNetPlansv2.1_plans_3D.pkl'
with (open(path, 'rb')) as f:
s = pkl.load(f)
print(s['plans_per_stage'][0]['batch_size'])
print(s['plans_per_stage'][0]['patch_size'])
plans = load_pickle(path)
plans['plans_per_stage'][0]['batch_size'] = 4
plans['plans_per_stage'][0]['patch_size'] = np.array((28, 192, 192))
save_pickle(plans, join(r'/home/amax/Task/nnUnet_data/nnUNet_preprocessed/Task001_npc/nnUNetPlansv2.1_ps28_192_192_plans_3D.pkl')) # 路径的保存必须以_plans_xD.pkl结尾才能被识别
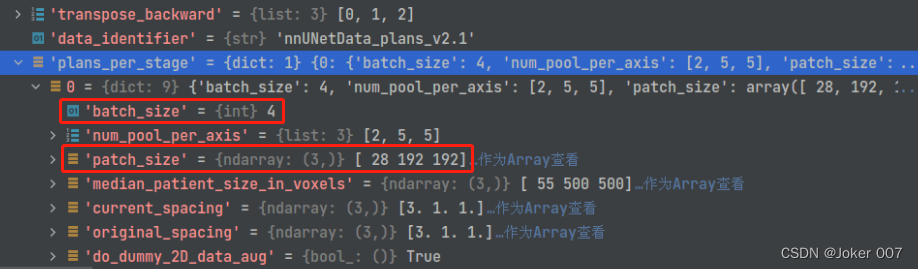
修改后的参数如下:

















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









