







 本文探讨了对比学习在算法实习中的应用,尤其是在推荐系统中的实践。介绍了SimCLR模型的基本步骤,以及如何通过数据增强和对比学习损失来优化模型性能。尽管对比学习在提升模型性能上有显著效果,但其学到的具体内容仍需深入研究。目前的研究主要集中在对SimCLR框架的改进,如数据增强方法和正负样本策略。在推荐系统中,对比学习的引入带来了性能提升,但在图神经网络推荐(如SGL方法)中也遵循相似框架。文章提出了未来可能的改进策略,包括针对任务特定的数据增强方法。
本文探讨了对比学习在算法实习中的应用,尤其是在推荐系统中的实践。介绍了SimCLR模型的基本步骤,以及如何通过数据增强和对比学习损失来优化模型性能。尽管对比学习在提升模型性能上有显著效果,但其学到的具体内容仍需深入研究。目前的研究主要集中在对SimCLR框架的改进,如数据增强方法和正负样本策略。在推荐系统中,对比学习的引入带来了性能提升,但在图神经网络推荐(如SGL方法)中也遵循相似框架。文章提出了未来可能的改进策略,包括针对任务特定的数据增强方法。
前言:前段时间在某厂进行算法实习,主要内容是如何将对比学习引入到推荐算法中去。再次期间我们调研了大量的cv领域的对比学习方法以及少数的对比学习应用在推荐中的文章,虽然也在前人的经验上提出了一些新的东西,但是这些新的东西仅仅只是对对比学习中的一些流程进行了修改,并没有去深入思考对比学习到底学到了什么?他对不管是cv还是推荐具体有什么样的作用?目前通过学习了解到其作用也仅仅是如下几个:1. 对比学习隶属于自监督,本质上输入的样本其实是没有标签的,而通过数据增强操作可以增加样本数量来优化模型性能。2. 通过对比学习损失使相近的样本在投影空间的距离更相近,这样也能提升模型性能。但是对于以上提到的作用仅仅只是在解释使用了对比学习的模型为什么会有性能的提升,但是对比学习究竟学到了什么呢?
目前的一些对比学习方法
目前的对比学习框架最早来源于SimCLR模型,网上有甚多介绍SimCLR模型的文章,此处也不再赘述其模型具体的细节,可以参考张俊林先生的知乎文章。SimCLR总体来说其实是分为三个步骤的,1.数据增强。2.ENCODER。3.对比学习loss。如图所示:
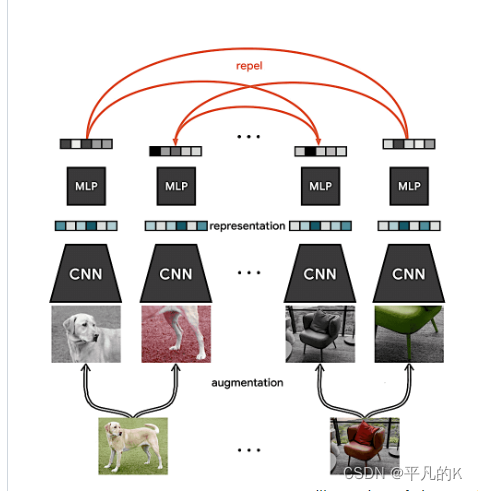
后续也有一些研究在simCLR框架下改进了数据增强方法,以及对比方法loss中的正负样本数量。具体方法请自行查找。
接下来推荐中也用到了对比学习方法,谷歌引用了simCLR框架,并结合推荐数据的特性更改了数据增强方式并提出了一种应用在召回中的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2471
2471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









