






目录
一、Simple Contrastive Representation Adversarial Learning for NLP Tasks
1.1 浅谈对抗
1.2 有监督对比对抗学习
1.3 无监督对比对抗学习
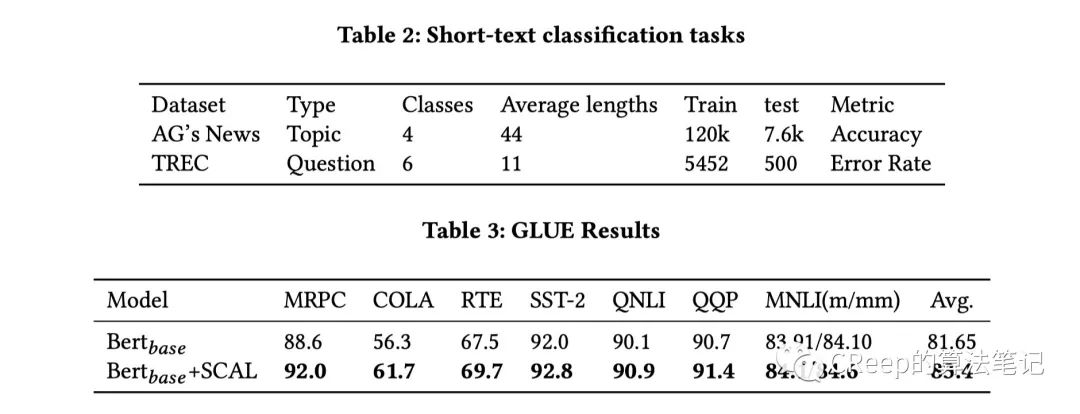
1.4 实验结果
二、PromptBERT
2.1 Motivation
2.2 核心idea
2.3 实验结果
三、总结
今天主要给大家介绍两篇有关对比学习的论文。
对比学习这样的方法在自然语言中备受关注。它使用成对的训练数据增强为具有良好的表示能力的编码器构建分类任务。然而,在NLP任务中,通过对比学习构建学习对要困难得多。之前的工作产生词级变化以形成对比对,但小的变换可能会导致句子含义的显著变化。
一、Simple Contrastive Representation Adversarial Learning for NLP Tasks

论文地址:https://arxiv.org/pdf/2111.13301.pdf
在本文中,对抗训练用于NLP的embedding空间上生成具有挑战性和更难学习的对抗性示例作为学习对。使用对比学习提高了对抗训练的泛化能力。同时,对抗性训练也增强了对比学习的鲁棒性。
1.1 浅谈对抗
通俗的讲对抗训练其实就是在原来的样本中增加一些扰动构生成对抗样本,人看起来几乎没什么区别,但是对于模型来说却很难区分,通过这一通操作模型会变得更加稳定,提高模型的表现,但是会损失模型一定的泛化性。
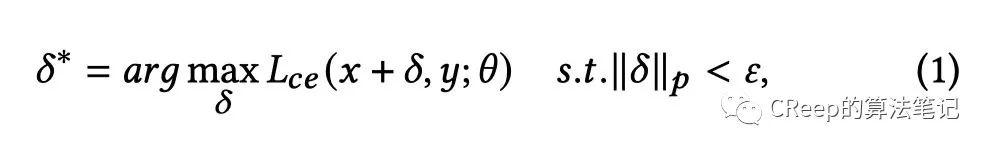
是我们增加的扰动,它不能太大,如果太大的话这样产生的对抗样本和原样本差距就会比较大,就不能达到看起来几乎差不多的效果,它需要满足一定的约束,如式子右边的约束,其中是一个常数,增加扰动的目的是最大化,就是让模型尽量去出错。梯度下降是减小loss,那么反之我们可以采用梯度上升来增大进而求出。
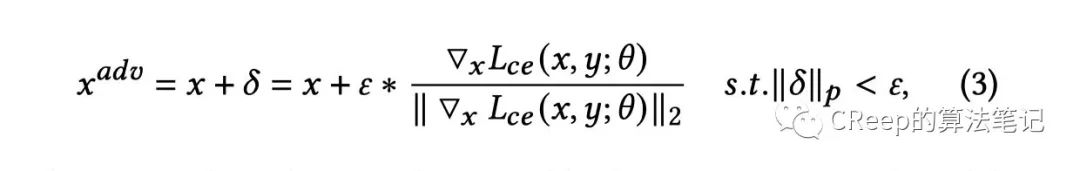
这里可能会有些疑惑,给大家总结下对抗训练流程:
a、在样本x中注入扰动,加入扰动的目的是让越大越好,但是也不能太大,会有个约束
b、每个样本都构造出对抗样本,然后用对抗样本作为数据去最小化整体loss来更新参数(梯度下降,前面讲的梯度上升是为了更新)
c、反复执行a,b两个步骤
在NLP领域我们一般是在Embedding层来增加扰动,具体实现可以参考苏神的代码:
https://github.com/bojone/keras_adversarial_training
本文提出了两种新颖的框架,监督对比对抗学习 (SCAL) 和无监督 SCAL (USCAL),它们通过利用对抗训练进行对比学习来产生学习对。利用监督任务的基于标签的损失来生成对抗性示例,而无监督任务则带来对比损失。
1.2 有监督对比对抗学习
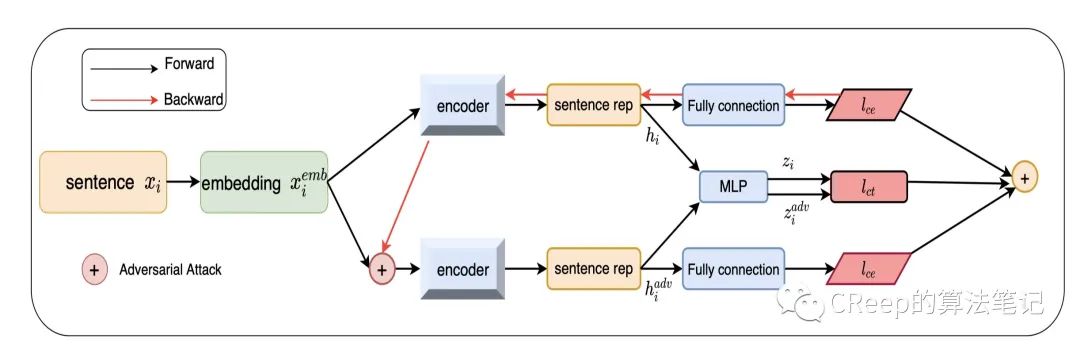
从模型图中其实也很好理解无非就是联合优化三个loss,第一个loss就是样本x经过多层网络后与目标去计算loss(分类loss);第二个loss就是去优化原样本和加入扰动的样本的相似性(对比loss);第三个loss就是加入扰动的样本经过多层网络后与目标去计算loss(分类loss),最后将三个loss相加联合优化。
和传统构造对比样本的方式不同,作者认为之前工作通过数据增强等方式(删除、替换、复制等)构造对比对是在词级层面的,不如在word-embedding等层面上加入扰动。
模型图中第一个loss和第三个loss公式:
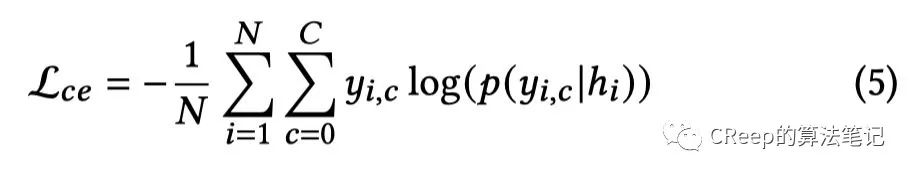
生成扰动:
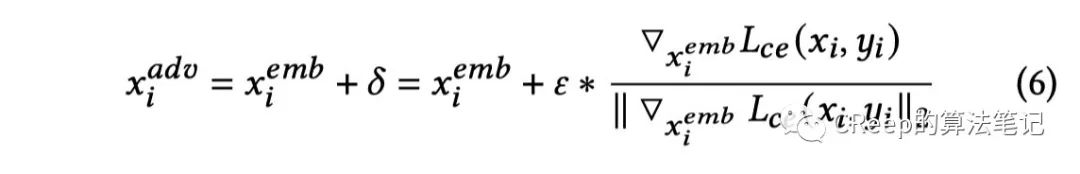
原文实验中 𝜀 ∈ {0.1, 0.2, 0.3, 0.4, 0.5}
对比loss:
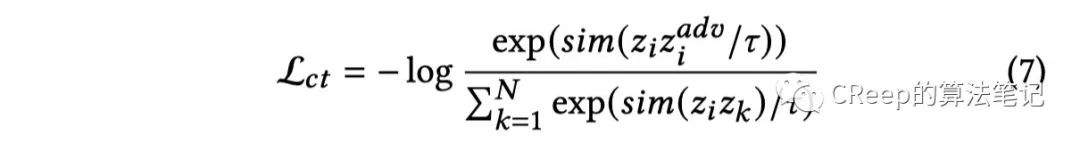
是正温度系数,论文中设置为0.05。
整体loss:
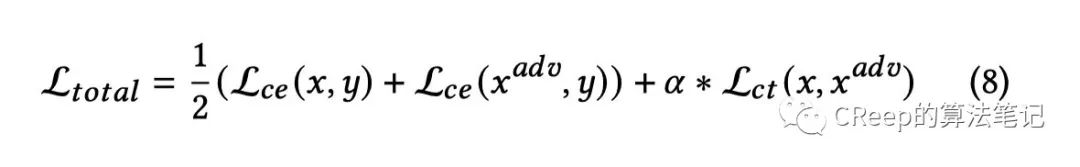
1.3 无监督对比对抗学习
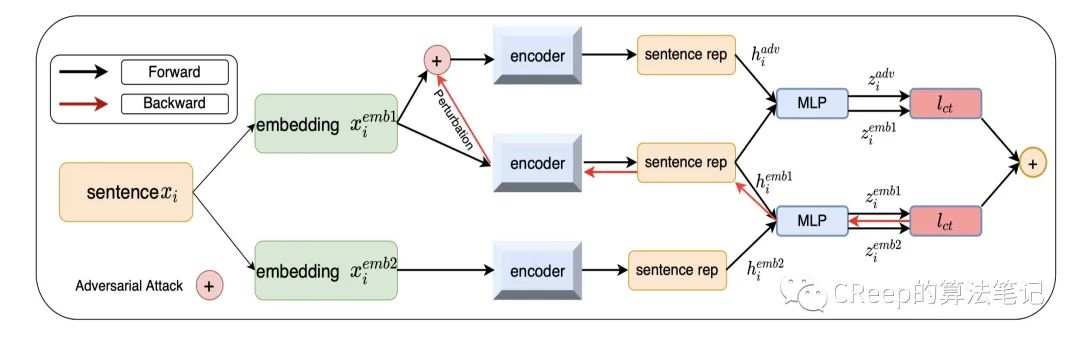
的生成方式参考了SimCSE,就是在Transformer的Feed Forward Network (前馈神经网络)和Muti-head Attention中加入一个Dropout, 这样的话一个样本两次输入到模型中就能得到两个不同的Embedding以此来构造正例。
无监督版本中优化了两个对比loss,一个是原样本和加入扰动的对比loss,另一个通过dropout masks方式构造的正例与注入扰动的样本对比loss。
这里要注意下生成扰动的方式和有监督模型有点不一样,是通过原样本的和通过dropout masks后的联合反向梯度上升来生成扰动的。
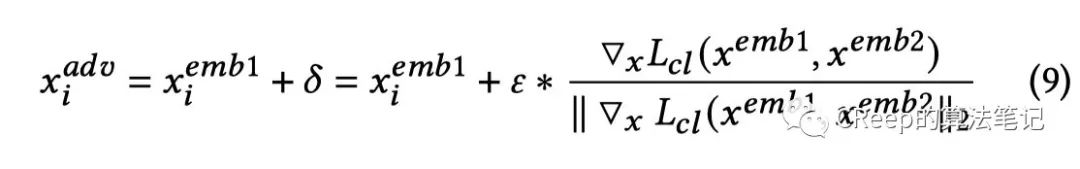
整体loss:

其中𝛼是常数,小于1,控制对比损失的比例。
1.4 实验结果
为了验证所提出框架的有效性,论文中将其应用于基于 Transformer 的模型,用于自然语言理解、句子语义文本相似性和对抗性学习任务。GLUE 基准测试任务的实验结果表明,微调的监督方法优于 BERT 超过 1.75%。在语义文本相似性 (STS) 任务上评估了无监督方法,使用 BERT 获得 77.29%。稳健性在 NLI 任务的多个对抗性数据集下产生了最先进的结果。
二、PromptBERT

论文地址:https://openreview.net/forum?id=7I3KTEhKaAK
2.1 Motivation
基于现有的研究表明,BERT的句向量表示很弱,主要是因为受高频词的影响,BERT整体词向量分布大致呈现圆锥形,高频词会分布在圆锥顶部,而低频词分布在底部,这样去算相识度的话可能会引入分布偏差,高频词之间算相识度得分相对于高频词与低频词之间会高一些,这也就是anisotropy问题。
作者通过研究发现,BERT在句子相似度问题上表现差的原因,其实和anisotropy关系不大,而是因为static token embedding bias 和 低效的BERT layer。比较naive的做法就是去除这次产生bias的词,本文作者通过引入Prompt,然后使用被mask的token来表示句子。
2.2 核心idea
1、引入Prompt,来增强对句子的表示,模板是: “[X] means [MASK]” X是输入的句子,[MASK]是模型将要学习的句子表示。
2、将不同的Prompt模板生成的句子表示进行对比。
作者提出两种方式来表示句子:
第一种是直接使用被mask的hidden vector来表示句子(这里其实我是不太明白,感觉作者可能想要表达的是固定住label,然后算每一个label的概率,取最大的作为预测label)。
第二种是将mask可能对应的top-k个token的语义进行加权求和。
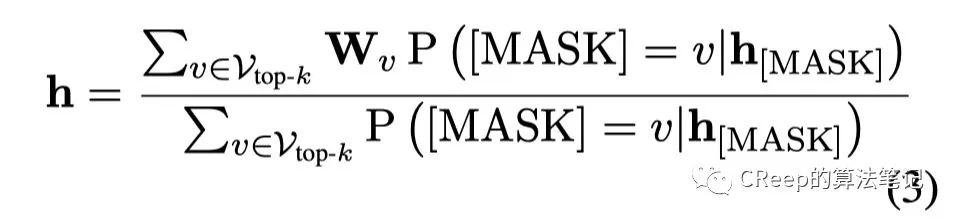
不过由于句子embedding来自静态embedding向量的平均,它仍然受到偏差的影响、以及加权平均使得BERT很难在下游任务中进行微调所以最后作者还是采用第一种方式。
作者采用手动设计不同的Prompt模板,然后去计算它们直接的对比loss。
2.3 实验结果
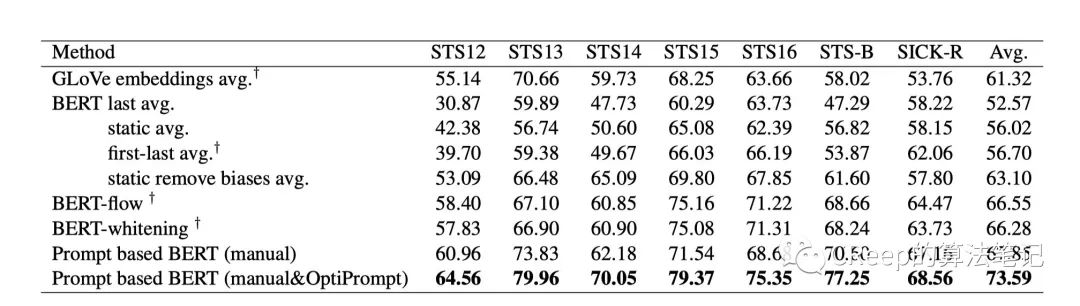
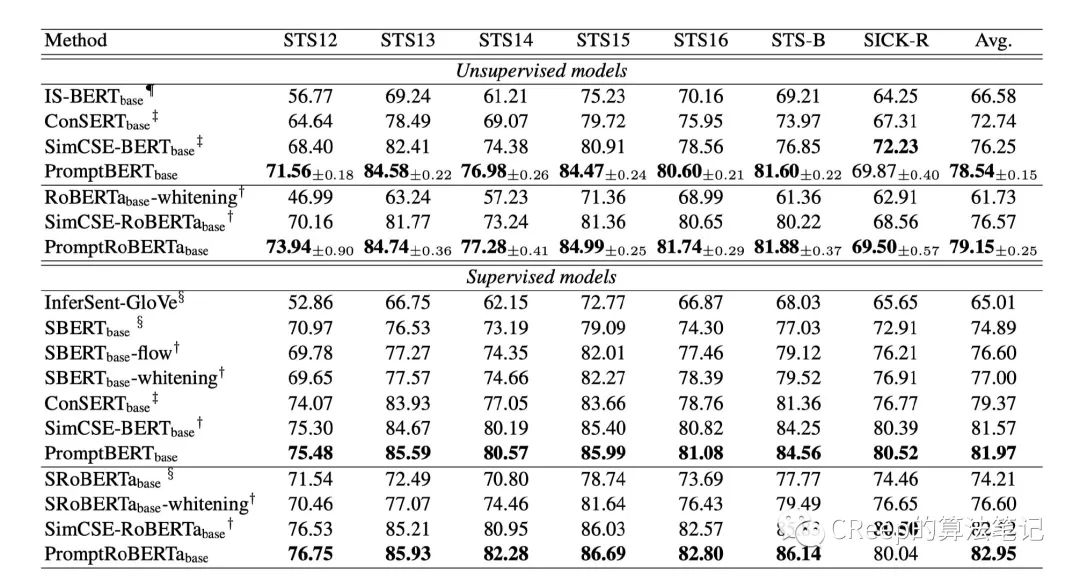
作者做了许多有意思的实验感兴趣的朋友可以去看下原文。
三、总结
第一篇论文总结下就是通过加入扰动构造正样本对从而进行对比学习。
第二篇论文我个人认为不同模板之间的对比只是个辅助任务(通过自己的一些实验不同模板之间的对比提升非常有限,大约一个点不到),主要贡献还是通过构建Prompt模板能够有效的表示句子,前面的文章我们谈到Prompt模板能够帮助预训练模型回忆起自己预训练学到的知识,其实说白了就是将下游任务和预训练任务的统一(近似)。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

- END -


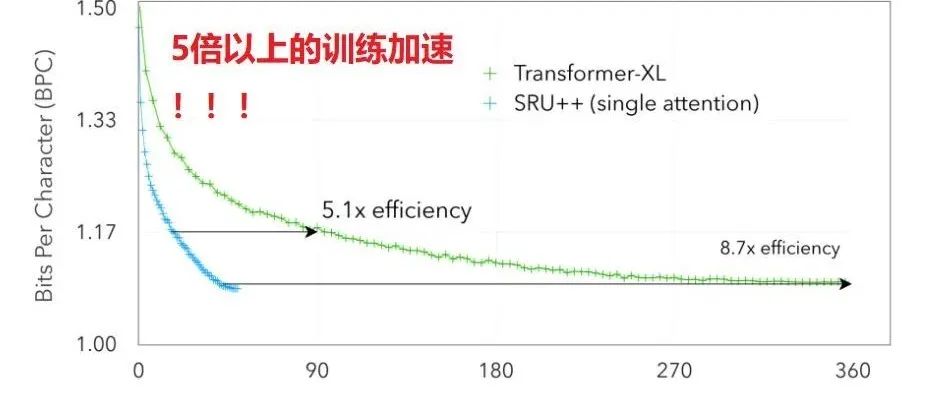
EMNLP杰出论文 | 当注意力遇到RNN,五倍以上训练加速!
KDD 2021 | 谷歌DHE:不使用embedding table的类别型特征embedding


















 1284
1284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









