









视频讲解:视频详解(代码和算法)
论文下载地址:https://arxiv.org/pdf/2203.12119v2.pdf
代码下载地址:https://github.com/KMnP/vpt
论文CLIP-Count(基于文本指导的零样本目标计数)详解(PyTorch)
还记得我们之前讲的“CLIP-Count(基于文本指导的零样本目标计数)”论文的内容吗,如果看过的小伙伴应该知道CLIP-Count论文的作者就使用到了“Visual Prompt Tune”方法训练模型。我们今天来看这篇论文也是因为CLIP-Count提到了这一点。如果迁移微调的模型比较大的话,是不是也可以尝试采用“visual prompt tune”呢,关于这一点大家可以去尝试一下。同样,《Visual Prompt Tune》这篇论文的作者也是认为当前基于模型的全微调对于参数量大的模型并不好,不仅仅是数据集的问题,对于计算资源的要求也很高。
目录
(1)传统微调 vs. 提示调优(Prompt Tuning)
一 提出目的和方法
提出目的
当前预训练模型的主流适配方法需要对整个主干网络参数进行更新(即全参数微调),但是对于向transformer这样参数量比较大的模型来说。将大模型适配至下游任务仍面临显著挑战。最直接(通常也最有效)的适配策略是对预训练模型进行端到端的全参数微调,但该方案需要为每个任务单独存储和部署整套主干网络参数。这对于现代Transformer架构(其参数量远超卷积神经网络)而言成本极高且往往难以实现,例如ViT-Huge(6.32亿参数)与ResNet-50(2500万参数)的体量差异。如何以最优效能比将大规模预训练Transformer适配至下游任务?
提出方法
本文提出视觉提示调优(Visual Prompt Tuning, VPT)作为大规模视觉Transformer模型的高效替代方案。受语言模型高效调优技术的启发,VPT仅在输入空间引入少量可训练参数(不足模型总参数的1%),同时冻结主干网络权重。通过大量下游识别任务的实验验证,VPT相比其他参数高效调优方法展现出显著性能优势。值得注意的是,在不同模型容量和训练数据规模下,VPT在多数场景中不仅超越全参数微调的表现,同时大幅降低了单任务存储开销。
具体方法
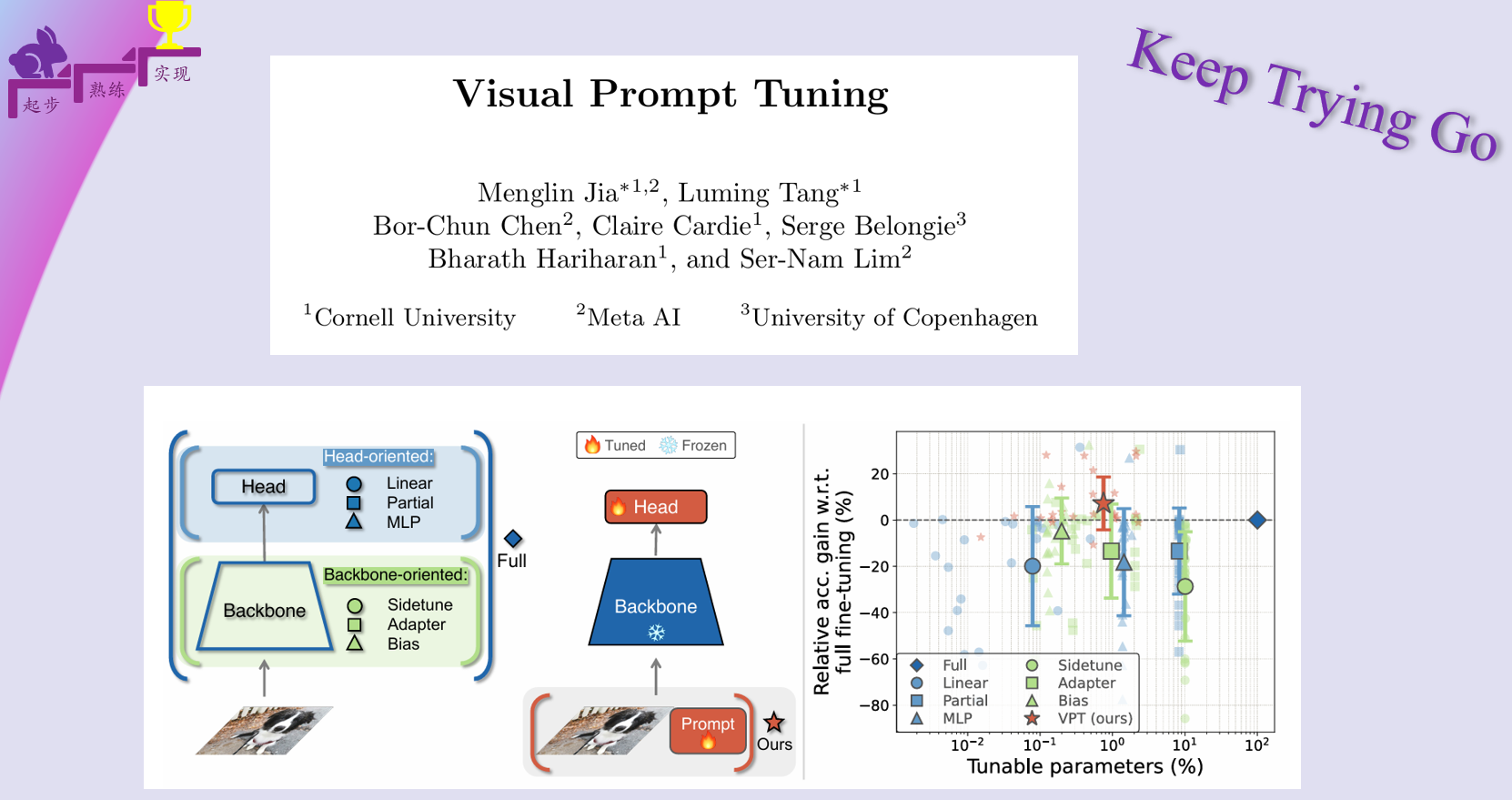
本文探索了全新路径:不直接修改预训练Transformer参数,而是对其输入进行改造。受自然语言处理中提示学习的启发,提出了一种简单高效的视觉Transformer适配方法——视觉提示调优(VPT),如图1(b)所示。该方法仅在输入空间引入少量任务特定可学习参数,同时冻结整个预训练Transformer主干网络。实际操作中,这些新增参数会预置于每层Transformer的输入序列,与线性分类头共同微调。
基于预训练ViT主干网络在24个跨领域下游识别任务的测试表明,VPT不仅全面超越其他迁移学习基线,更在20项任务中优于全参数微调,同时保持单任务存储参数量优势(不足主干参数的1%),如图1(c)所示。这一结果揭示了视觉提示的独特优势:相比NLP领域提示调优仅能在特定条件下匹配全微调性能,VPT在少样本场景表现尤为突出,且优势随数据规模扩大持续保持。此外,VPT对不同规模(ViT-Base/Large/Huge)和架构(Swin)的Transformer均具竞争力。
二 整个方法
ViT基本结构

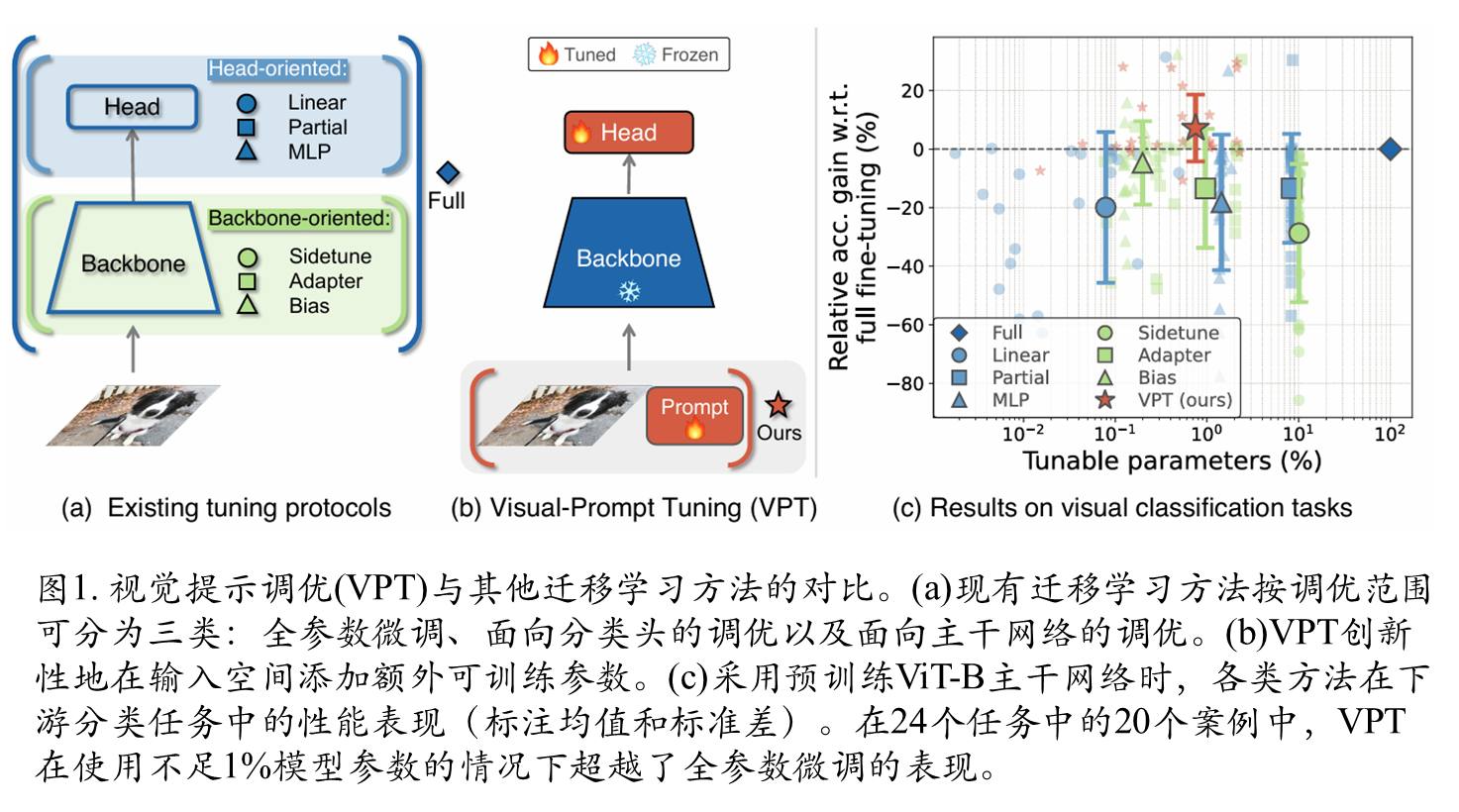
VPT方法
给定一个预训练的Transformer模型,在Embed层之后的输入空间中引入一组维度为 dd 的连续嵌入,即提示(prompts),数量为 p。在微调过程中,仅更新任务特定的提示,Transformer主干保持冻结。根据所涉及Transformer层的数量,该方法有两种变体:VPT-SHALLOW和VPT-DEEP。


注:其中“橙色”表示可学习参数,“青色”表示冻结的参数。
NLP中的提示词和VPT中提示词进一步理解
(1)传统微调 vs. 提示调优(Prompt Tuning)
- 传统微调:需要更新整个模型的参数(全参数微调),为每个下游任务保存独立的模型副本,成本高昂。
- 提示调优:
- 冻结模型参数,仅通过设计或学习提示词来调整模型行为。
- 提示词是插入输入文本中的额外标记(tokens),用于“唤醒”模型对特定任务的推理能力。
- 参数高效:仅需优化少量提示词参数(或无需优化,手工设计)。
(2)提示词的工作方式
- 手工设计提示(Hard Prompt):
例如,在情感分类任务中,输入句子后添加提示词:
"这部电影很棒。总体情感是[MASK]。"
模型根据上下文预测[MASK]位置应为“正面”或“负面”。 - 可学习提示(Soft Prompt):
将提示词视为连续向量(而非具体单词),让模型去优化。- 例如:在输入前添加若干可学习的“虚拟token”嵌入,模型通过这些隐式提示调整输出。
| 维度 | NLP提示词 | 视觉提示(VPT) |
|---|---|---|
| 输入形式 | 文本序列(单词或虚拟token) | 图像块序列(可学习的提示嵌入) |
| 参数类型 | 词嵌入或连续向量 | 视觉Transformer输入空间的连续向量 |
| 插入位置 | 文本开头/中间(如[MASK]) | 每层Transformer的输入序列头部(预置) |
| 优化方式 | 手工设计或端到端学习 | 端到端学习(随机初始化+梯度下降) |
| 核心目标 | 激活模型已有的知识 | 引导冻结的视觉主干适应下游任务 |
- NLP提示词:通过文本形式的提示激活语言模型的知识,实现任务适配。
- VPT提示微调:将NLP中提示词思想泛化到视觉领域,用连续视觉提示替代文本提示,解决了图像缺乏离散语义的问题,同时保留了参数高效的优势。
- NLP领域可以通过给出具体的“提示词”进行编码输入到模型中,并激活模型;但是在视觉领域,“提示词”不能是具体的某个词或者token进行编码输入到模型中,而是一个可学习的参数。
-
注意力机制的交互引导
- 注意力权重分配:提示token会与图像块token共同参与注意力计算。由于提示是可学习的,它们能逐渐“吸引”模型关注与任务相关的图像区域。
- 例如,在细粒度分类任务中,提示可能引导模型聚焦于鸟类的头部或羽毛纹理。
- 特征调制:提示通过注意力权重对图像块特征进行加权组合,间接调整特征的分布,使其更适合下游任务。
- 注意力权重分配:提示token会与图像块token共同参与注意力计算。由于提示是可学习的,它们能逐渐“吸引”模型关注与任务相关的图像区域。
三 综合实验
预训练主干网络。实验采用两种视觉Transformer架构:视觉Transformer(ViT)和Swin Transformer。所有主干网络均在ImageNet-21k数据集上预训练,严格遵循原始配置(如图像分块数量、[CLS]标记设置等。
基准方法。将VPT的两种变体与以下常用微调协议进行对比:
(a) 全参数微调(FULL):更新主干网络和分类头的全部参数
(b) 分类头调优方法(固定主干网络作为特征提取器):
(c) 参数子集调优方法:
多样化视觉分类基准(VTAB-1k):
综合结果对比
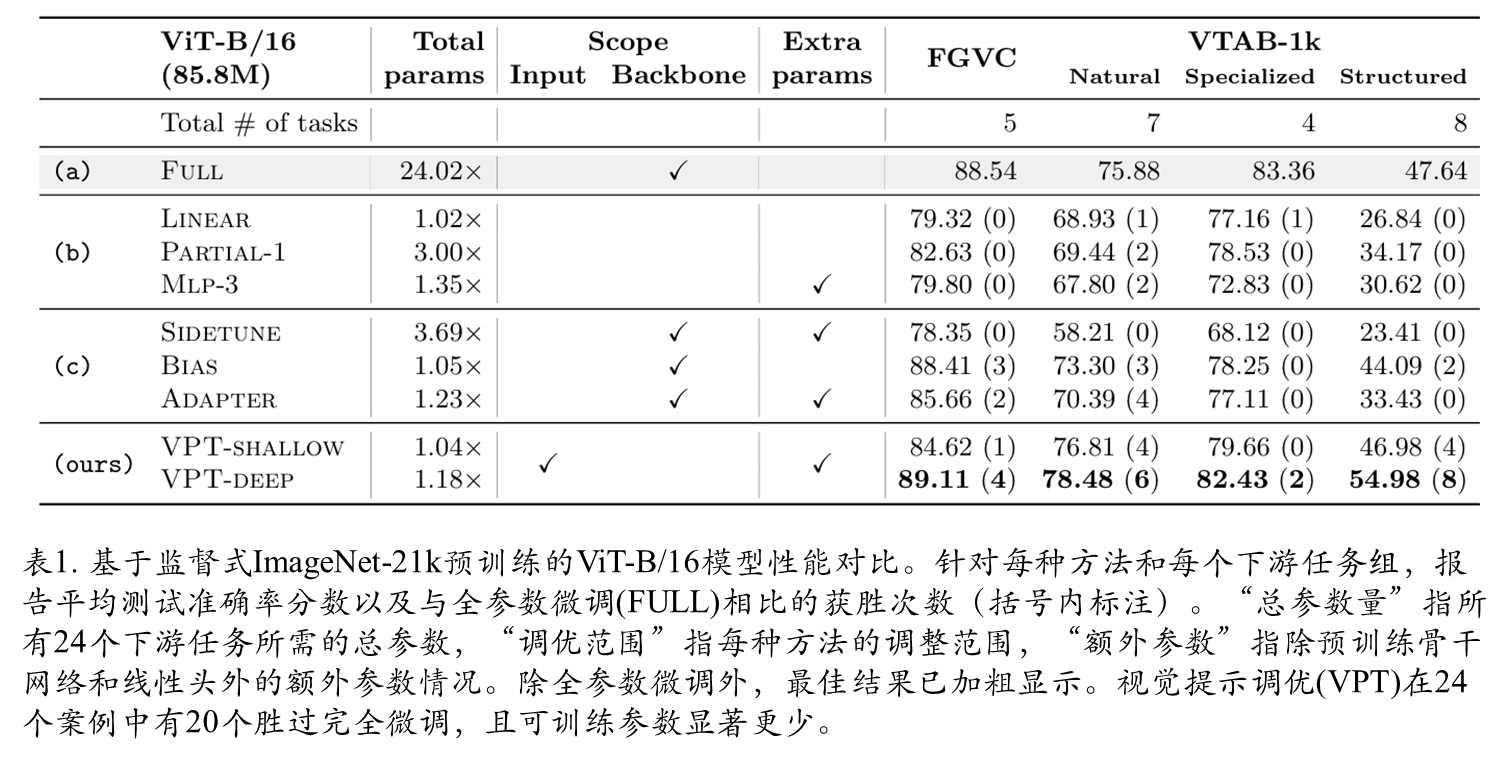
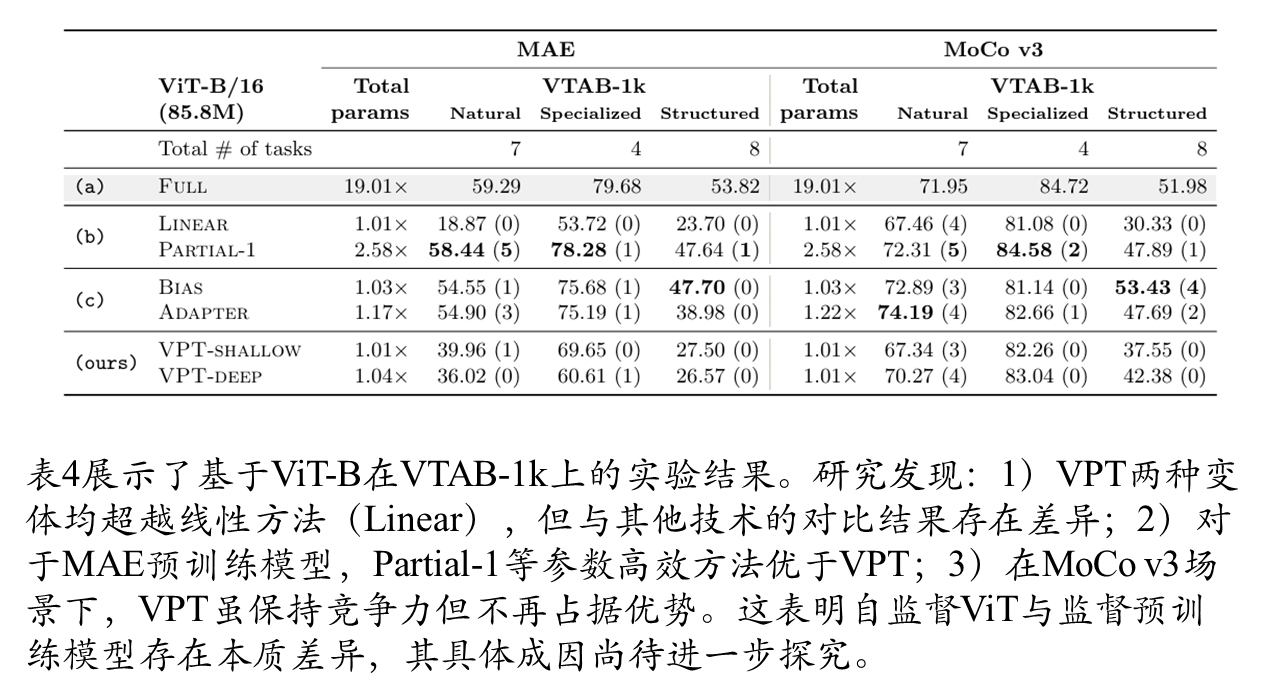
表1展示了在4个不同下游任务组上对预训练的ViT-B/16进行微调的结果,将VPT与其他7种微调协议进行比较。主要发现如下:
不同下游数据集性能对比
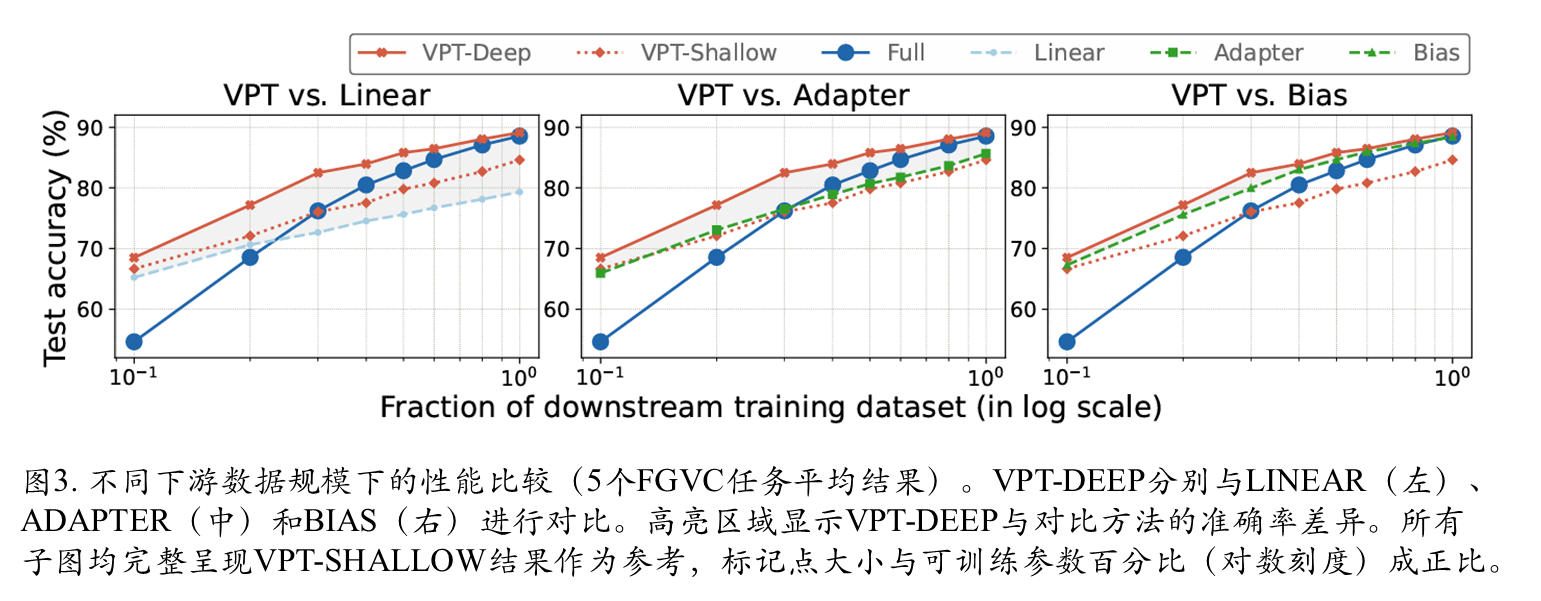
不同模型规模对比

Swin-B骨干网络实验效果
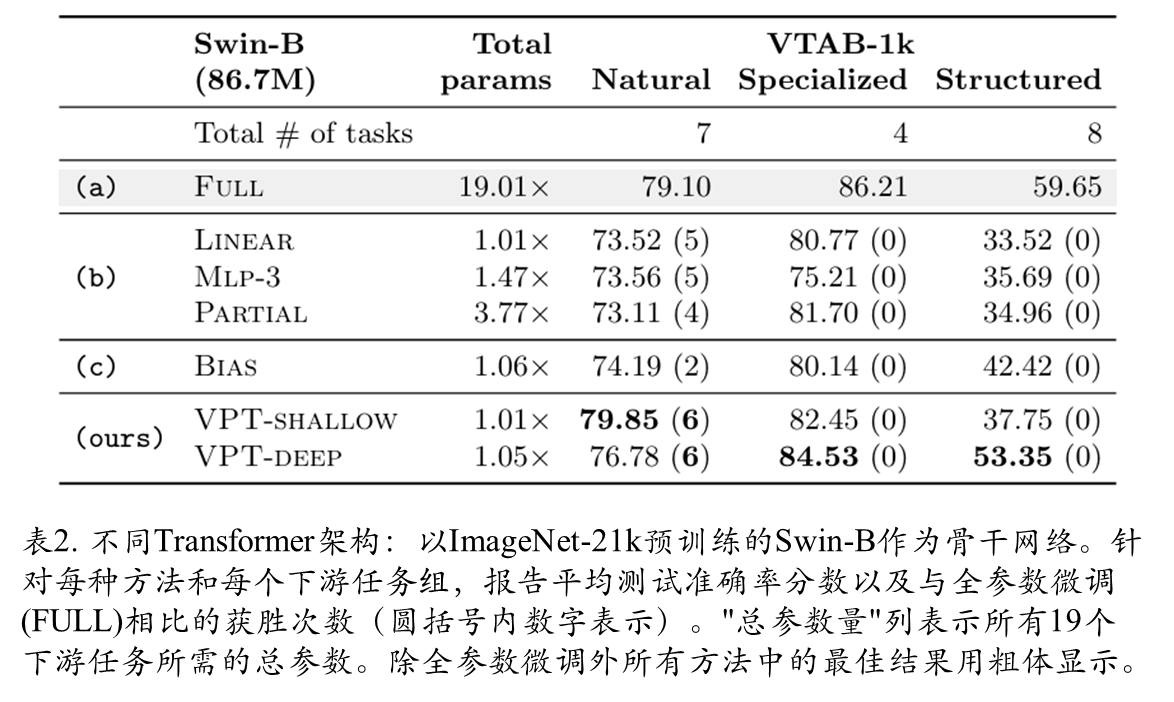
在层次化Transformer(以Swin为例)上的VPT应用表明:Swin在局部偏移窗口内采用多头注意力机制(MSA),并在深层进行补丁嵌入合并。为保持通用性,VPT采用最直接实现方式——提示在局部窗口内参与注意力计算,但在补丁合并阶段被忽略。实验使用ImageNet-21k监督预训练的Swin-Base模型,结果显示VPT在VTAB表2所有三个子类别中持续优于其他参数高效微调方法(b、c),尽管全参数微调(FULL)整体准确率最高(但需付出极高的参数总量代价)。
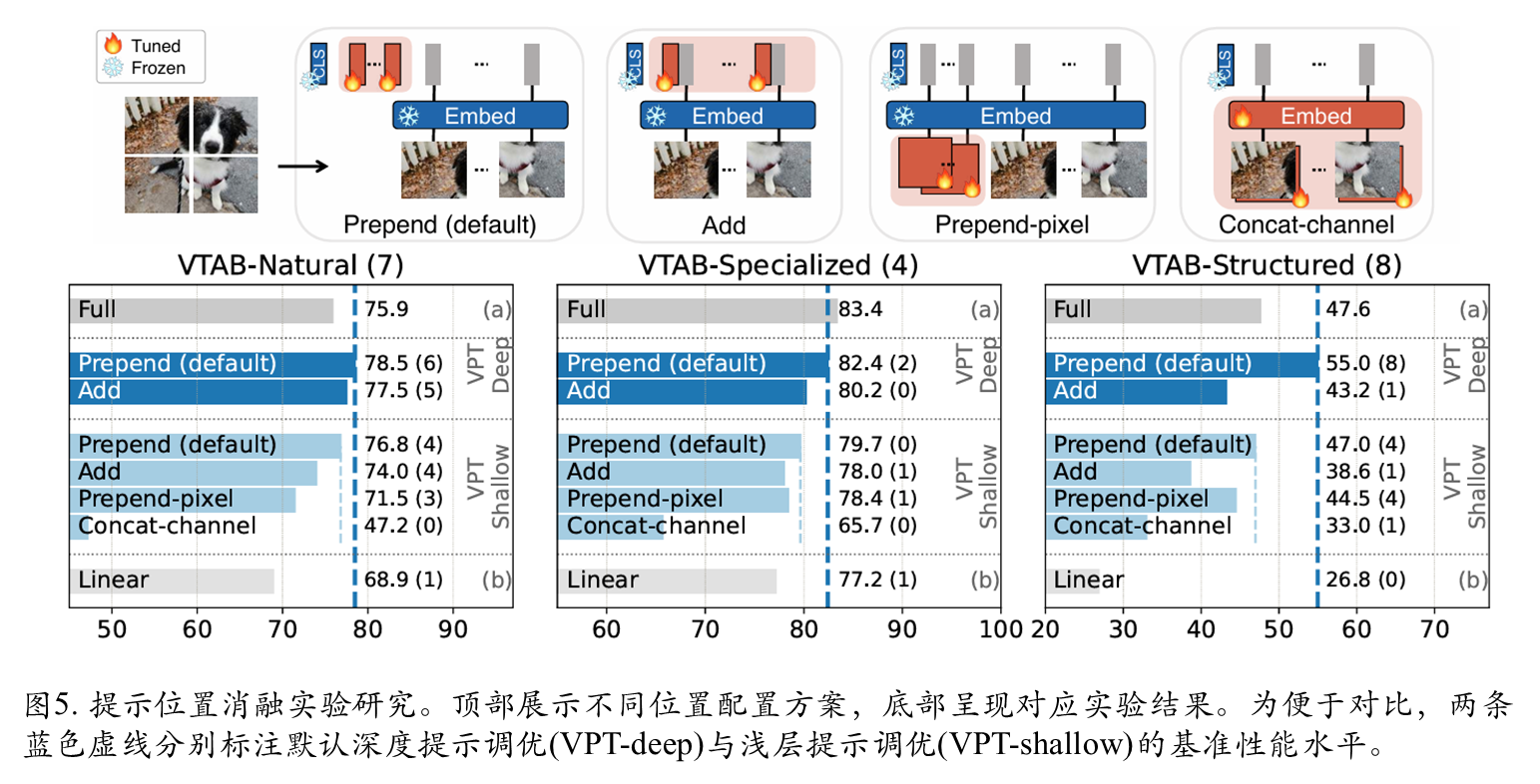
Prompt放置位置

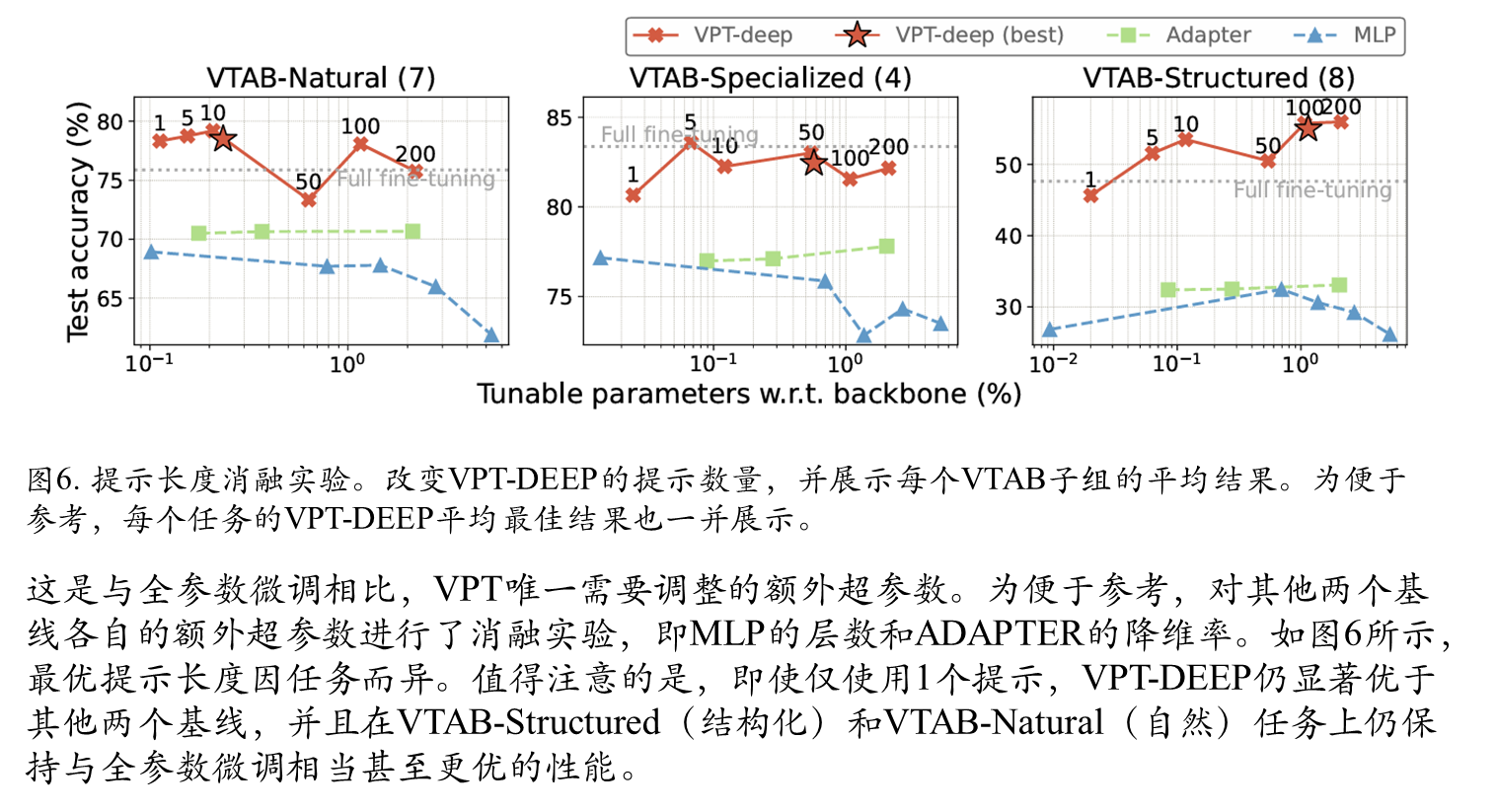
Prompt长度对比
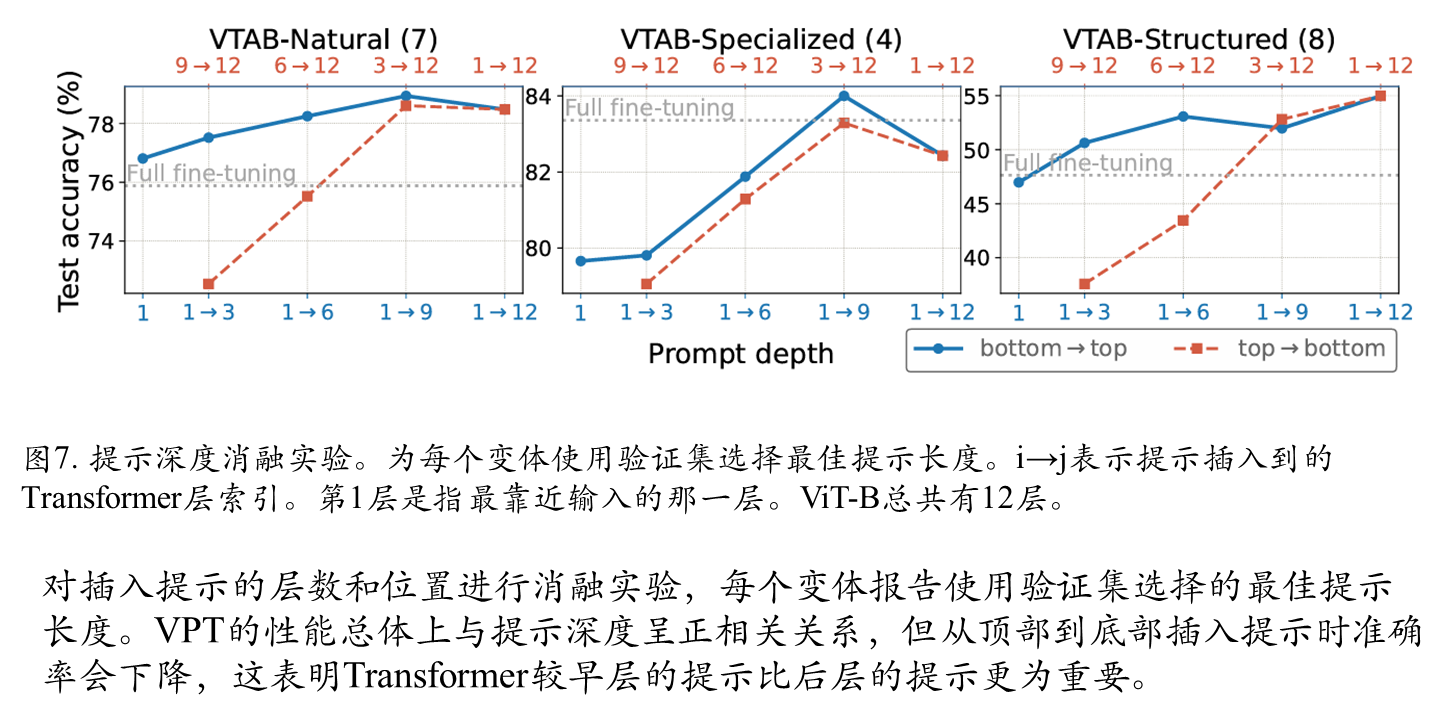
Prompt放置不同深度对比
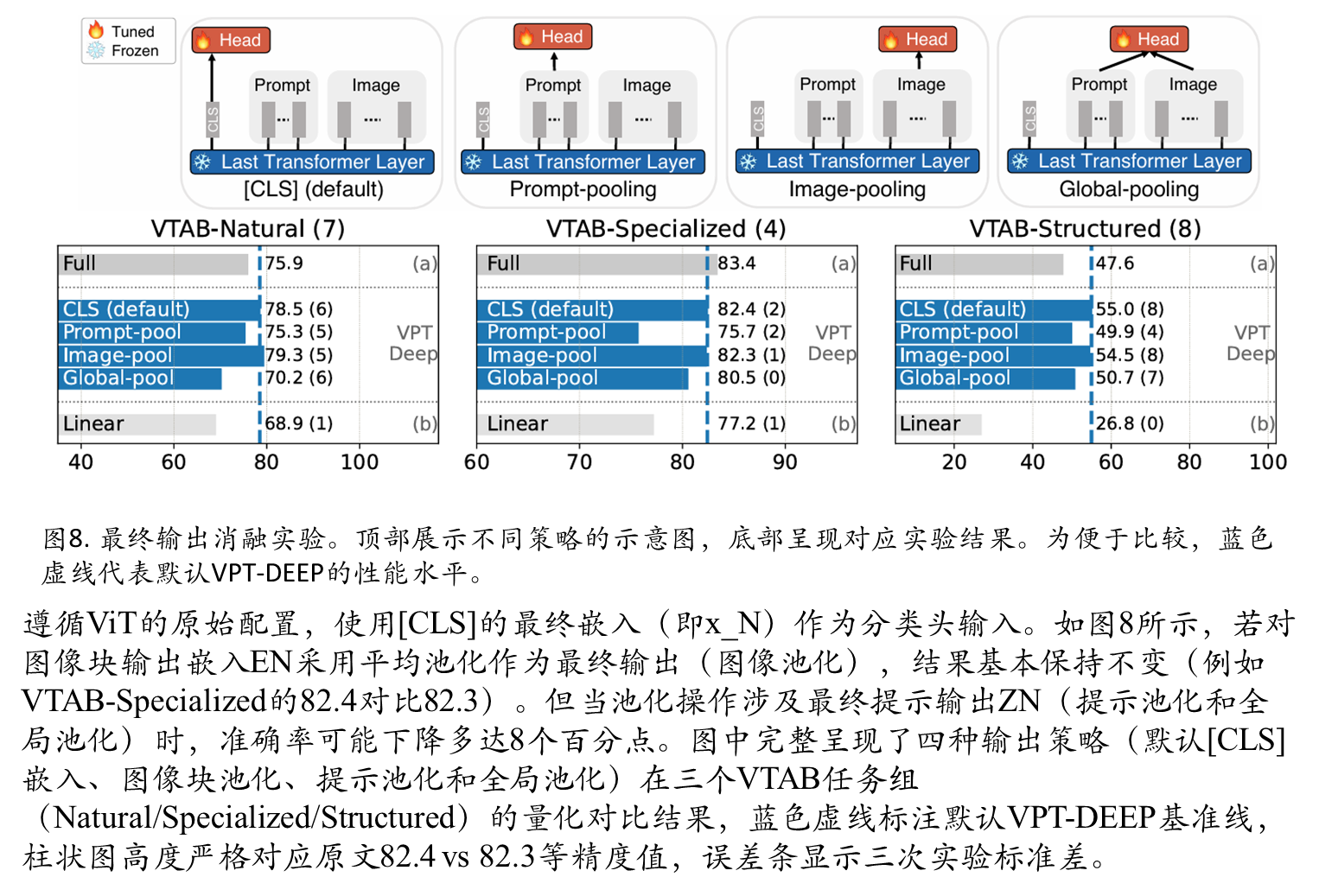
不同输出层对比
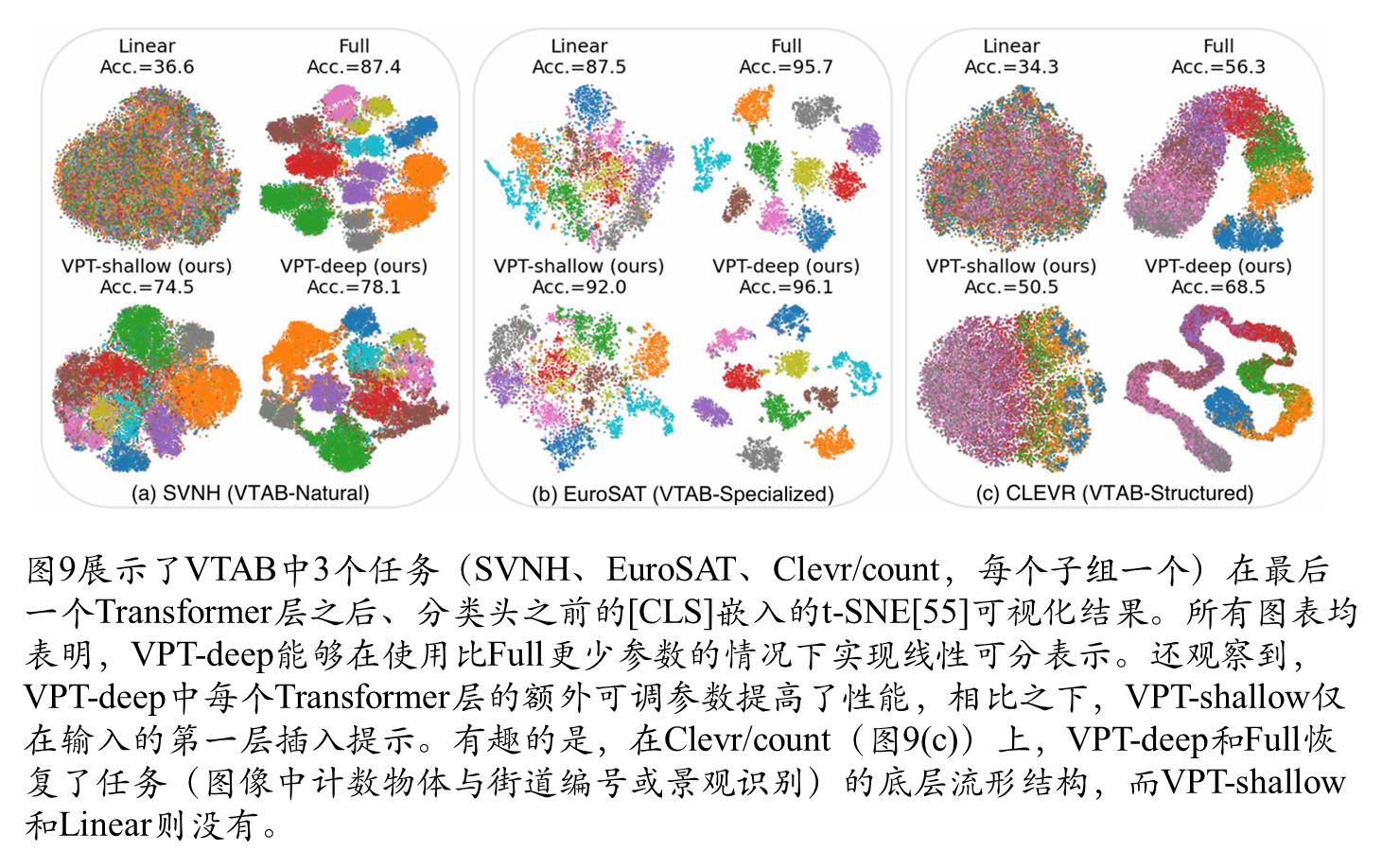
可视化对比
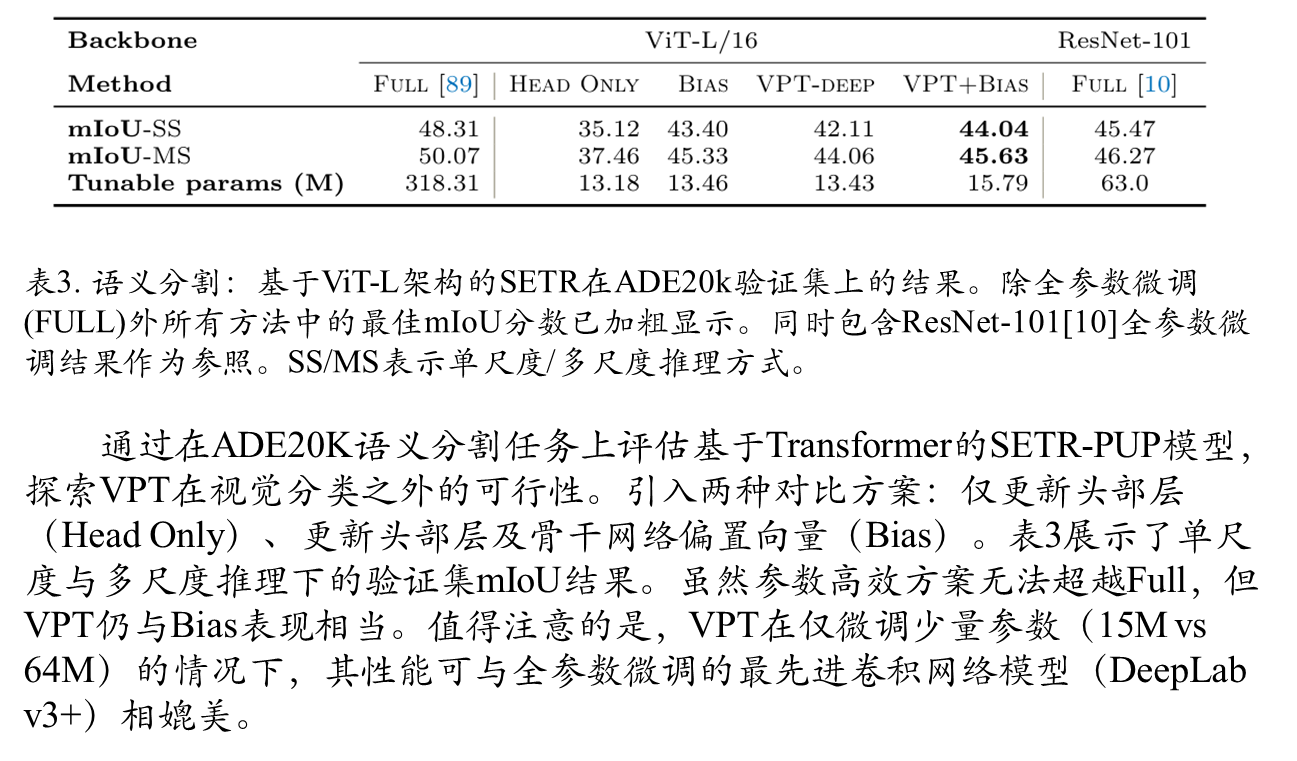
语义分割效果
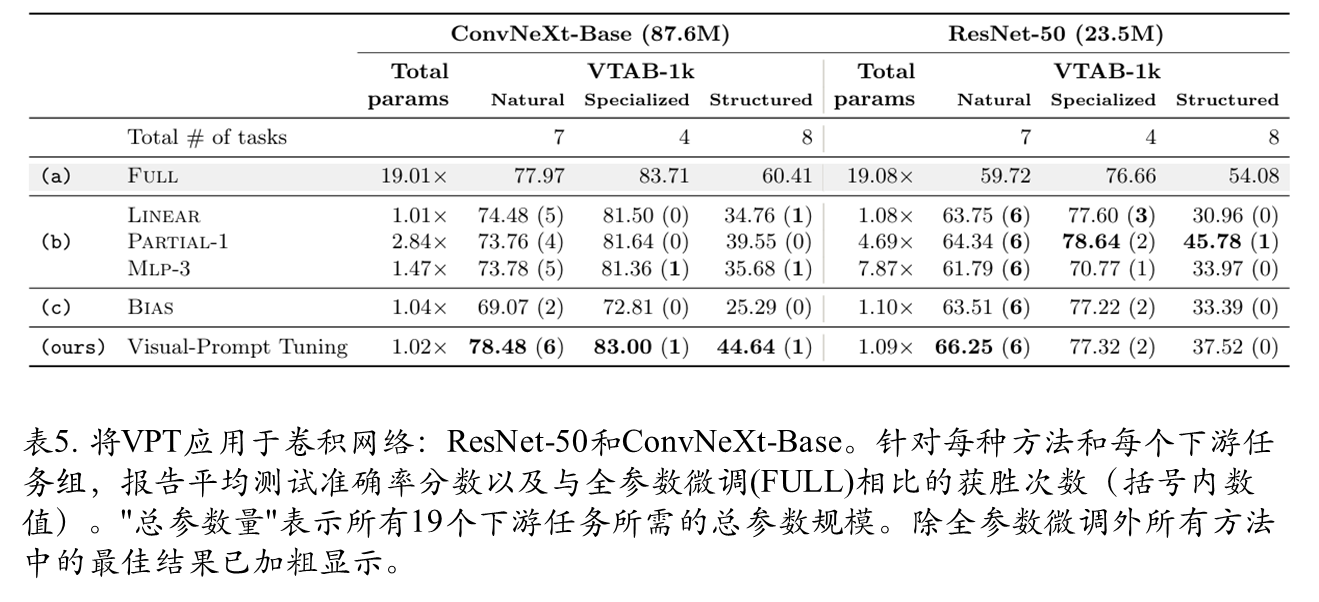
附录部分
附录部分分别从图像分类,语义分割进行了进一步的实验证明,感兴趣的同学可以去看一下。


















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









