







Active Learning Methods for Low Resource End-To-End Speech Recognition,INTERSPEECH2019
目录
1、背景及概述
In short, a active learning method using a joint score of uncertainty and i-vector diversity.
本文将主动学习应用于端到端(E2E)的语音识别。
- E2E模型使用encoder-decoder神经网络直接输出字词。相比于传统模型,E2E模型的计算复杂度更低,适用于缺少sub-word或音位级标注/对齐的情况。
- Low Resource指的是小语种(英语易于获取数据)的语音识别,该任务的标注代价更高。
- 不同于传统的语音识别方法包括声学模型和语言学模型,主动学习需要在两个模型上提取信息,近些年端到端的语音识别,可以直接输出N个路径的概率(路径是指一个给定语音的字符序列)。另一方面考虑到使用uncertainty sampling易于选取相同的speaker(文章假设),文中提出结合基于i-vector多样性的正则化的uncertainty sampling 主动学习方法。
2、方法
2.1归一化LC
文中提出的方主动学习方法首先基于Least Confidence。
输入
X
X
X,对于输出的第i条路径
C
i
C_i
Ci,对该条路径做归一化,避免路径的长度
L
i
L_i
Li的影响,得到长度归一化后路径概率:
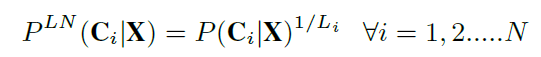
可以定义Least Confiden Score,
C
∗
C^*
C∗是X多条路径中概率最大的路径:
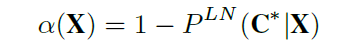

2.2Speaker Diversity
其次考虑speaker多样性,使用i-vector无监督方法对所有数据(标注和未标注)进行编码,再对编码的i-vector进行聚类。背后的思想是,在i-vertor映射空间下,不同的簇代表的是不同的speaker,应选取多样的speaker。
假设聚类
K
K
K个簇,
ϕ
(
X
)
\phi(X)
ϕ(X)表示话语
X
X
X编码后所属于的簇,可取值1到
K
K
K。把
j
j
j簇下样本的数量/所有簇样本数量作为多样性指标:
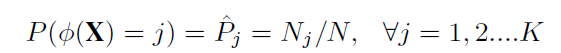
上述概率越小,代表在j簇上的样本数(word?)越少,在其余簇上越多,具有更大的多样性,可以定义多样性和应最大化的目标函数:
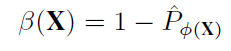
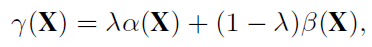
算法中每次选择综合分数最大的样本直到T个。然后更新一次多样性指标,再重复迭代。直到达到标注代价限制。
3、实验
实验使用ESPNET作为任务网络,网络结合了CTC和注意力机制。
数据预处理和特征提取使用Kaldi ASR 工具, 提取至83维特征。
i-vector是64维,使用k-means(欧氏距离)聚类至64个簇。
对比方法random,least confidence,proposed。
- Librispeech(英语)数据集,包括1000小时英语speech,使用包括500小时的子集作为训练集(20初始化标记数据,480为标记数据),5小时训练数据。网络结构是8层Bi-LSTM,评价标准有word error rate(WER)和character error rate(CER):

- Corpus of Spontaneous Japanese(日语)数据集,包括581小时训练数据和3种类型5小时测试集。使用其中的230小时作为未标记数据,20小时作为初始标记数据。网络结构是6层Bi-LSTM,评价标准有character error rate(CER):















 1965
1965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









