






 文章讨论了PVT模型如何通过Transformer结构减少计算参数,特别是SRA模块的原理,以及PVTv2版本中通过替换卷积为池化进一步减小参数。内容涉及自注意力机制、Multi-HeadAttention和这两种技术在图像处理中的应用和效率提升。
文章讨论了PVT模型如何通过Transformer结构减少计算参数,特别是SRA模块的原理,以及PVTv2版本中通过替换卷积为池化进一步减小参数。内容涉及自注意力机制、Multi-HeadAttention和这两种技术在图像处理中的应用和效率提升。
https://blog.csdn.net/pengxiang1998/article/details/130642249?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171437727516800182116678%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171437727516800182116678&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-2-130642249-null-null.142^v100^pc_search_result_base8&utm_term=PVT&spm=1018.2226.3001.4187 https://blog.csdn.net/pengxiang1998/article/details/130642249?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171437727516800182116678%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171437727516800182116678&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-2-130642249-null-null.142%5Ev100%5Epc_search_result_base8&utm_term=PVT&spm=1018.2226.3001.4187https://blog.csdn.net/zhe470719/article/details/124807854?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171437727516800182116678%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171437727516800182116678&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-124807854-null-null.142^v100^pc_search_result_base8&utm_term=PVT&spm=1018.2226.3001.4187https://blog.csdn.net/zhe470719/article/details/124807854?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171437727516800182116678%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171437727516800182116678&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-124807854-null-null.142%5Ev100%5Epc_search_result_base8&utm_term=PVT&spm=1018.2226.3001.4187以上是两篇参考博客,对于理解SRA“减少Transformer计算参数但是不改变输入输出形态”有帮助。
https://blog.csdn.net/pengxiang1998/article/details/130642249?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171437727516800182116678%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171437727516800182116678&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-2-130642249-null-null.142%5Ev100%5Epc_search_result_base8&utm_term=PVT&spm=1018.2226.3001.4187https://blog.csdn.net/zhe470719/article/details/124807854?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171437727516800182116678%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171437727516800182116678&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-124807854-null-null.142^v100^pc_search_result_base8&utm_term=PVT&spm=1018.2226.3001.4187https://blog.csdn.net/zhe470719/article/details/124807854?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171437727516800182116678%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171437727516800182116678&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-124807854-null-null.142%5Ev100%5Epc_search_result_base8&utm_term=PVT&spm=1018.2226.3001.4187以上是两篇参考博客,对于理解SRA“减少Transformer计算参数但是不改变输入输出形态”有帮助。
1 PVT
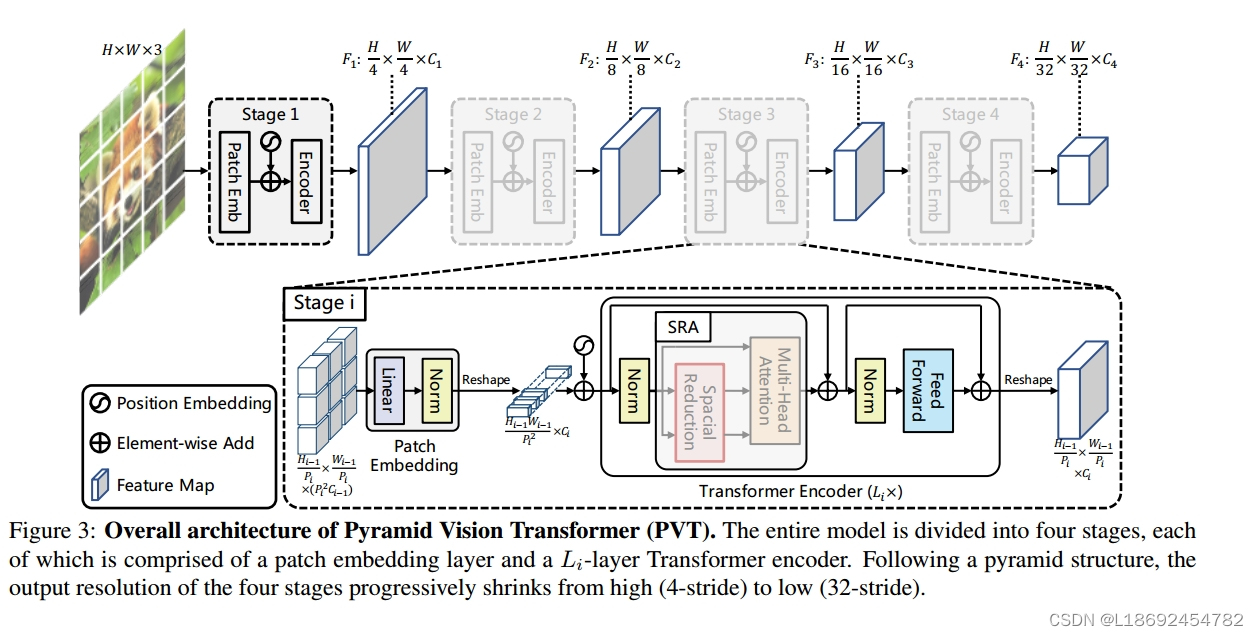
我们单刀直入,直接看PVT模型结构:RGB图像输入模型,经过四个Stage,最后得到形状为HW/32**C的张量,张量作为特征提取的结果,在其后加上全连接可以用于分类任务,在其后加上decode可以用于分割任务(作者称为密集预测任务)。其中每一个stage都会实现对输入张量的"降size增channels"操作,不同于CNN使用Conv,PVT使用Transformer实现目的,所以作者也称其为"pure Transformer"。
2 SRA
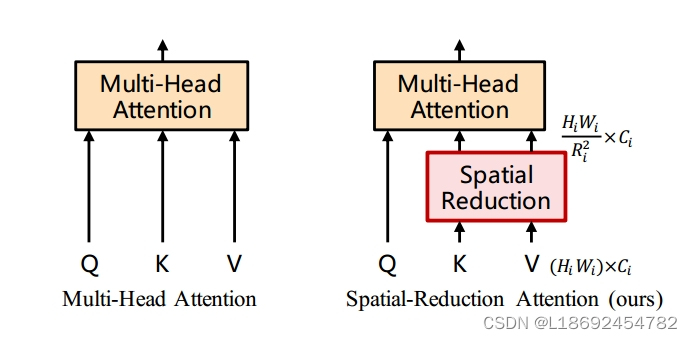
解释SRA之前,我们有必要先解释Multi-Head Attention模块。本着“不重复造轮子”的理念,我们贴出几篇有较为通俗解释的博客:Self-Attention 和 Multi-Head Attention 的区别——附最通俗理解!!_multihead attention和self attention-CSDN博客https://blog.csdn.net/leonardotu/article/details/135886678?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171444308316800222866094%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171444308316800222866094&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-135886678-null-null.142%5Ev100%5Epc_search_result_base8&utm_term=multi-head%20self%20attention&spm=1018.2226.3001.4187
Transformer中,qkv的大小都是根据patch embed来确定,之后q*,再之后(q*
)*v。根据线代知识,矩阵的相乘只需要满足“左矩阵的列数=右矩阵的行数”,最后得到的矩阵大小为“左矩阵的行,右矩阵的列”。
SRA中,为了在保证feature map分辨率和全局感受野的同时降低计算量,key(K)和value(V)的长和宽分别缩小到以前的1/R_i。通过这种方法,可以以一个较小的代价处理4-stride,和8-stride的feature map了。对kv缩小后,首先q*会因为k的形态由[3136, 64]-->[64, HW/R**],导致这个操作进行后输出的张量形态变成了[3136, HW/R**],而恰好v的形态也经过了压缩得到[64, HW/R**],所以经过[3136, HW/R**]*
得到的最后张量为[3136, 64],这和不对kv压缩得到的结果是一样的,但是实现过程却减少了很多计算量,所以我们说SRA大大减少了计算量!
3 PVT2 中的SRA
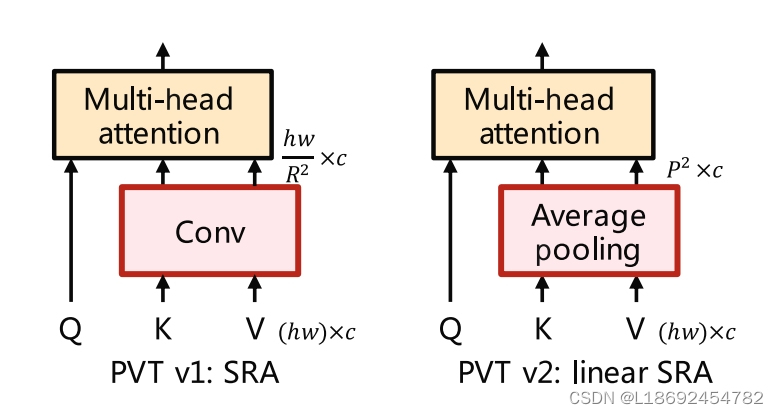
在一年后由原团队提出的《PVT v2: Improved baselines with Pyramid Vision Transformer》中,对SRA做了进一步的优化:即将SRA的实现由原来的卷积Conv改为了池化pooling,这样又进一步的减少了参数,因为“卷积操作有参数,而池化操作无需参数”(这里设计到卷积池化的一些理论知识,可以参考卷积和池化_池化降维处理-CSDN博客)。至此,SRA模块大成!

















 9704
9704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









