






一、DeepSeek的技术突破与市场定位
DeepSeek的技术突破和市场定位使其在AI领域
产生了深远的影响。其技术突破包括模型架构创新、低成本实现高性能以及开源策略推动技术普及。这些创新不仅提升了模型的性能,还降低了算力成本,促进了全球开发者参与。
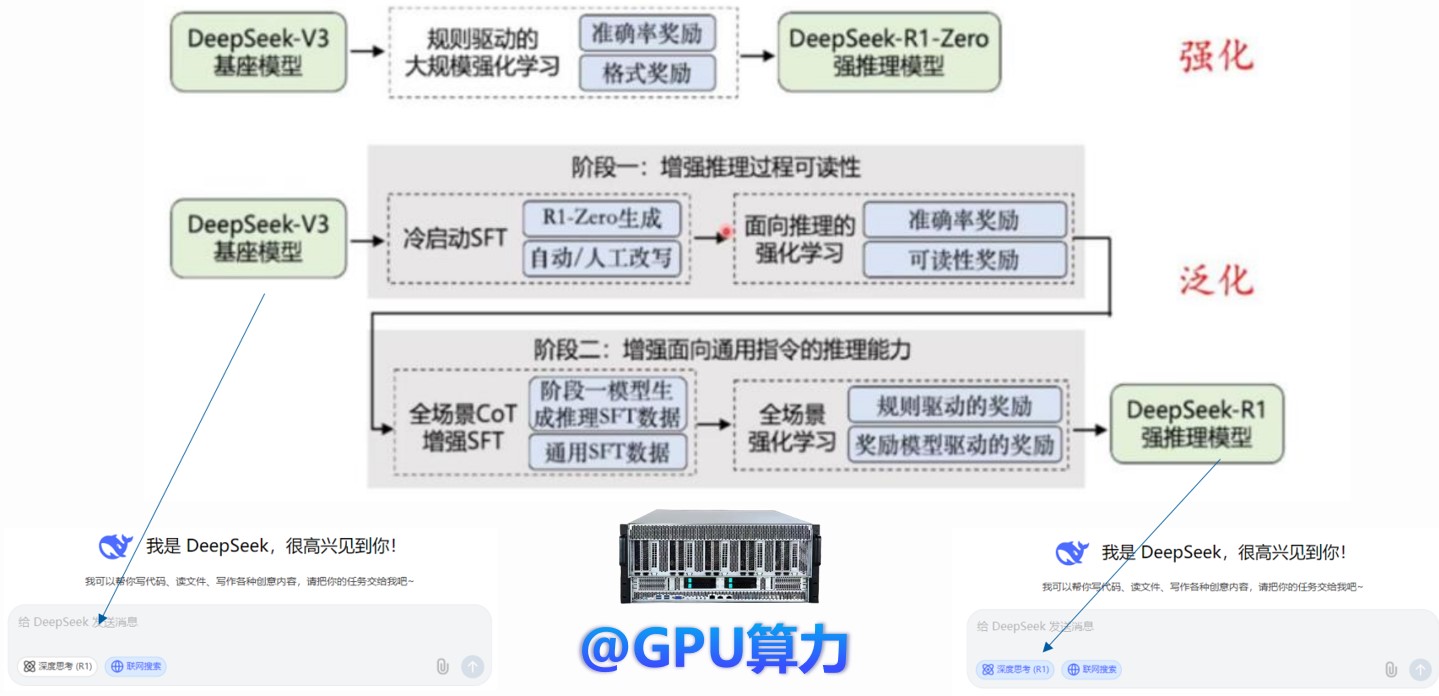
DeepSeek LLM模型版本:基座模型V3、强化推理版R1-Zero、泛化推理版R1
二、DeepSeek爆火
1. C端:DeepSeek全球破圈,成为用户规模增长最快的移动AI应用
DeepSeek在C端的成功表现在其用户规模的快速增长。与ChatGPT相比,DeepSeek在上线后的用户增长速度更快,显示出其在市场上的强大吸引力。
英伟达上线DeepSeek
2. B端:科技巨头积极拥抱DeepSeek
科技巨头们纷纷拥抱DeepSeek,推出了基于DeepSeek模型的服务。这些巨头包括微软、英伟达、亚马逊、英特尔、AMD、华为、腾讯、百度和阿里等,显示出DeepSeek在B端市场的广泛认可和应用。
三、DeepSeek爆火的原因
1. 一流的性能表现
DeepSeek-V3模型在性能上表现出色,多项评测成绩超越了其他开源模型,并在性能上与世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不相伯仲。
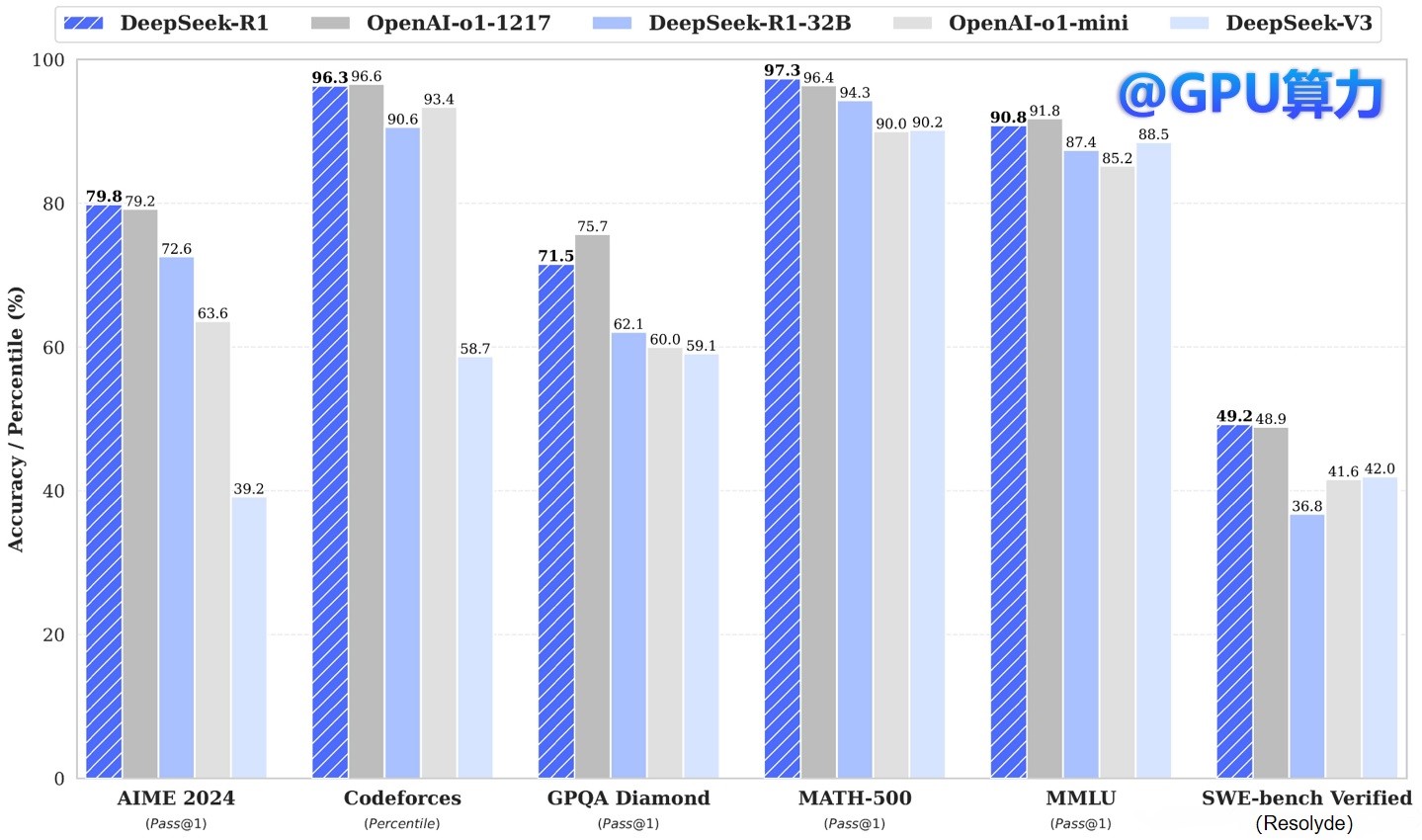
DeepSeek-V3对比领域开源/闭源模型
2. 大幅降低的算力成本
DeepSeek-V3和R1模型不仅性能出色,训练成本也极低。V3模型仅用2048块H800 GPU训练2个月,消耗278.8万GPU小时,成本仅为557.6万美金,而同等性能的模型通常需要0.6-1亿美金。
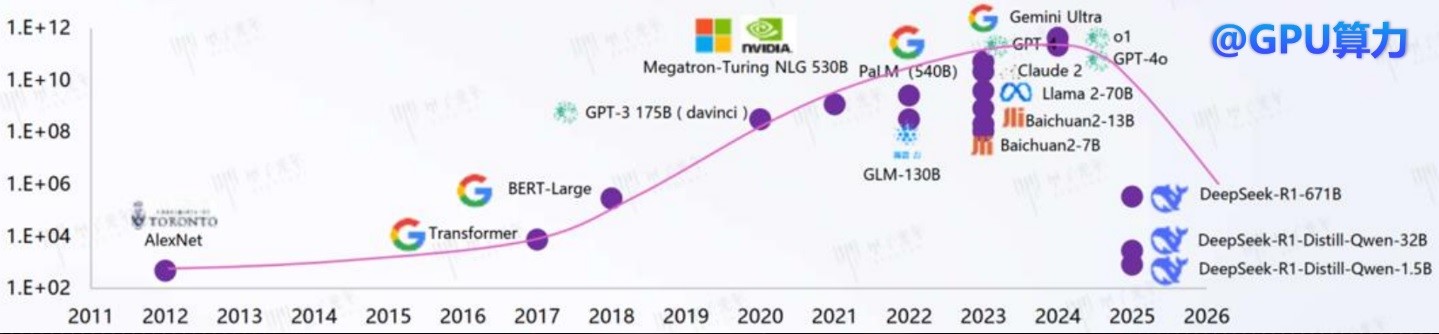
训练算力(petaFLOPs)
3. 开源模式
DeepSeek的V3与R1模型实现了开源,采用MIT协议。这不仅提升了世界对中国AI大模型能力的认知,还打破了OpenAI与Anthropic等高级闭源模型的封闭生态。
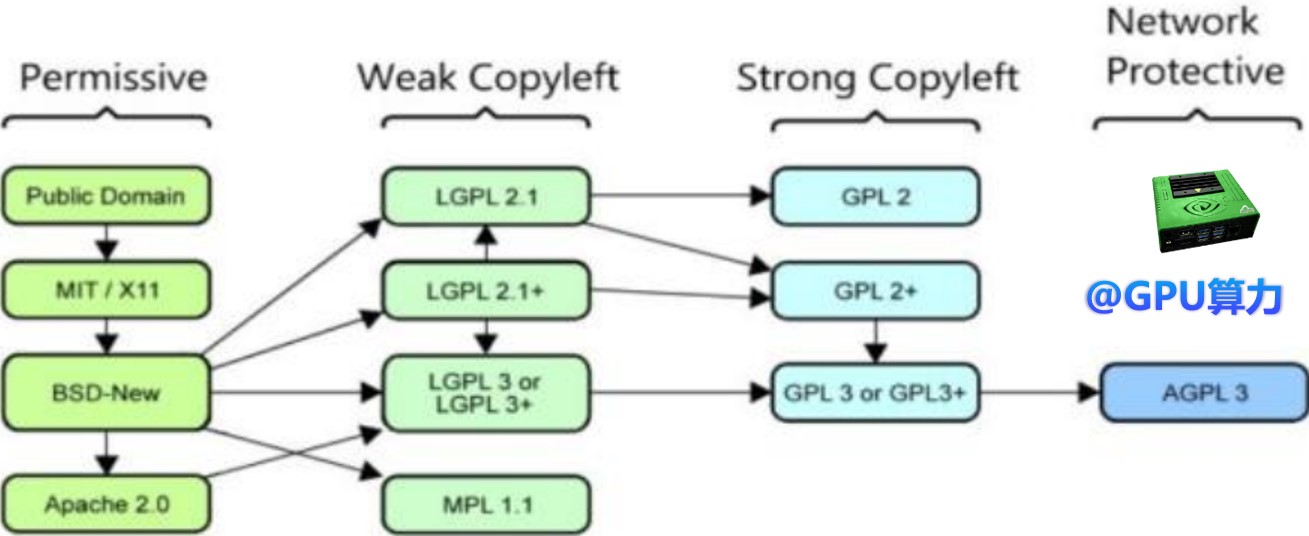
开源许可证协议标准
四、DeepSeek驱动算力需求变革
1. 训练算力头部集中,推理算力爆发式增长
训练算力仍有空间和前景,头部企业会持续进行教师模型的训练。推理算力则因开源模型和较低的推理成本而爆发式增长。
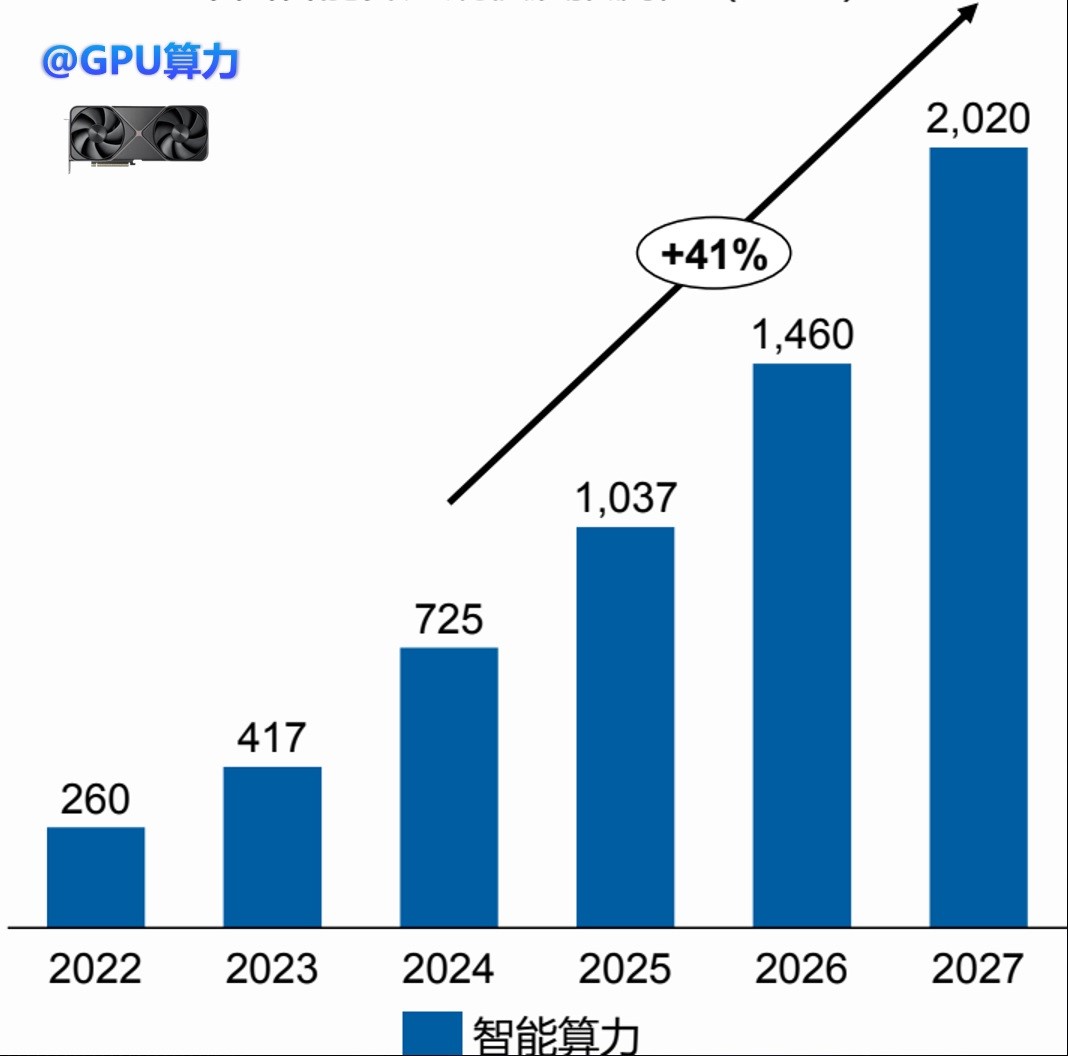
中国智能算力规模及预测 (FP16)
2. 模型轻量化催生端侧算力的崛起
DeepSeek通过知识蒸馏技术,将大模型压缩至轻量化版本,使其能够在端侧设备上高效运行。
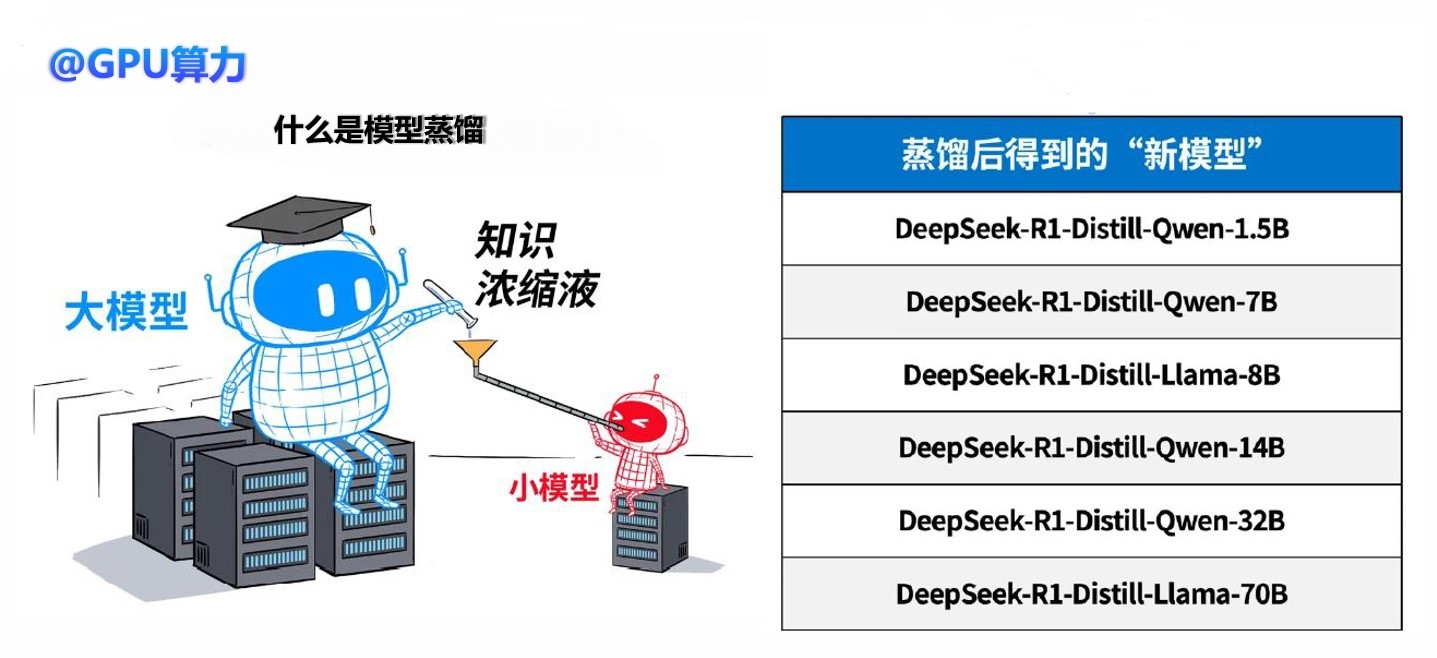
模型蒸馏
五、算力产业链的重构
1. DeepSeek通过PTX优化等创新技术,降低了模型训练对NV芯片的依赖
DeepSeek采用PTX手动优化跨芯片通信,保障数据传输效率,降低了模型训练对高端GPU的依赖。
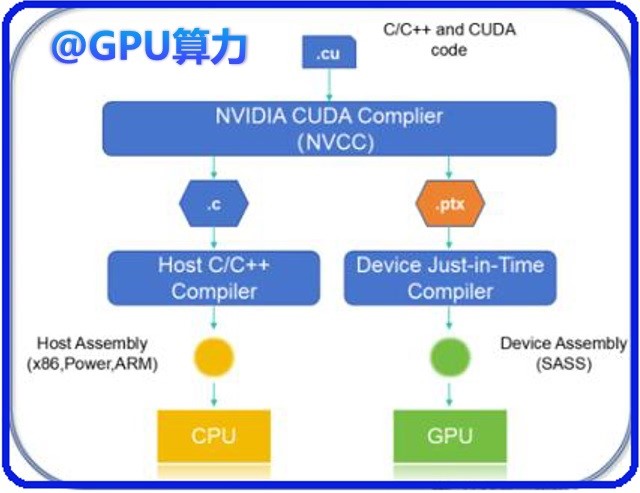
DeepSeek通过PTX手动优化跨芯片通信
2. 国产算力的应用落地
DeepSeek的训练和推理用的是FP32、BF16和FP8三种数据格式,推动了国产芯片在设计、性能提升等方面的发展。
六、大模型领域迎来“安卓时刻”
DeepSeek的发布标志着大模型领域迎来了“安卓时刻”,大量AI应用将爆发式出现。GitHub的Stars和Fork指标显示,DeepSeekV3和R1两个项目上线至今均不足2个月,但它们的累计Star和Fork均与上线时间更早的Llama接近。
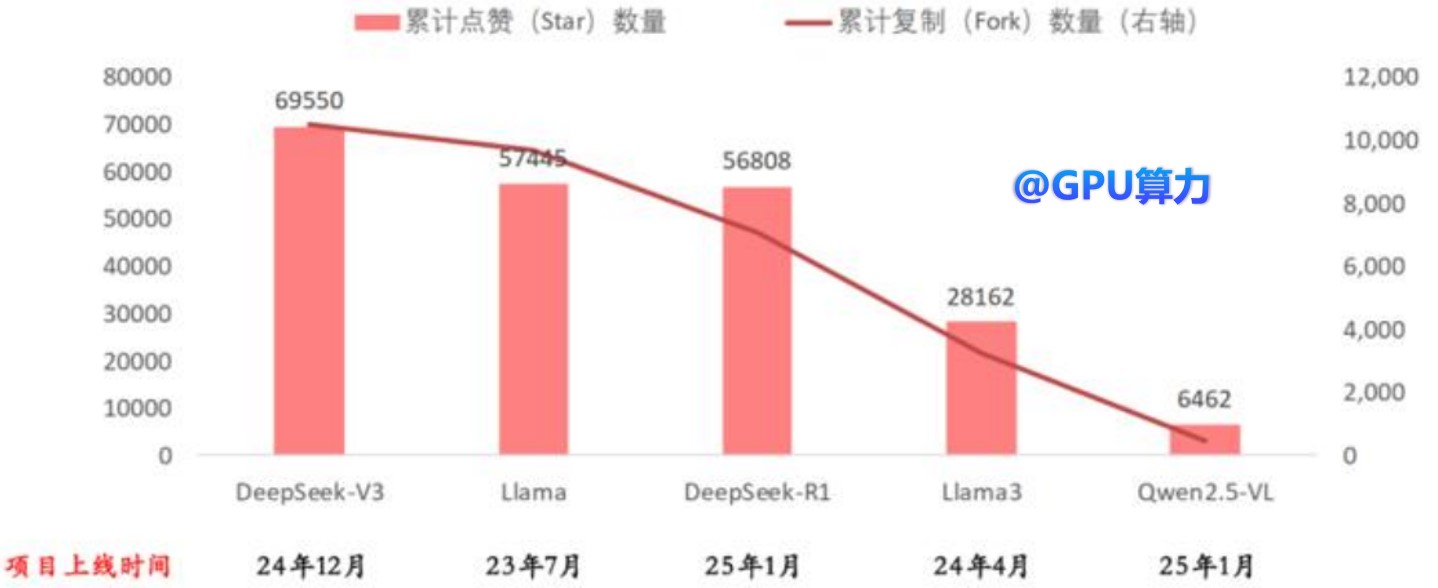
DeepSeek累计关注度高于更早发布的Llama(根据GitHub统计)
总结
DeepSeek的技术突破和市场定位使其在AI领域产生了深远的影响。其一流的性能表现、大幅降低的算力成本和开源模式推动了AI技术的普及和发展。同时,DeepSeek驱动了算力需求的变革,促进了算力产业链的重构,并为大模型的广泛应用打下夯实的基础。

















 1037
1037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









