






CatBoost的原理与优势
文章目录
一、什么是CatBoost
CatBoost是一个先进的开源机器学习算法,它属于梯度提升决策树(GBDT)家族,由俄罗斯的搜索巨头Yandex于2017年发布。CatBoost的名称来源于两个词“Category”和“Boosting”,体现了这个算法处理类别特征的能力和它基于提升方法的本质。它在处理各种类型的数据,尤其是具有复杂类别特征的数据时,显示出显著的性能优势。CatBoost的主要亮点在于其对分类变量的优秀处理能力,无需事先进行复杂的数据预处理,如独热编码。此外,CatBoost通过引入有序提升(Ordered Boosting)技术和对称决策树,有效地减少了训练过程中的过拟合问题,并且提高了模型的泛化能力。
CatBoost具有易于使用和高效执行的特点。它能够自动处理缺失值和类别特征,减少了数据预处理的工作量。算法的核心优化技术之一是对类别特征的高效处理方法,CatBoost计算类别特征与目标变量之间的统计关系,避免了传统模型中因独热编码导致的维度爆炸问题。有序提升技术通过减少训练过程中的信息泄露,进一步增强了模型的准确性和鲁棒性。
二、CatBoost关键技术
1.对称树结构
CatBoost采用了对称决策树(Symmetric Trees)作为基学习器,这种树结构在每个深度的分裂过程中,对所有叶子节点使用相同的判断条件,这样做不仅减少了模型复杂度,也提高了训练和预测的速度,CatBoost的预测速度通常要比XGBoost和LightGBM要快得多,这在低延迟环境下非常重要。
2.有序提升(Ordered Boosting)
其他梯度增强算法的过程(XGBoost、LightGBM等):
- 步骤 1:考虑 所有 (或样本)数据点来训练高度偏差的模型。
- 步骤 2:计算每个数据点的残差(误差)。
- 步骤3:通过将残差(误差)视为目标值,使用相同的数据点训练另一个模型。
- 步骤 4:重复步骤 2 和 3(n 次迭代)。
在上述标准的GBDT族模型训练过程中,每棵树的学习都是基于之前所有树的残差(或梯度)来进行的。这意味着,在计算每个数据点的残差时,都使用了全部数据集的信息。这样做虽然简化了计算过程,但也容易造成模型对训练数据的过拟合,尤其是当数据集包含类别特征时,因为模型可能会无意中“记住”训练集中的目标值,而不是学习到泛化的规律。
为了解决上述梯度提升中的目标泄露问题,CatBoost采用有序提升技术。在计算每个样本的梯度时,它仅使用在该样本之前的样本训练得到的模型,避免了信息的泄露,从而减少了过拟合。
假设我们的数据集中有 10 个数据点,并且按时间顺序排列(如果数据没有时间,CatBoost 会为每个数据点随机创建一个人工时间),如下所示:
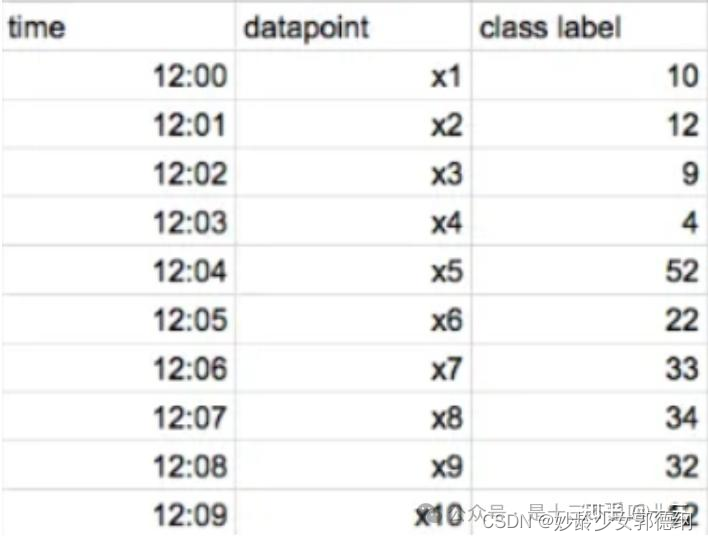
- 步骤1:使用当时已在所有其他数据点上训练过的模型计算每个数据点的残差 (例如,要计算 x5 数据点的残差,使用 x1、x2、x3 和 x4训练一个模型)。训练不同的模型来计算不同数据点的残差。最后,计算模型以前从未见过的每个数据点的残差。
- 步骤2:使用每个数据点的残差作为类别值来训练模型。
- 步骤3:重复步骤 1 和步骤 2(n 次迭代)
总结如下:
- 数据分割:将训练数据随机分割成多个(通常是两个)不同的子集。
- 有序训练:对于每个子集,CatBoost分别训练模型,但在计算当前数据点的残差时,仅使用在该数据点之前的数据点(根据分割顺序)训练的模型。这意味着,对于每个数据点,它的残差计算不会受到其自身信息的影响,有效减少了目标泄露的风险。
- 迭代过程:通过轮流改变使用哪个子集来进行预测和哪个子集用于计算残差,CatBoost确保了所有数据点都以一种防泄露的方式被利用来训练模型。
3.目标编码(Target Encoding)
CatBoost对类别特征进行了优化处理,无需手动进行独热编码(One-hot Encoding)。它采用了一种特殊的统计方法来处理类别特征,通过计算与目标变量的关联统计量来转换这些特征,进而提高模型的性能,具体情况如下所示:
- CatBoost对分类数据有非常好的向量表示。它采用有序提升的概念并将其应用于目标编码。
- 在目标编码中,通常使用数据点目标值的平均值来表示分类特征。我们使用每个数据点的类标签来表示其特征值。这往往会导致严重的目标泄漏问题。
- CatBoost仅考虑过去的数据点来计算平均值,有效避免了目标泄露问题。下面是详细的解释和例子。
数据集如下所示(所有数据点均按时间/天排序,如果数据没有时间,CatBoost 会为每个数据点随机创建一个人工时间,feature1是一个三分类的类别型特征):
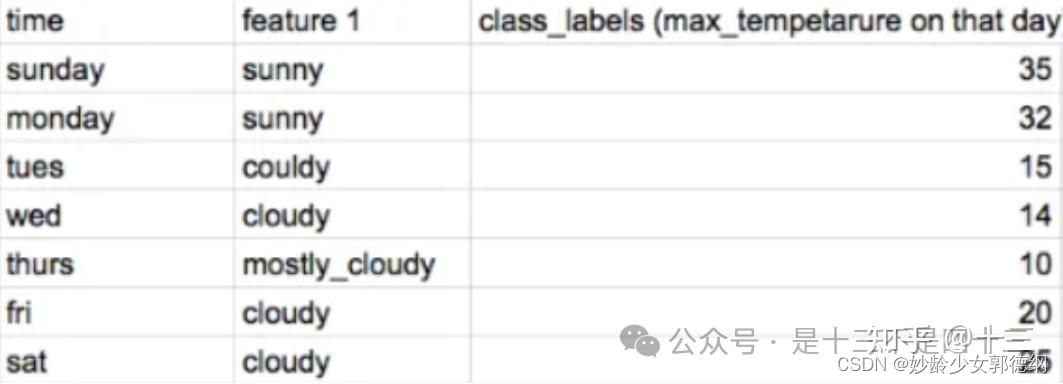
通过目标编码,多云可表示为 = (15 +14 +20+25)/4 = 18.5,但这实际上会导致目标泄漏。因为使用了同一数据点的目标值对数据点进行向量化。在CatBoost中,为了避免上述目标泄露问题,在进行向量化表示时,并不会使用所有的数据点,而是仅仅考虑“过去”的数据点。例如:
- 周五代表多云=(15+14)/2=15.5
- 周六代表多云=(15+14+20)/3=16.3
同时,为避免出现0/0的问题,额外引入拉普拉斯平滑,下面是另一个简单的例子:
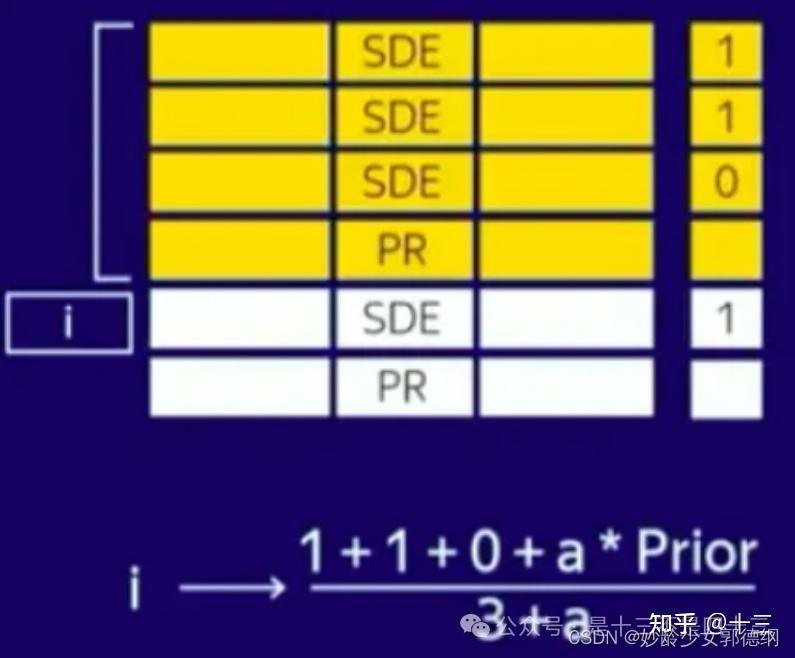
在上面的数据集中,有一个具有两个类别(SDE,PR)的特征,假设所有数据点都是按时间排序的。对于第i个数据点,将 SDE 表示为 (1+1+0)/3(在分子和分母中添加一些常数以克服 0/0 误差)。
4.分类特征组合
CatBoost模型能够自动完成分类特征的两两组合,形成新的特征代入完成建模。
三、CatBoost核心优势
- 对类别特征和缺失值的原生支持:CatBoost的一个显著优势是对类别特征和缺失值的原生处理能力。它不需要预处理就能自动处理类别特征和缺失值,这降低了数据预处理的复杂性,并可能提高模型性能。
- 最小化目标泄露:CatBoost使用了一种特殊的算法——OrderedBoosting来处理目标泄露问题,这是在处理类别特征时常见的问题。通过在模型训练中使用不同的数据子集,它有效地减少了过拟合风险。
- 对于不平衡数据集的优化:CatBoost提供了处理不平衡数据集的优化,这对于类别极不平衡的分类问题非常有用。
- 预测速度快:CatBoost的模型预测速度通常比XGBoost和LightGBM快。
- 稳定性和鲁棒性:CatBoost在默认参数下通常能提供很好的性能,这意味着即使不进行大量的参数调整,也能得到相对稳定和鲁棒的模型。
- 高性能:CatBoost在训练速度和预测效率方面都表现出色。它优化了算法的内部实现,支持多核CPU和GPU加速,可以快速处理大规模数据集,同时保持高效的预测性能。
- 模型解释性:CatBoost提供了较好的内置工具来解释模型预测,如SHAP值分析。这对于需要模型解释性的业务场景尤为重要。
四、CatBoost适用场景
- 含有大量分类特征的数据集:如果数据集中包含大量未经预处理的分类特征,采用CatBoost可以省去大量独热编码等预处理工作,同时还能获得不错的模型性能。
- 对模型的解释性有较高要求的应用:当需要向非技术人员解释模型的预测结果时,CatBoost提供的模型解释工具非常有用。
- 在避免过拟合方面遇到挑战的情况:对于那些容易出现过拟合,且调参过程复杂的问题,CatBoost的有序提升技术能够有效减轻这一问题。
- 需要处理复杂数据模式的任务:CatBoost在处理具有复杂数据模式的任务时表现出色,特别是在预测精度方面。
总结
















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









