







一. 引言以及论文梗概
GLIP改变了检测模型的输入:它不仅接受图像,还接受描述所有特征的文本提示作为输入,文本提示描述检测任务中的所有候选类别。不是分类的方式,而是匹配的方式。prompt中带有图片中所有类别的详细描述。

GLIP通过将目标检测转化为短语定位——phrase grounding问题,统一了两者的任务。传统目标检测模型对每个检测的目标进行分类,传统目标检测只关注类别标签,而GLIP则通过将图像中的区域与文本提示中的短语进行匹配(短语定位)来实现目标检测。
Phrase Grounding(短语定位)的核心内涵是识别图像中与特定短语或语句相对应的区域。
在这里,我个人认为GLIP相比于CLIP的主要改进只有两点:
1. 将图像切分为区域(对象级别的视觉建模)
CLIP 的图像处理方法主要是基于整图特征提取(global image embedding),其目标是学习图像与文本整体的对齐。然而,GLIP 引入了对象级别的建模,主要特点包括:
-
细粒度的图像区域划分
GLIP 不仅关注整幅图像,而是将图像划分为多个局部区域,每个区域对应一个潜在的对象。这种划分通常基于对象检测模型中的 Region Proposal(区域建议) 方法(如 RPN)或密集特征图上的 Anchor 框。 -
局部特征与文本的对齐
每个划分的区域不仅具有视觉特征,还被设计为可以与文本中的单个词语或短语直接对齐。这使得模型能够学习更细粒度的视觉语义表示,而不是仅仅进行全局匹配。 -
效果提升的原因
区域级别的划分使得 GLIP 能够直接定位图像中的对象,并与文本进行精确对齐。这一改动对需要细粒度理解的任务(如目标检测、实例分割)尤其重要。
说白了,CLIP是将一张完整的图和一段文字描述对齐,而GLIP是将图像中的某一块和文字描述的某一段对齐。
2. 图像与文本特征的深度融合(Deep Fusion)
CLIP 的跨模态融合仅限于最后的点积操作,即在生成图像嵌入和文本嵌入后,计算两者的余弦相似度以实现匹配。GLIP 在此基础上增加了深度交互的机制:
-
早期融合(Early Fusion)
GLIP 在图像和文本的特征提取阶段就引入了交叉模态交互。通过 Cross-Modality Multi-Head Attention(X-MHA) 模块,让视觉特征能够直接参考语言特征,反之亦然。- 例如,文本提示中的属性描述(如“a small red car”)可以通过融合影响视觉特征的表示,使其更加专注于“small”和“red”。
-
深度注意力机制(Deep Attention)
GLIP 在多个编码层中反复引入交叉注意力,逐层增强两模态特征的交互。这种深度融合使得语言语义对视觉特征的影响更加全面,而不仅局限于最后的匹配阶段。 -
语言感知视觉特征(Language-Aware Visual Features)
融合后的视觉特征已经嵌入了文本的语义信息,例如某个视觉区域不仅表示“汽车”,还可以是“红色的汽车”。这使得模型在零样本迁移(Zero-Shot Transfer)中表现得尤为出色。
二. 网络架构
GLIP在多个网络层次上进行深度的跨模态融合。这种方法使得模型在训练早期就能够捕捉到语言与视觉之间的联系,进而提升了检测结果的精确度和语义表达的丰富度在。CLIP等算法中,image和text特征通常只在最后用于计算对比学习的loss,我们称这样的算法为late-fusion model。作者在image和text特征之间引入了更深层次的融合(deep fusion),在最后几个encoder layer中进行了image和text的信息融合。
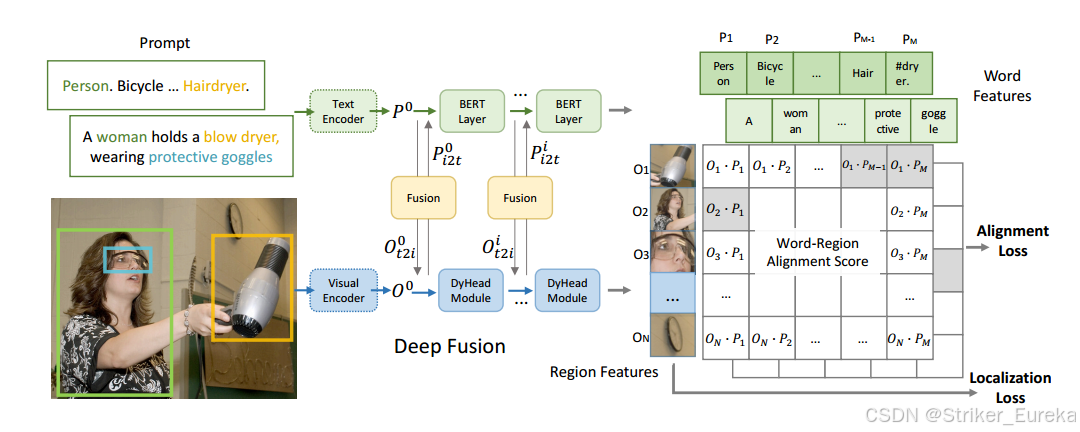
公式如下:
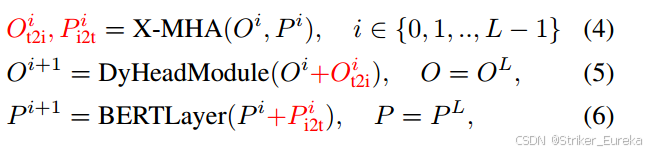
X-MHA代表跨模态多头注意力模块(multi-head attention module),L代表DyHead中DyHeadModule的个数,BERTLayer是额外添加在预训练BERT模型之上的层,
O是vision backbone提取的图像特征,P是language backbone提取的文字特征。
三 . 教师——学生模型
GLIP除了使用人工标注的检测数据,还采用了基于教师-学生框架的自我训练方法,从大规模的图像-文本数据中自动生成伪标签(如边界框)。这种伪标签的使用扩展了视觉概念的范围,使得GLIP相比CLIP可以学习更多的视觉概念。
GLIP还提供了一种快速丰富训练数据集的方式:
1)首先,用gold标准(高质量标注数据)训练一个教师模型;
2)然后,用teacher模型在新数据上进行预测,获取到检测框和对应的名词,也就是伪标注;
3)最后,用一个student模型同时在金标准数据集和伪标注数据集上训练。

为什么student模型可能会优于teacher模型呢?
作者是这样解释的:起初teacher可能并不知道类似于上图中疫苗(vaccine)和绿宝石(turquoise)的具体概念,但是它可以根据文字的上下文去猜测,例如根据“a small vial”(一小瓶),GLIP定位到了这个小瓶子,然后vaccine就可以跟这个小瓶子关联起来了,这种情况被称为“educated guess”。而在训练sutdent模型时,这些“educated guess”就变成了一个强监督信息,从而让模型真正认识疫苗(vaccine)。
四. Prompt调优
因为GLIP是语言感知的物体定位模型,即GLIP的输出强依赖于语言输入。GLIP引入了Prompt调优机制,即通过调整输入的语言提示,模型可以更精确地检测图像中的目标。尤其在面对新的任务时,Prompt调优可以减少对特定任务标注数据的依赖。例如,当你输入“扁平而圆的黄貂鱼”时,GLIP可以更好地检测出黄貂鱼。

五. GLIP检测总体步骤
GLIP为何能够进行目标检测?
- 目标检测作为短语定位:GLIP将目标检测重新定义为短语定位任务,模型通过将图像中的区域与输入的文本短语进行对齐,能够根据不同的文本描述进行检测。这种方法让GLIP不再局限于固定的物体类别,而是根据输入的自然语言描述来决定检测哪些目标。
- 基于文本条件的检测:当你输入一张图片和一个文本提示(例如“图中的椅子上有一只猫”),GLIP首先通过视觉编码器提取图像特征,并通过语言编码器处理文本提示。然后,GLIP将这两种特征进行融合,并将图像区域与文本中的词汇进行匹配,从而生成检测框,标记出与文本提示匹配的物体。
具体步骤如下:
GLIP 的图像切割和短语匹配过程:
- 图像切割(区域生成):
- 在输入图像中,GLIP 并不是直接检测整个图像,而是通过一种类似于传统目标检测方法的方式,将图像切分为多个区域。这个区域生成过程是由卷积神经网络(如ResNet或Swin Transformer)来完成的,类似于将图像分割为多个潜在的候选物体区域。
- 每个区域对应一个固定的视觉特征,这些特征会用于之后的检测和对齐。
- 对象查询(Object Queries):
- GLIP 利用类似于 DETR(Detection Transformer) 的 对象查询(Object Queries) 机制。对象查询可以理解为一组学习到的嵌入向量,它们用于在图像的不同区域内“查找”潜在的物体。
- 每个对象查询在与图像中的不同区域交互时,会尝试匹配与这些区域相关的特征。这一过程会生成候选区域,这些候选区域代表了图像中可能包含目标对象的部分。
- 跨模态对齐(Cross-Modal Matching):
- 同时,GLIP 会通过语言模型提取文本短语(Prompt)的嵌入向量。然后,模型通过跨模态的注意力机制,将这些语言短语与图像中生成的区域进行匹配。这个过程类似于短语和视觉区域的“对齐”。
- 这种对齐过程使得模型能够理解每个区域中包含的物体是否与输入的文本描述相匹配。例如,当输入提示是“桌上的苹果”时,模型会找到图像中可能包含“桌子”和“苹果”的区域。
- 区域与短语匹配(Region-Phrase Matching):
- 对象查询会将每个区域的视觉特征与文本中的短语特征进行比对,并根据匹配度输出一个预测值。如果某个区域与短语高度匹配,模型就会认为该区域包含与短语描述相关的目标对象。
- 对于每个匹配成功的区域,GLIP 会生成一个边界框(Bounding Box),来标记图像中的目标对象的位置。
- 生成检测框与输出:最终,GLIP 会基于匹配的区域生成检测框。这些检测框围绕着与文本短语对应的物体,并且框的数量和位置依赖于输入的语言描述。检测框不仅标识物体,还会返回该物体的类别标签和位置。
总的来说:GLIP通过将图像切割成多个区域并结合输入的语言提示,对这些区域与短语进行跨模态匹配,从而生成检测框并实现目标检测。
六.论文代码复现
关于代码的详细复现大家可以看看这位博主的博客,写的非常清晰:GLIP代码调试与效果分析![]() https://blog.csdn.net/weixin_42479327/article/details/136548874
https://blog.csdn.net/weixin_42479327/article/details/136548874
下面是我复现代码的结果:
caption = "Three elegant egrets stand on rocks ."
![]()

















 3494
3494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









