







一. 论文梗概
主要贡献可以概括为三个方面:
•介绍了YOLO-World,这是一种先进的开放词汇表对象检测器,具有高效的现实应用。
•我们提出了一种可重新参数化的视觉-语言路径聚合网络RepVL-PAN(来连接视觉和语言特征)和区域-文本对比损失,以促进视觉和语言信息之间的交互。并提出了一种开放词汇区域-文本对比的YOLO-World预训练方案。
•在大规模数据集上预训练的YOLO-World显示出强大的零射击性能,在LVIS上达到35.4 AP和52.0 FPS。预训练的YOLO-World可以很容易地适应下游任务,例如开放词汇实例分割和引用对象检测。此外,YOLO-World的预训练权值和代码将被开源,以方便更多的实际应用。
二. 三种对象检测器的比较:
关于传统目标检测所存在的问题大家可以去看看我这一篇博客:传统的目标检测模型存在的问题

(a)传统的对象检测器
在过去的几十年里,传统的目标检测方法可以简单地分为三类,即基于区域的方法、基于像素的方法和基于查询的方法。
这些对象检测器只能检测训练数据集预定义的固定词汇表内的对象,例如COCO数据集的80个类别。固定的词汇限制了开放场景的扩展。
(b)以前的开放词汇检测器
以前的方法倾向于开发大而重的检测器用于开放词汇检测,直观上具有很强的能力。此外,这些检测器同时编码图像和文本作为预测的输入,这在实际应用中是耗时的。例如已经提出的GLIP,GroundingDINO。
(c) YOLO- world
我们展示了轻量级检测器的强大开放词汇性能,例如YOLO检测器,这对于实际应用具有重要意义。与使用在线词汇表不同,我们提出了一种高效推理的提示-检测范式,用户根据需要生成一系列提示,这些提示将被编码到离线词汇表中。然后可以将其重新参数化为模型权重,用于部署和进一步加速。
三. YOLOWorld模型架构解读
传统的YOLO系列检测器,其训练label为bounding box和对应的物体类别,它由边界框{Bi}和类别标签{ci}组成。但YOLO-World中定义的label为一个区域-文本对,区域-文本对Ω = {Bi, ti} ,即区域Bi和对应物体的文本描述ti。 文本可以是类别名称、名词短语或对象描述。
(文章中提到的区域-文本对(region-text)指边框和描述,图像-文本对(image-text)指整张图像和对应的文本描述)
YOLO-World同时采用图像I和文本T(一组名词)作为输入,输出预测框{Bk}和对应的对象嵌入{ek}。
模型架构总体图如下:
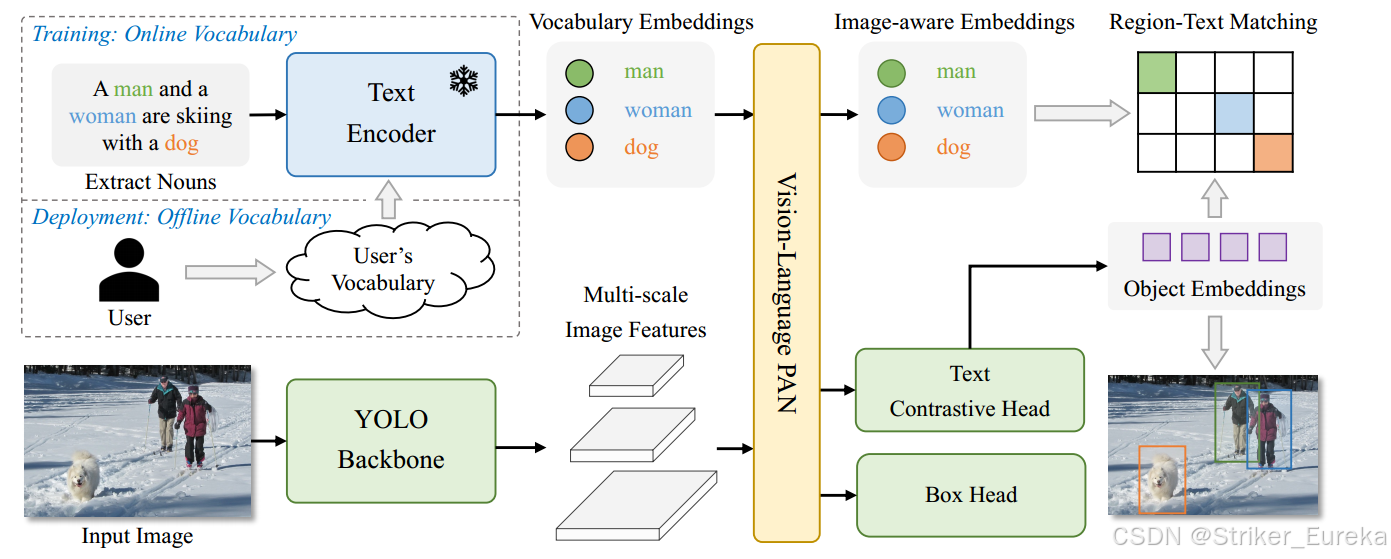
总体架构概述:
YOLO-World 的模型架构由三个核心部分组成:
- YOLO 主体检测器(YOLO Detector):负责视觉特征提取和边界框预测。
- 文本编码器(Text Encoder):负责将用户输入的文本提示转化为嵌入表示。
- 可重参数化的视觉-语言特征聚合网络(RepVL-PAN):实现视觉和语言特征的深度融合,为开放词汇检测提供支持。
给定输入文本,YOLO-World中的文本编码器将文本编码为文本嵌入。YOLO检测器中的图像编码器从输入图像中提取多尺度特征。然后,我们利用RepVL-PAN通过利用图像特征和文本嵌入之间的跨模态融合来增强文本和图像的表示。
(1)YOLO Detector
YOLO-World 基于 YOLOv8 架构,负责图像特征提取和目标检测任务。
- Darknet Backbone:经典 YOLO 的深度卷积神经网络,用于提取多尺度图像特征。
- Path Aggregation Network (PAN):
- 用于多尺度特征融合。
- 提升网络对小目标和细节特征的捕捉能力。
- Head:
- 输出边界框预测(Bounding Boxes)。
- 生成物体嵌入(Object Embeddings),用于与文本嵌入对比匹配。
关于PAN网络可以看看我的一篇博客:一些多尺度特征融合方法的讲解
(2)Text Encoder
YOLO-World 的文本编码器基于 CLIP(Contrastive Language–Image Pre-training),其作用是将用户输入的文本提示转化为嵌入表示:采用CLIP预训练的Transformer文本编码器提取相应的文本嵌入W =TextEncoder(T)∈R C×D,其中C为名词个数,D为嵌入维数。与纯文本语言编码器相比,CLIP文本编码器提供了更好的视觉语义能力,可以将视觉对象与文本连接起来。
当输入文本为标题或引用表达式时,我们采用简单的n-gram算法提取名词短语,然后将其输入文本编码器。
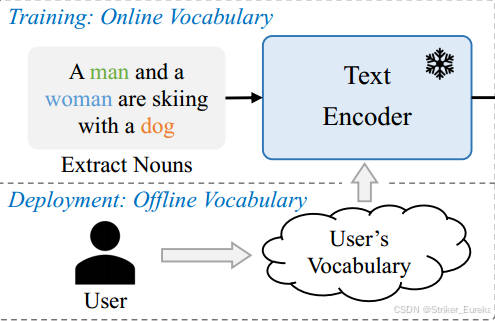
上面这幅图展示了 YOLO-World 中训练阶段和推理阶段的词汇处理方式,分别为 Online Vocabulary 和 Offline Vocabulary。将两部分分开设计的原因可以从以下几个角度分析:
1.在线词汇 (Online Vocabulary) 用于训练
目的:
- 多样化训练数据:通过从图像描述中提取名词(如 "man"、"woman"、"dog"),动态生成类别集合。
- 丰富类别空间:自动提取的名词词汇有助于覆盖更广泛的物体类别,而不局限于固定的预定义标签。
优势:
- 增强泛化能力:
- 模型在训练时学习到动态生成的词汇(名词)与视觉特征的关系。
- 避免模型仅限于有限的、静态的标签集。
- 减少数据标注成本:
- 利用自然语言描述生成的伪标签,可以减少人工标注负担。
- 特别适合开放词汇场景,即不需要对每个类别进行人工标注。
具体实现:
- 输入图像及其描述性标注(如自然语言句子)。
- 从句子中提取名词,并使用 CLIP Text Encoder 将这些名词转化为文本嵌入。
- 模型通过训练学习目标嵌入与这些名词嵌入的对齐关系。
2. 离线词汇 (Offline Vocabulary) 用于推理
目的:
- 用户自定义检测目标:允许用户在推理时定义需要检测的类别(如 "cat"、"car" 或任意短语)。
- 高效推理:通过离线计算用户提供的词汇嵌入,减少推理时的计算开销。
优势:
- 灵活性:
- 用户可以自由选择或扩展类别,无需修改模型。
- 支持零样本检测,即可以检测模型未见过的类别。
- 计算效率:
- 离线词汇表可以提前计算嵌入,避免推理时重复调用文本编码器。
- 提高推理阶段的速度,使模型更加适合实时应用。
具体实现:
- 用户提供需要检测的类别集合(即离线词汇)。
- 在推理阶段,预先计算这些类别的文本嵌入,并与图像中检测到的目标嵌入进行相似度匹配。
3. 为什么要分成两个部分?
(1) 模型训练和推理的需求不同
- 训练阶段:需要让模型尽可能学习丰富、多样的视觉-语言对齐关系,因此采用在线动态生成的词汇(通过句子提取名词)。
- 推理阶段:目标是快速、准确地检测用户关心的类别,因此采用静态离线词汇表,避免推理时的高计算成本。
(2) 性能优化
- 训练阶段通过动态生成词汇,增强模型的泛化能力。
- 推理阶段通过离线词汇,降低复杂度,提高实时性。
(3) 灵活性与扩展性
- 训练时,模型无需预定义固定类别,能从任意描述中学习不同类别的语义特征。
- 推理时,用户可以自由定义检测目标,模型支持未见类别的检测(零样本学习)。
(3)RepVL-PAN(核心创新点)
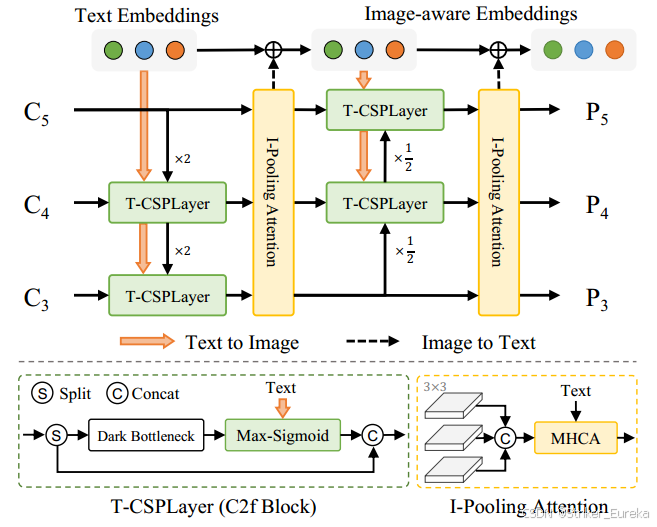
RepVL-PAN 是 YOLO-World 的关键组件,负责视觉与语言特征的跨模态融合。提出了文本引导T-CSPLayer和图像池注意(I-Pooling Attention),进一步增强图像特征和文本特征之间的交互。
通过多尺度图像特征{C3, C4, C5}建立特征金字塔{P3, P4, P5}。
设计目标:在多尺度图像特征和文本嵌入之间建立联系,增强模型对开放词汇的表征能力。
主要模块:
1.Text-guided CSPLayer(文本指导的跨阶段部分层):
CSP的讲解我在这里也有:一些多尺度特征融合方法的讲解
Xl代表第l个尺度的特征,W j表示文本编码
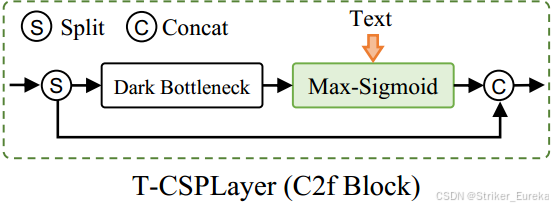
Text-guided CSPLayer:将文本引导加入到多尺度图像特征中,形成了文本引导CSPLayer。具体来说,给定文本嵌入W和图像特征Xl∈R H×W×D (l∈{3,4,5}),我们采用最后一个黑暗瓶颈块后的max-sigmoid关注将文本特征聚合为图像特征:
将视觉特征 X分为两部分:
- 一部分通过卷积层生成高效的特征表示。
- 另一部分通过残差路径与文本嵌入W 融合,生成具有文本引导的特征。
- 将两部分特征拼接并融合,输出最终的增强视觉特征 Xoutput。
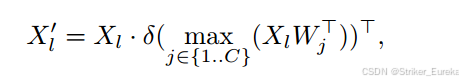
就是X和W计算相似度矩阵,然后得到一组向量,这个向量其实就是文本编码中每个词语的相似度,将它作为权重乘上特征,相当于对每个通道的特征进行加权。
2.图像池化注意力(I-Pooling Attention):
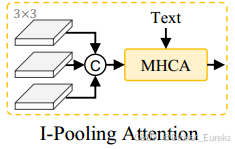
I-Pooling Attention 的执行过程可以分为以下步骤:
-
多尺度池化:将输入的特征图通过多个不同尺度的池化层,分别提取局部特征和全局语义信息。
-
特征拼接:将多尺度池化后的特征图拼接在一起,形成一个融合多尺度信息的新特征图。
-
引入文本特征:文本特征由文本编码器生成,作为指导模型的额外上下文信息。
-
多头交叉注意力 (MHCA):图像特征与文本特征通过 MHCA 进行融合,生成强化的视觉特征。MHCA 可以将文本中的关键信息(如目标类别或描述)与对应的图像区域进行对齐,提升模型对开放词汇目标的检测能力。
-
输出:输出是增强后的特征图,融合了图像的多尺度上下文信息和文本语义信息。
![]()
总的来说:Text-guided CSPLayer就是将文本聚合到图像中,I-Pooling Attention就是将图像聚合到文本中。
(4)Text Contrastive Head-文本对比头
Text Contrastive Head 的主要目标是:
- 将视觉特征与语言特征对齐:通过对比机制,将视觉检测器输出的目标嵌入与用户定义的文本嵌入进行相似性计算。
- 分类任务的本质替代:相比传统的固定类别分类器,Text Contrastive Head 可支持开放词汇分类,即用户可以动态定义检测的类别或短语。
Text Contrastive Head 的核心功能是计算目标嵌入 ek 和文本嵌入 wj之间的相似度 sk,j。
根据以前的工作,作者依然选择解耦头的设计,用俩个3×3卷积作为box head用于回归边框值。因为要计算目标-文本的相似度,所以提出文本对比头。为了稳定区域-文本训练,目标编码e和文本编码w使用L2-Norm。
——这部分的计算方式和CLIP的计算相似度的方式相同,都是通过矩阵相乘,其中 α,β是可学习的缩放与偏移因子。
![]()
四. 损失函数

五. 实验结果
Zero-shot Evaluation on LVIS: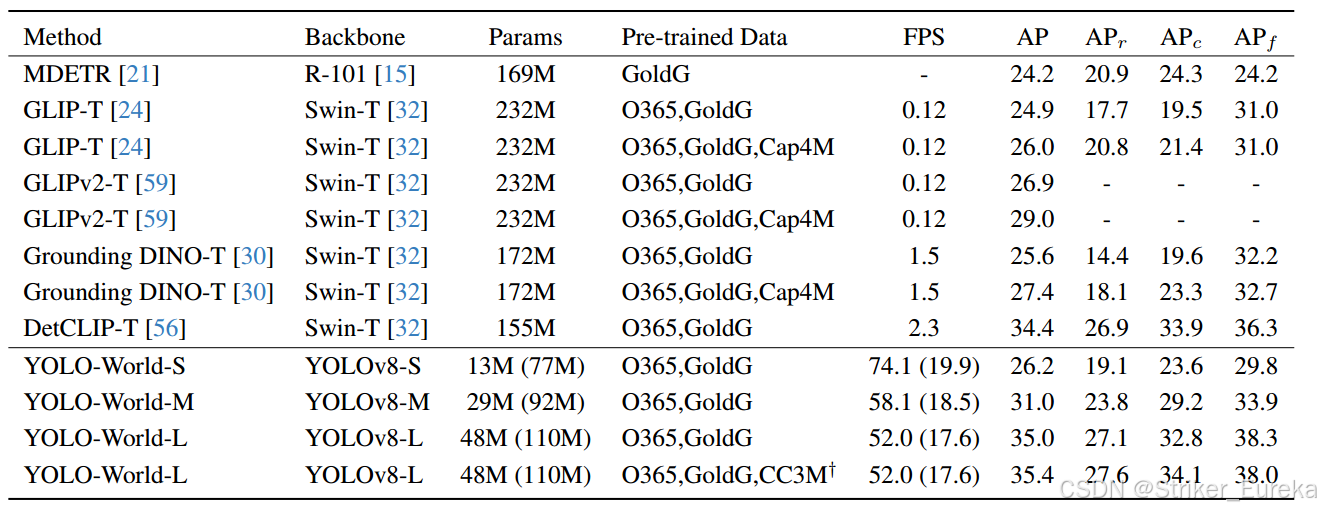
可以看出来YOLOWorld不仅参数量小而且速度非常快,准确率也很高。
六. 论文效果复现
可以直接使用官方训练好的模型看看效果:
from ultralytics import YOLO
# Initialize a YOLO-World model
model = YOLO('yolov8s-world.pt') # or choose yolov8m/l-world.pt
# Define custom classes
model.set_classes(["person", "car","bus"])
# Execute prediction for specified categories on an image
results = model.predict('test.jpeg')
# Show results
results[0].show()结果如下:


















 54
54

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









