






一、前期预备
下载cuda11.3链接:
CUDA Toolkit 11.3 Downloads | NVIDIA Developer
下载cudnn8.2.0链接:
cuDNN Archive | NVIDIA Developer
从pytorch1.11.0、cuda11.3、python的对应关系来看,应该选择python3.7~3.10之间的版本,这里选择python3.8
https://blog.csdn.net/qq_41946216/article/details/129476095
创建虚拟环境
conda create -n yoloworld python=3.8下载pytorch1.11.0(Previous PyTorch Versions | PyTorch)
# CUDA 11.3
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3 -c pytorch根据requirements文件夹下的txt文件进行环境包配置
pip install -r requirements/basic_requirements.txtpip install -r requirements/demo_requirements.txtpip install -r requirements/onnx_requirements.txt下载模型(之后没用到,仅提供一个下载链接)
二、开始跑代码
问题1:
直接跑demo下的image_demo.py会报错

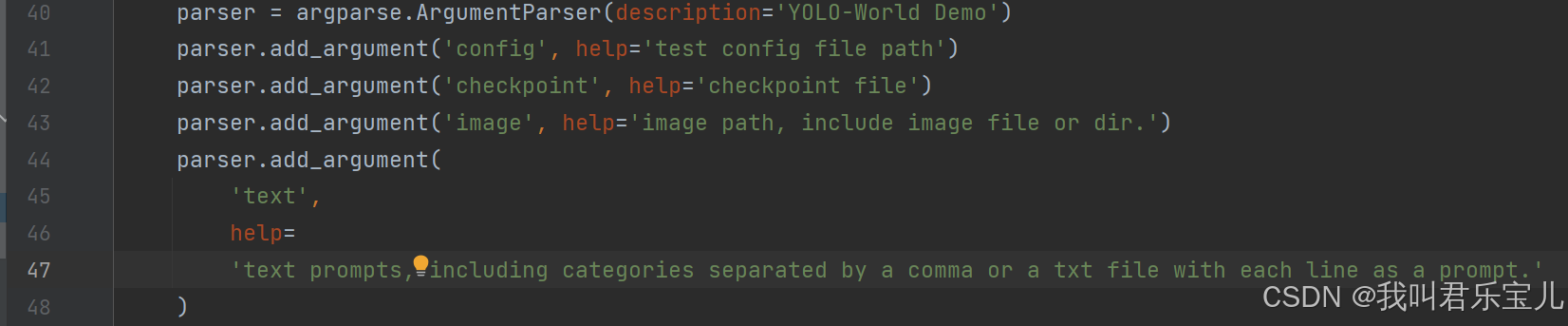
查询https://blog.csdn.net/weixin_45912366/article/details/124071014 得知配置参数的时候需要加--,于是在如下代码中加上--
加入前:
加入后:
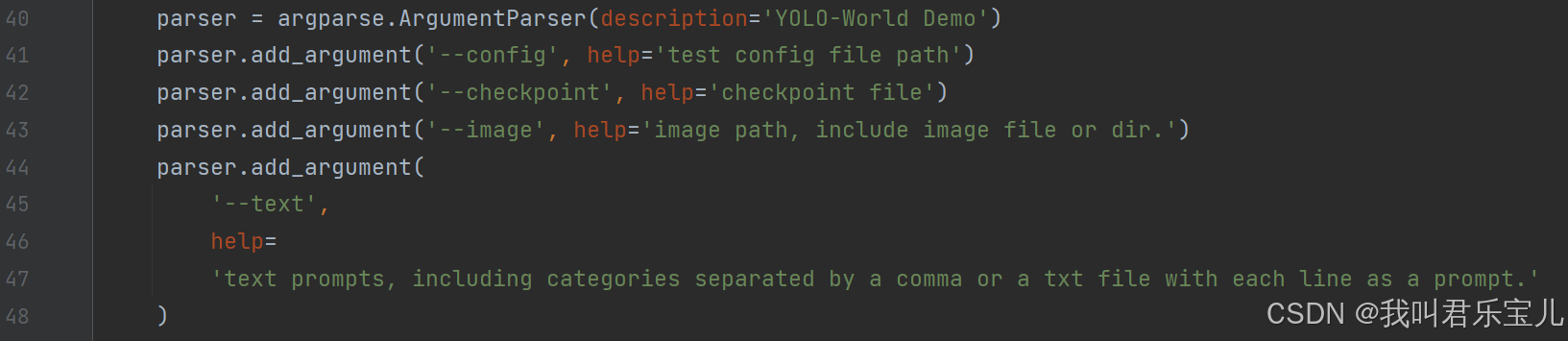
问题二:
接着又遇到了下一个错误

加入断点发现filename无内容
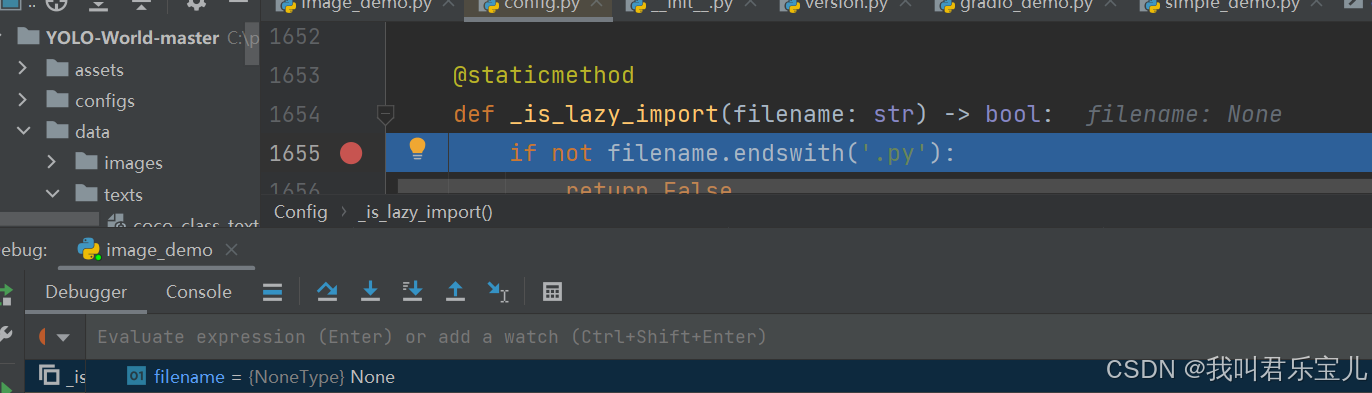
问题三:
运行simple_demo文件时出现错误:
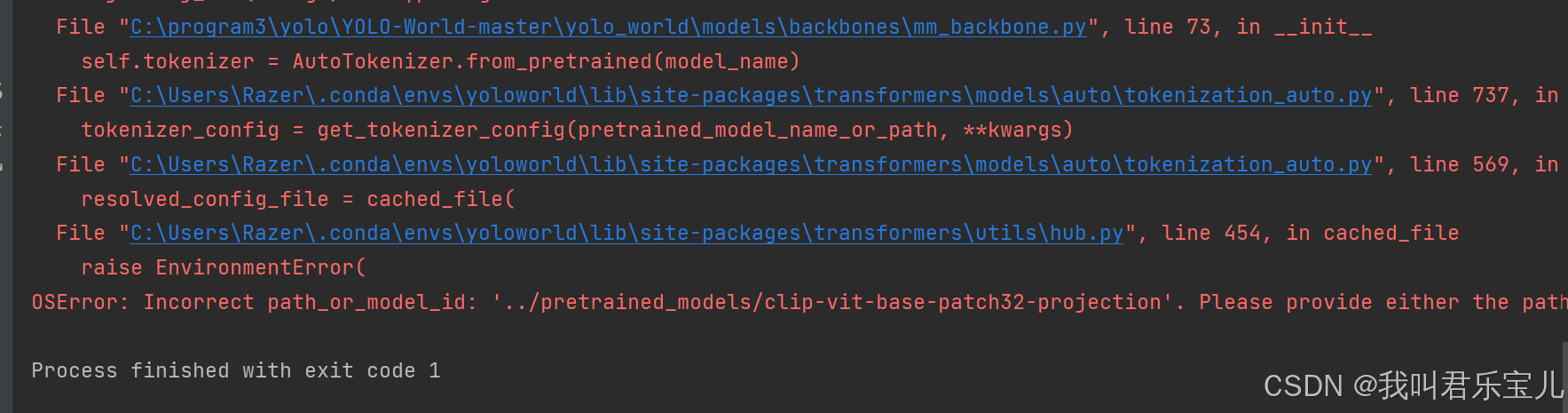
查找相关资料得知OSError: Incorrect path_or_model_id: '../pretrained_models/clip-vit-base-patch32-projection'. Please provide either the path to a local folder or the repo_id of a model on the Hub. · Issue #358 · AILab-CVC/YOLO-World · GitHub https://github.com/AILab-CVC/YOLO-World/issues/358需要将configs/pretrain/文件下的yolo_world_v2_x_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py
https://github.com/AILab-CVC/YOLO-World/issues/358需要将configs/pretrain/文件下的yolo_world_v2_x_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py
text_model_name = '../pretrained_models/clip-vit-base-patch32-projection'改为
text_model_name = 'openai/clip-vit-base-patch32'问题四:
再次运行simple_demo.py出现以下问题,提示不能访问该网站
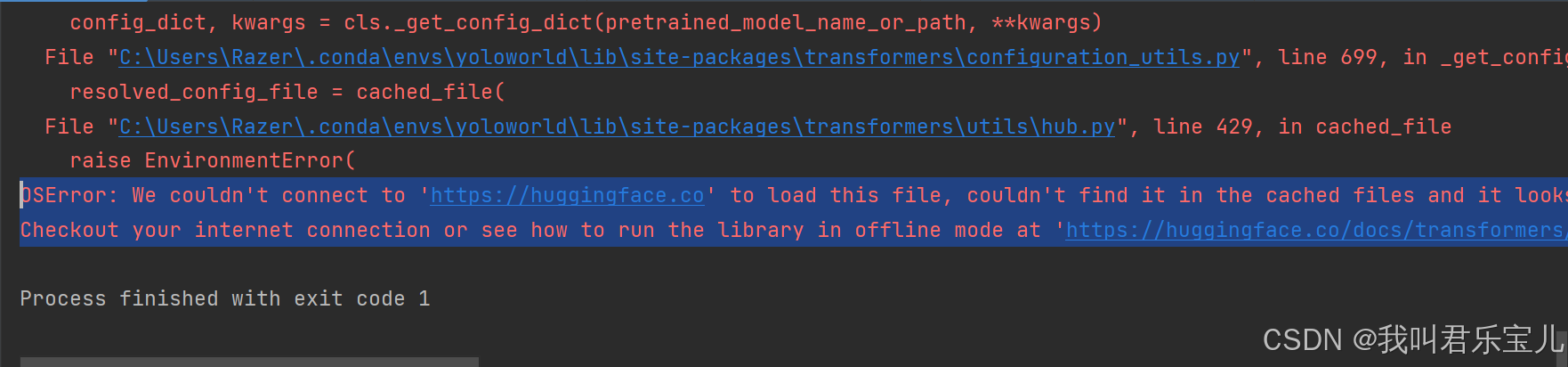
据相关资料(https://blog.csdn.net/mar1111s/article/details/137179180)说目前hugggingface.co在中国境内无法正常访问,于是在使用transformer前引入两条语句
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"放在simple_demo.py文件中即可
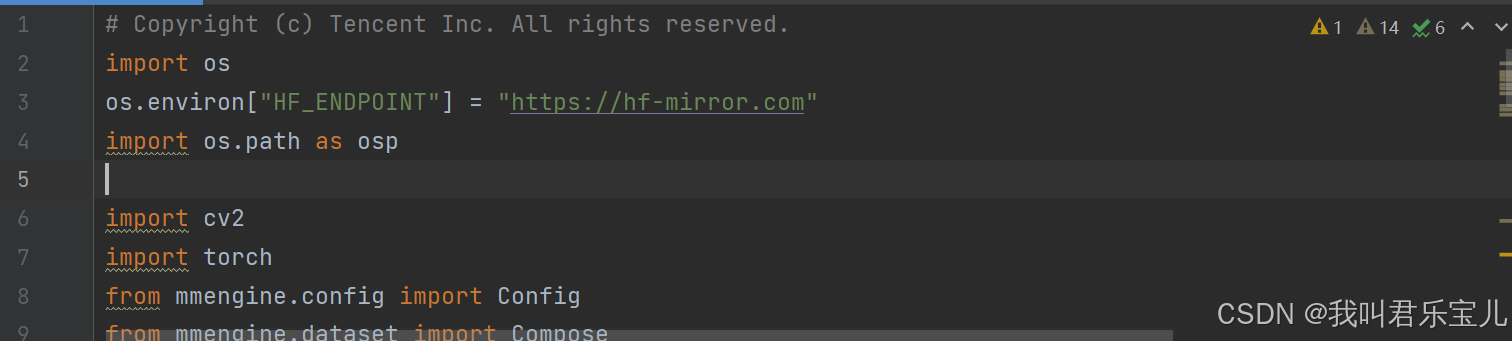
但是这种方式对我来说不起作用
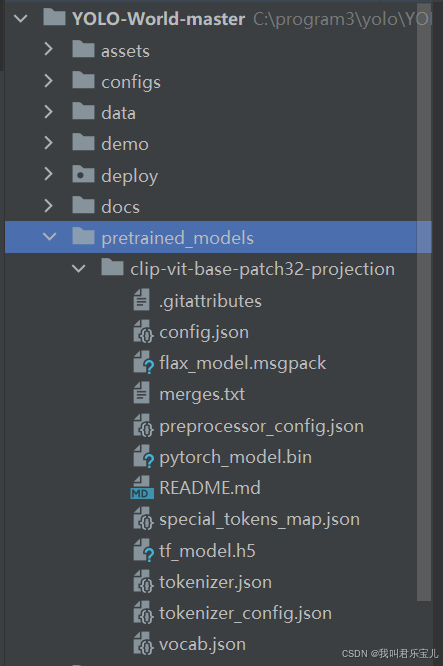
我是用以下方式解决的:离线下载
先找到需要的文件 clip-vit-base-patch32
openai/clip-vit-base-patch32 - Gitee AIhttps://ai.gitee.com/hf-models/openai/clip-vit-base-patch32/tree/main克隆下载(需要安装git)
git lfs install
git clone https://ai.gitee.com/hf-models/clip-vit-base-patch32在项目总文件夹下建立一个新文件夹 pretrained_models,将下载好的文件放进去
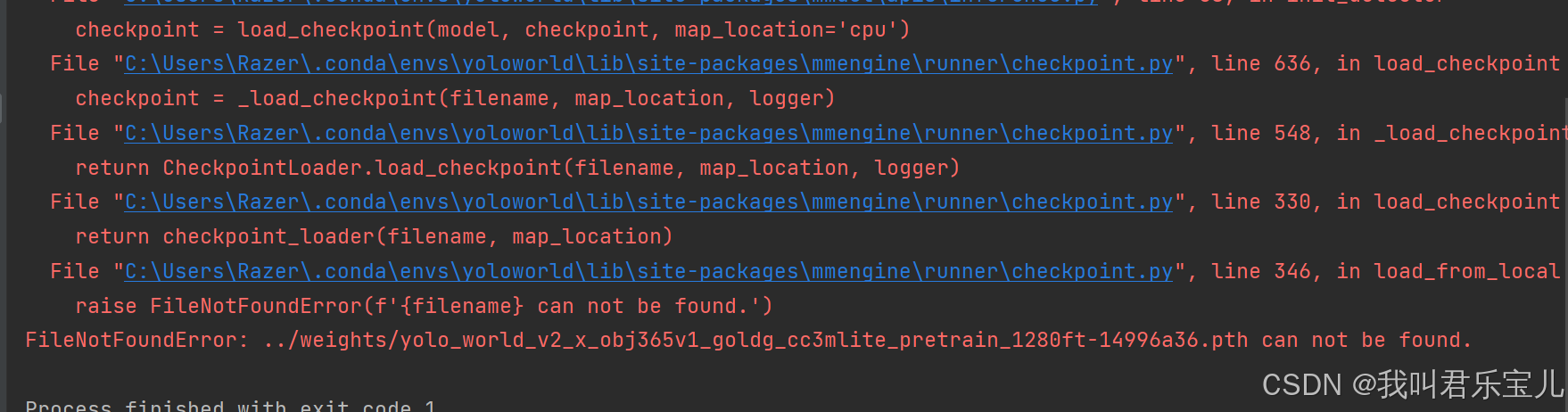
问题五:
遇到了新的问题,缺少这样一个权重文件,需要去官方下载

问题六:
遇到了新的问题,提示需要下载lvis数据集

按照提示下载
GitHub - lvis-dataset/lvis-api: Python API for LVIS Datasethttps://github.com/lvis-dataset/lvis-api
pip install git+https://github.com/lvis-dataset/lvis-api.git问题七:
遇到了新的问题
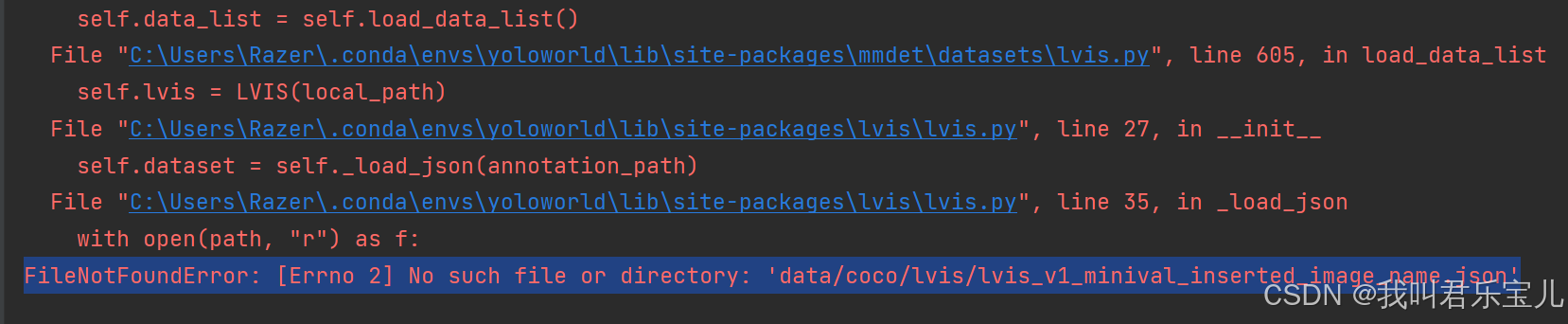
去到官方下载json文件
将json文件放到demo/data/coco/lvis下
此外还有一个小问题,需要把主目录下的data/texts文件夹放到demo/data下
问题八:
小问题又出现了,但是看起来快成功了,提示没有找到这张图片
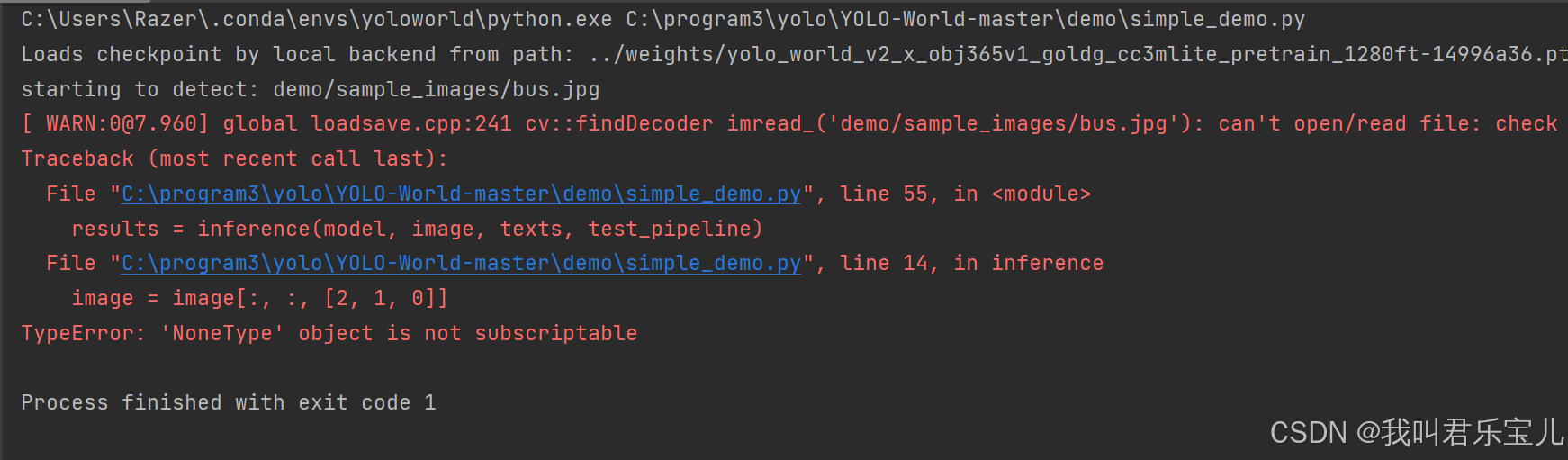
只需要改一下52行即可,是图片的相对位置不对

阶段成果1:
运行simple_demo
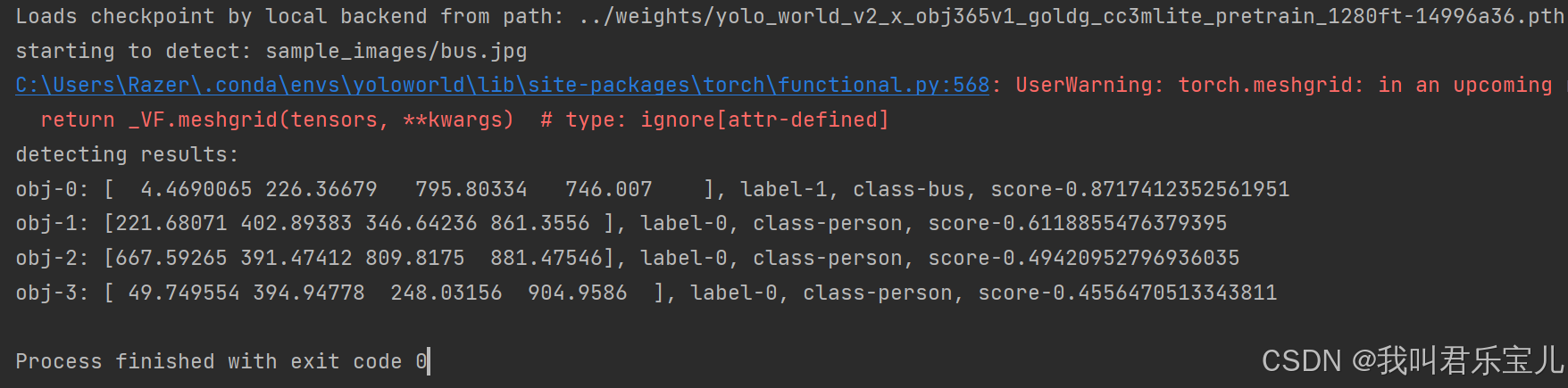
这里识别出了四个物体,数组里的数字是左上角和右下角坐标
这里的demo代码没有在原图上绘制置信框,将源代码改写一下得到可视化结果


simple_demo.py更改后的可运行代码如下:
# Copyright (c) Tencent Inc. All rights reserved.
import os
import os.path as osp
import cv2
import torch
from mmengine.config import Config
from mmengine.dataset import Compose
from mmdet.apis import init_detector
from mmdet.utils import get_test_pipeline_cfg
def inference(model, image, texts, test_pipeline, score_thr=0.3, max_dets=100):
image = cv2.imread(image)
image = image[:, :, [2, 1, 0]]
data_info = dict(img=image, img_id=0, texts=texts)
data_info = test_pipeline(data_info)
data_batch = dict(inputs=data_info['inputs'].unsqueeze(0),
data_samples=[data_info['data_samples']])
with torch.no_grad():
output = model.test_step(data_batch)[0]
pred_instances = output.pred_instances
# score thresholding
pred_instances = pred_instances[pred_instances.scores.float() > score_thr]
# max detections
if len(pred_instances.scores) > max_dets:
indices = pred_instances.scores.float().topk(max_dets)[1]
pred_instances = pred_instances[indices]
pred_instances = pred_instances.cpu().numpy()
boxes = pred_instances['bboxes']
labels = pred_instances['labels']
scores = pred_instances['scores']
label_texts = [texts[x][0] for x in labels]
return boxes, labels, label_texts, scores
if __name__ == "__main__":
config_file = "../configs/pretrain/yolo_world_v2_x_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py"
checkpoint = "../weights/yolo_world_v2_x_obj365v1_goldg_cc3mlite_pretrain_1280ft-14996a36.pth"
cfg = Config.fromfile(config_file)
cfg.work_dir = osp.join('./work_dirs')
# init model
cfg.load_from = checkpoint
model = init_detector(cfg, checkpoint=checkpoint, device='cuda:0')
test_pipeline_cfg = get_test_pipeline_cfg(cfg=cfg)
test_pipeline_cfg[0].type = 'mmdet.LoadImageFromNDArray'
test_pipeline = Compose(test_pipeline_cfg)
texts = [['person'], ['bus'], [' ']]
# image = "demo/sample_images/bus.jpg"
image = "sample_images/bus.jpg"
print(f"starting to detect: {image}")
results = inference(model, image, texts, test_pipeline)
format_str = [
f"obj-{idx}: {box}, label-{lbl}, class-{lbl_text}, score-{score}"
for idx, (box, lbl, lbl_text, score) in enumerate(zip(*results))
]
print("detecting results:")
for q in format_str:
print(q)
# 加载图片
image = cv2.imread(image)
# 解析结果
boxes, labels, class_names, scores = results
# 绘制框、标签和置信度
for box, class_name, score in zip(boxes, class_names, scores):
x_min, y_min, x_max, y_max = map(int, box)
# 绘制矩形框
cv2.rectangle(image, (x_min, y_min), (x_max, y_max), (0, 255, 0), 2)
# 准备文本
label_text = f'{class_name} ({score:.2f})'
# 计算文本位置
text_size, _ = cv2.getTextSize(label_text, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
text_x = x_min
text_y = y_min - 10 if y_min - 10 > 10 else y_min + text_size[1] + 10
# 绘制文本背景
cv2.rectangle(image, (text_x, text_y - text_size[1] - 10), (text_x + text_size[0], text_y + 10), (0, 255, 0),
-1)
# 绘制文本
cv2.putText(image, label_text, (text_x, text_y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1)
# 创建输出目录(如果不存在)
output_dir = 'out'
os.makedirs(output_dir, exist_ok=True)
# 输出文件路径
output_path = os.path.join(output_dir, 'output_image.jpg')
# 保存图像
cv2.imwrite(output_path, image)
问题九:
运行启动脚本dist_test.py
python ./tools/dist_test.py --config=configs/pretrain/yolo_world_v2_m_vlpan_bn_2e-3_10
0e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py --checkpoint=weights/yolo_world_v2_m_obj365v1_goldg_pretrain_1280ft-77d0346d.p
th --gpus=1分布式部分出现错误,一个GPU不需要进行分布式
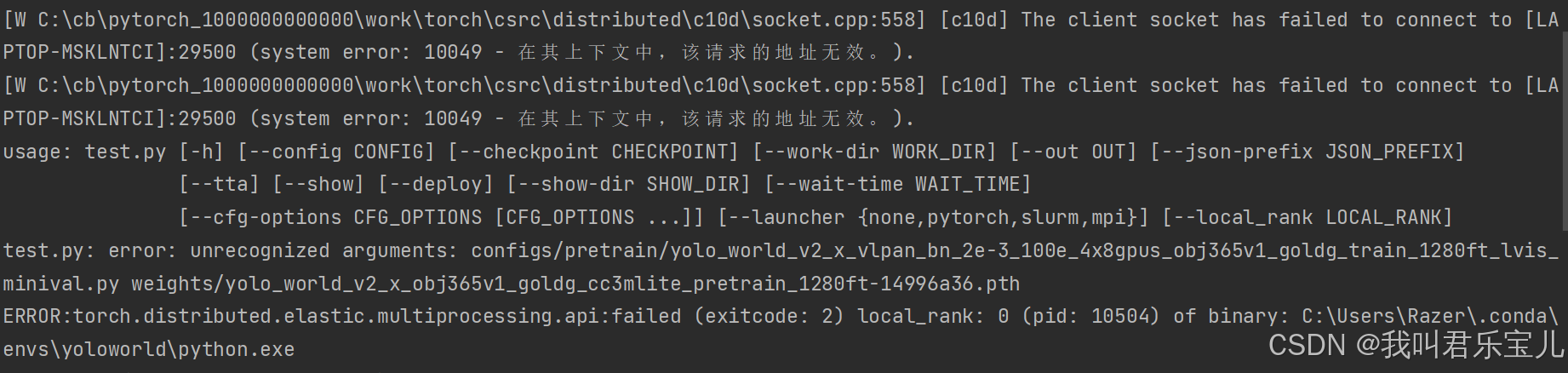
将
command = [
'python', '-m', 'torch.distributed.launch',
f'--nnodes={nnodes}',
f'--node_rank={node_rank}',
f'--master_addr={master_addr}',
f'--nproc_per_node={gpus}',
f'--master_port={port}',
os.path.join(script_dir, 'test.py'),
config,
checkpoint,
'--launcher', 'pytorch'
] + sys.argv[4:]改为
command = [
'python', os.path.join(script_dir, 'test.py'),
config,
checkpoint
] + sys.argv[4:]问题十:
环境变量问题,找不到yolo_world的module
将yolo_world的文件夹加入到环境变量中(在启动文件dist_test.py)
# 获取脚本的当前目录
script_dir = os.path.dirname(os.path.abspath(__file__))
# 设置 PYTHONPATH 环境变量
# 计算 yolo_world 的路径
custom_module_path = os.path.join(script_dir, '..', 'yolo_world')
# 获取当前的 PYTHONPATH 环境变量
current_pythonpath = os.getenv('PYTHONPATH', '')
# 更新 PYTHONPATH 环境变量
pythonpath = f"{custom_module_path}{os.pathsep}{current_pythonpath}"
os.environ['PYTHONPATH'] = pythonpath
# 验证设置
print("PYTHONPATH:", os.environ['PYTHONPATH'])问题十一:
提示这个权重文件下载不了,这是之前的问题
需要将配置文件
yolo_world_v2_m_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py
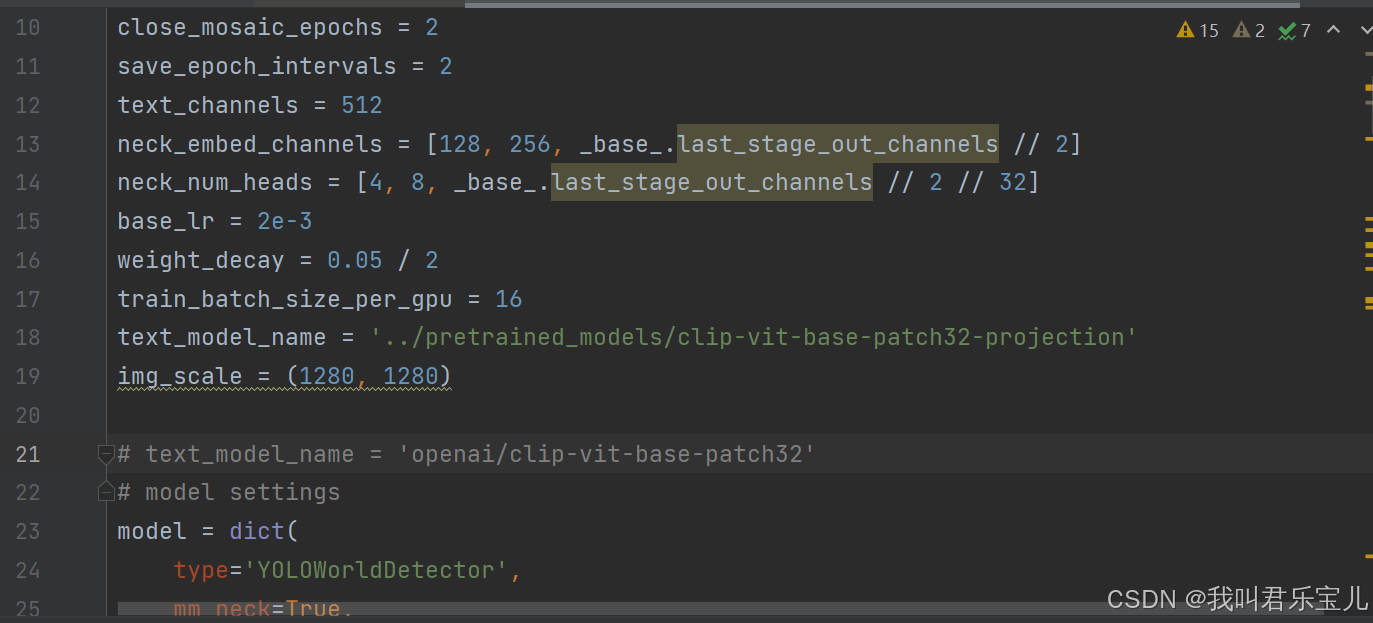
第21行注释掉,之前已经下好pretrained_models了
问题十二:
还是之前的问题
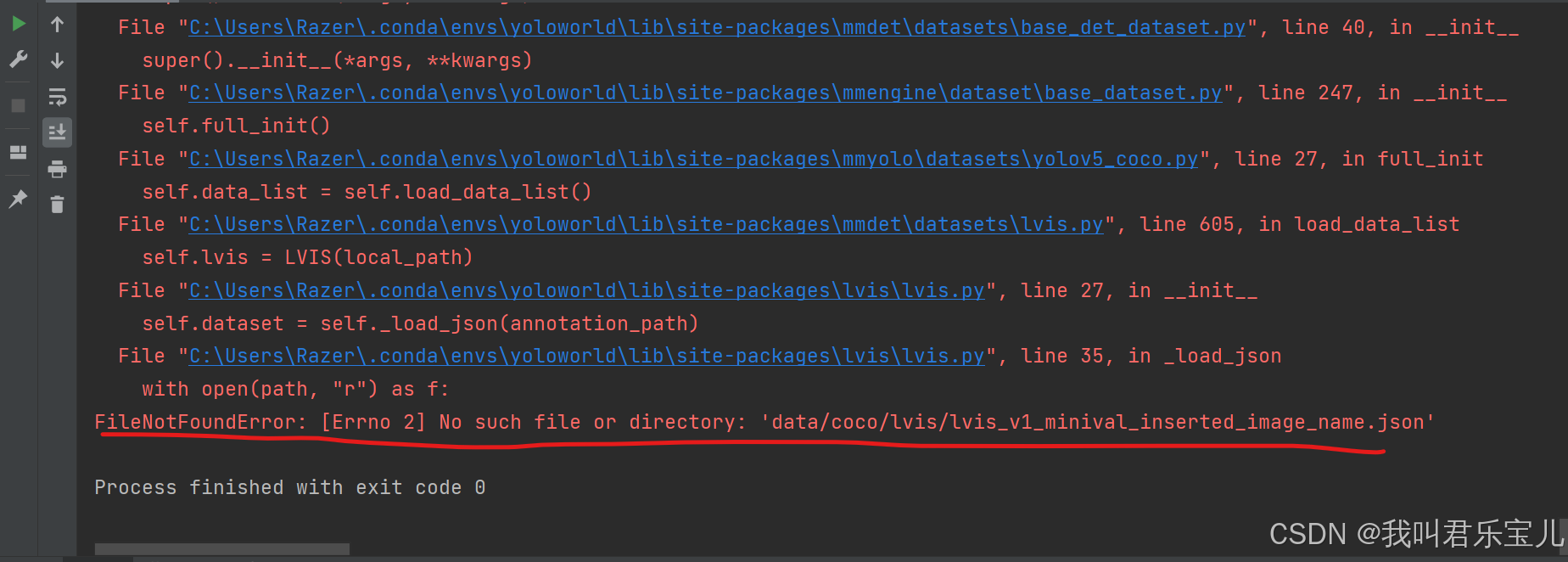
提示缺少这个json文件
将这个json文件连同整个data放在tools文件夹中即可
问题解决
问题十三:
出现了新的问题
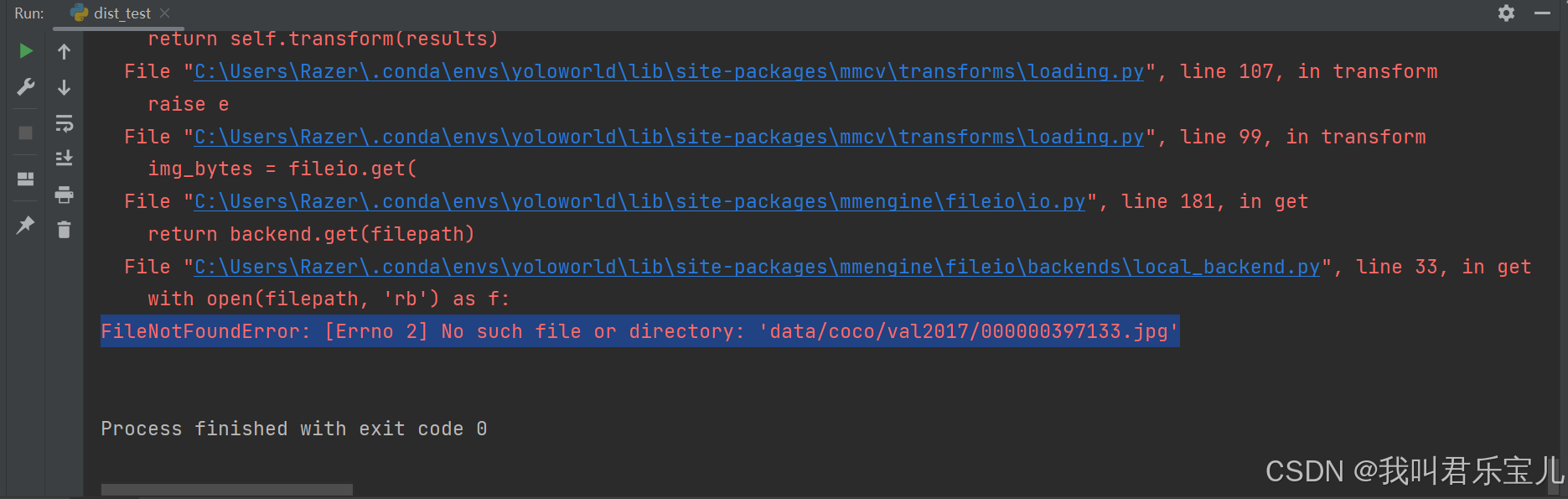
提示没有coco数据集,思考是之前下载忘记下载数据集的缘故
Dataset之COCO数据集:COCO数据集的简介、下载、使用方法之详细攻略-CSDN博客https://blog.csdn.net/qq_41185868/article/details/82939959下载coco数据集val2017
将数据集放在tools/data/coco文件夹下
评估结果
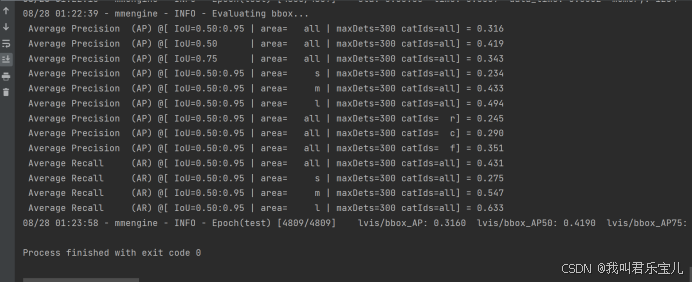
08/28 01:23:58 - mmengine - INFO - Epoch(test) [4809/4809] lvis/bbox_AP: 0.3160 lvis/bbox_AP50: 0.4190 lvis/bbox_AP75: 0.3430 lvis/bbox_APs: 0.2340 lvis/bbox_APm: 0.4330 lvis/bbox_APl: 0.4940 lvis/bbox_APr: 0.2450 lvis/bbox_APc: 0.2900 lvis/bbox_APf: 0.3510 data_time: 0.0019 time: 0.6207问题十四:
在执行tools/dist_train.py文件时,出现以下错误

提示预训练模型路径错误
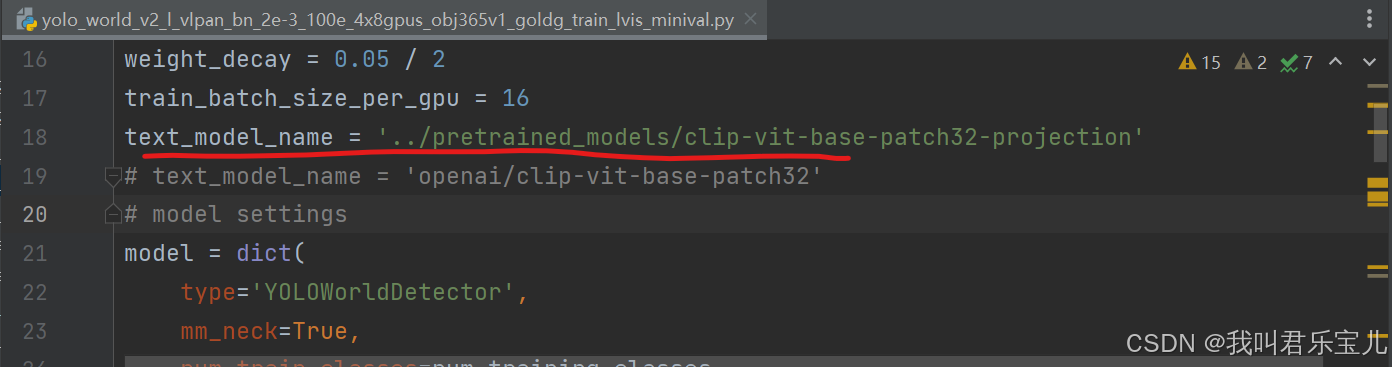
将对应配置文件的路径改为
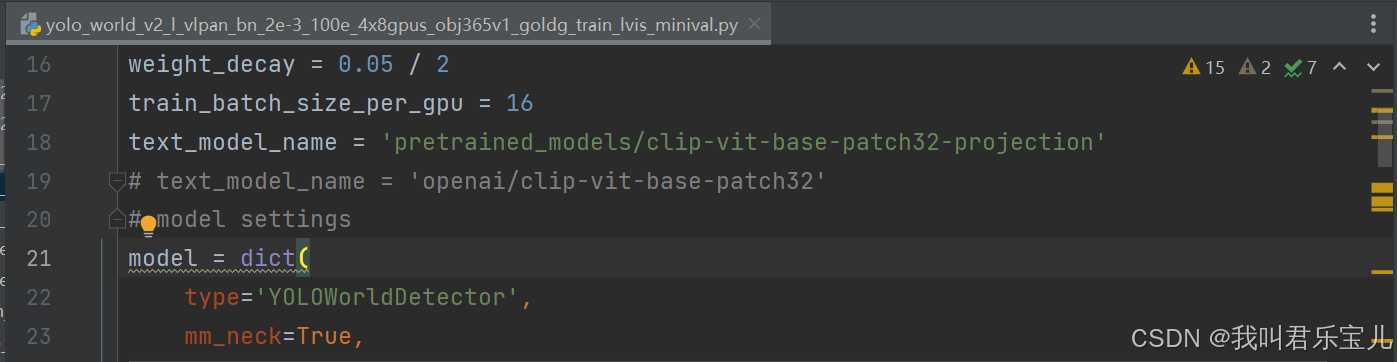
问题解决
问题十五:
出现了新的问题
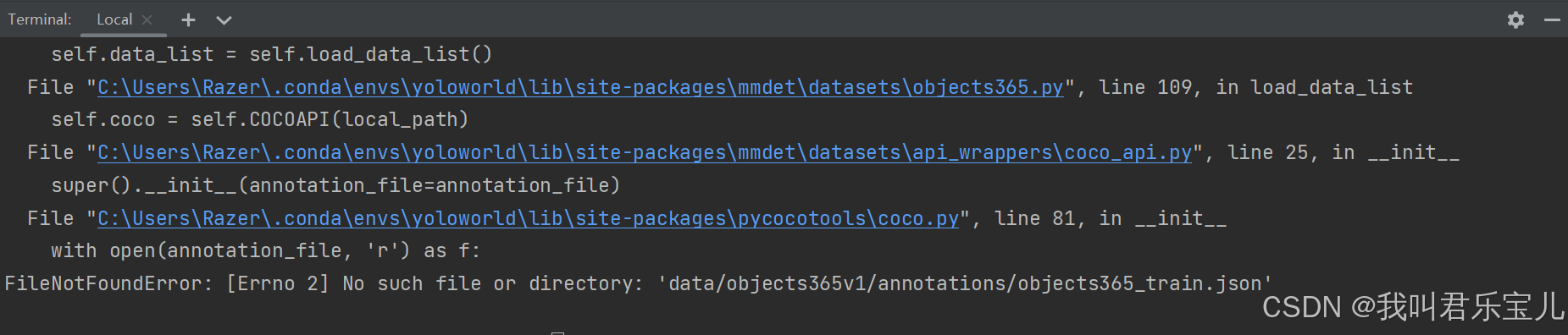
提示缺少训练的文件,去官方下载对应的数据文件
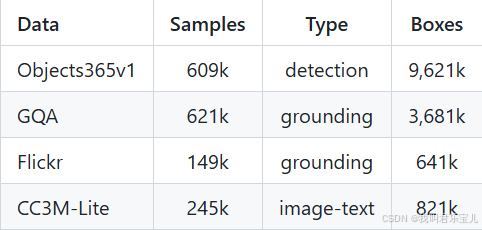

o365的annotations:
o365的data:
数据集-OpenDataLabhttps://opendatalab.com/OpenDataLab/Objects365_v1/tree/maingqa的data:
GQAhttps://nlp.stanford.edu/data/gqa/images.zipgqa的annotations:
Flickr30k图像标注数据集下载及使用方法_flickr30k下载-CSDN博客https://blog.csdn.net/gaoyueace/article/details/80564642flickr的annotations:
COCO - Common Objects in Context (cocodataset.org)https://cocodataset.org/#downloadcoco的annotations:
问题十六:
在训练过程中,出现以下问题

查询资料得到解决方法
再修改配置文件的batch_size为2
重启计算机,即可开始训练
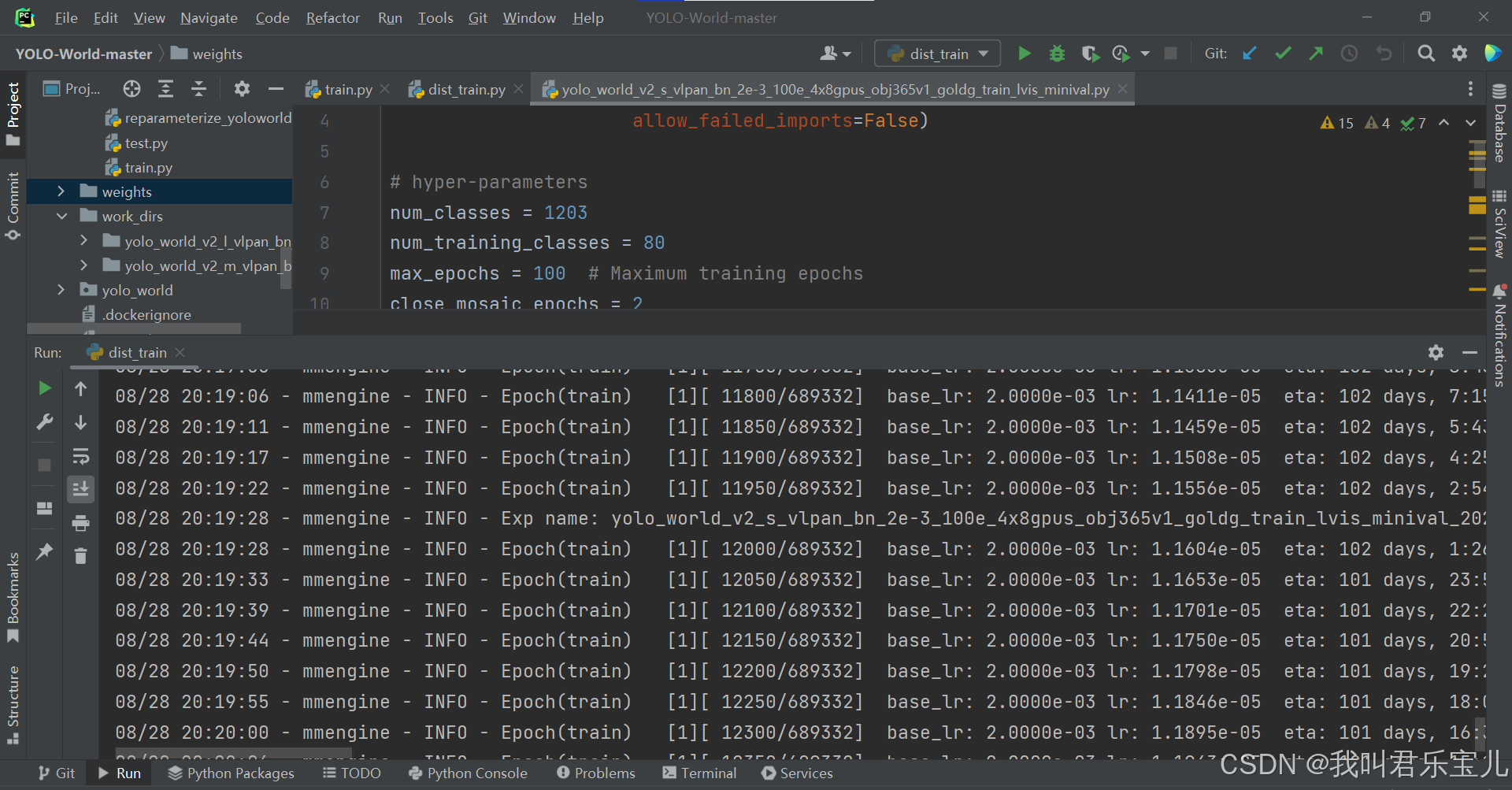
三、数据集问题
yoloworld的验证部分在lvis数据集上推理得到
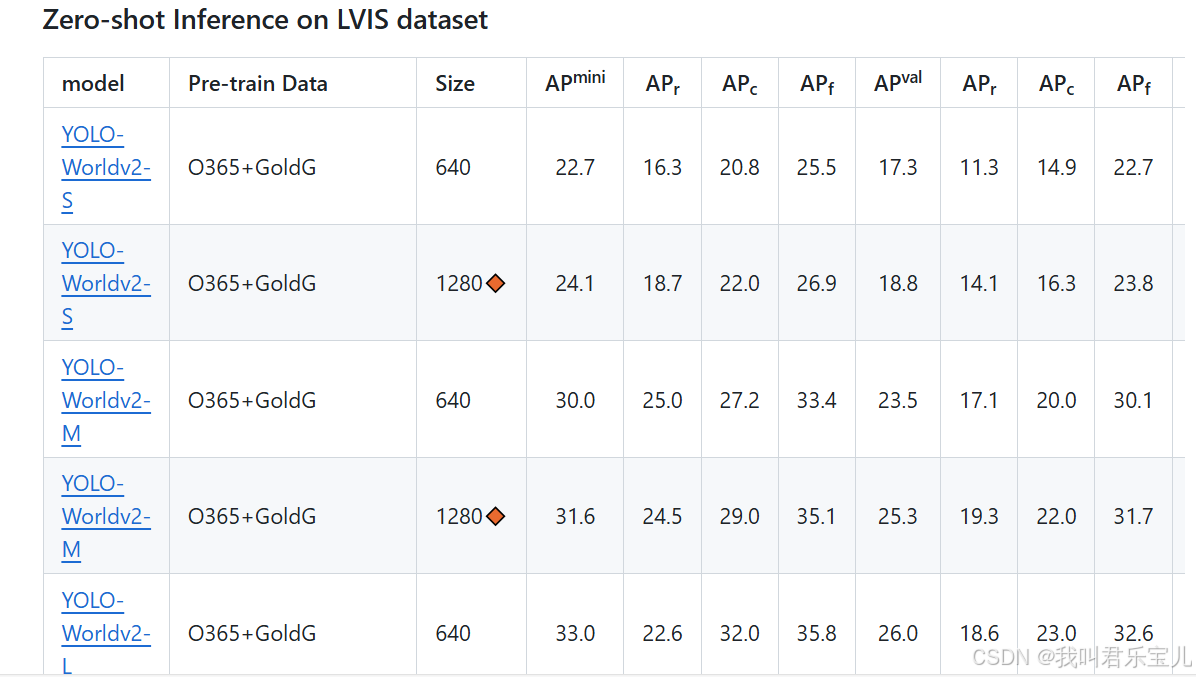

评估模型时,使用了LVIS_Minival数据集

四、代码部分
test.py
首先看yolo_world.py的
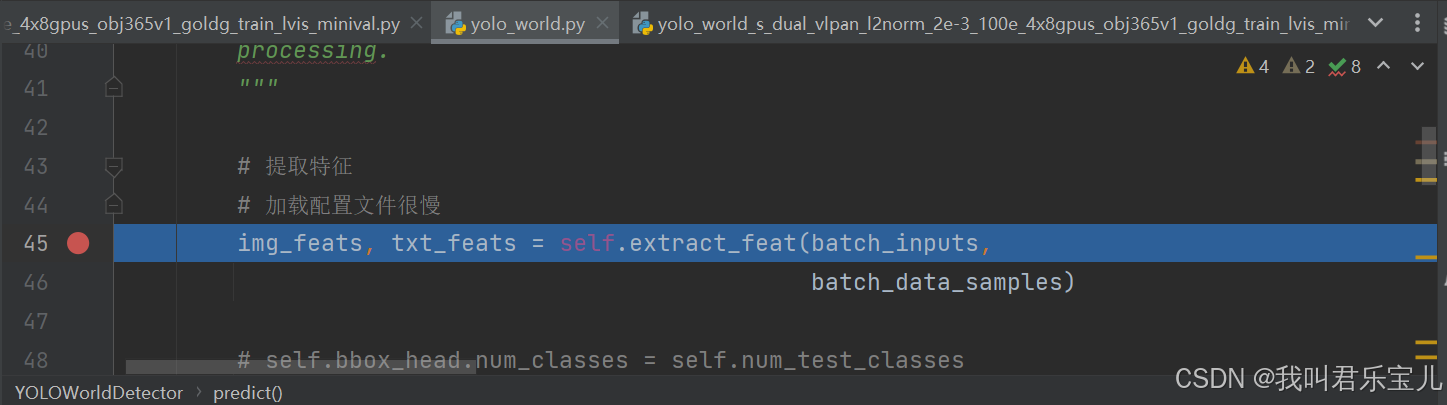
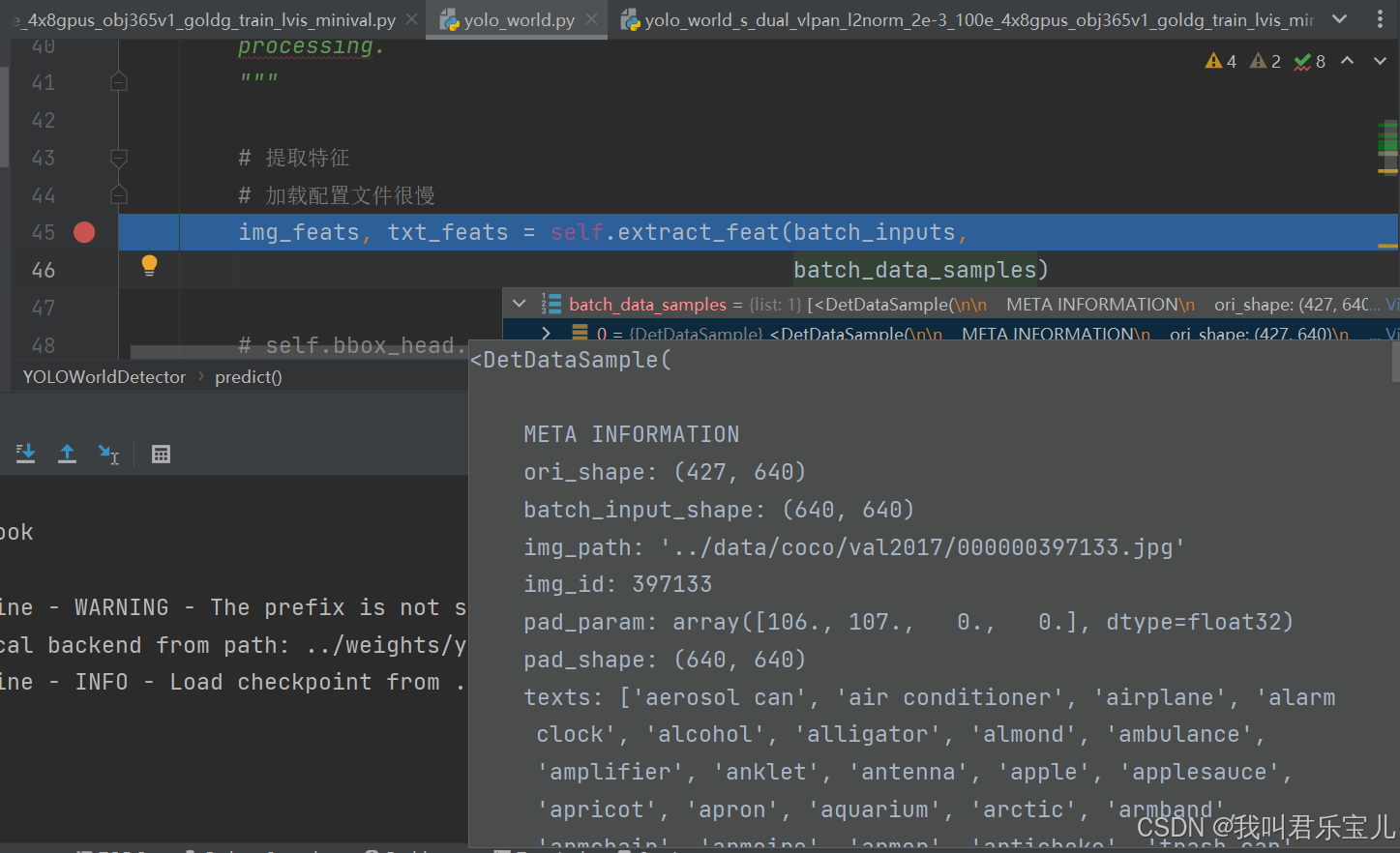
里面有两个数据
一个是预处理之后的图像数据batch_inputs,一个是barch_data_samples文本预处理数据,text处即为文本
进入backbone部分
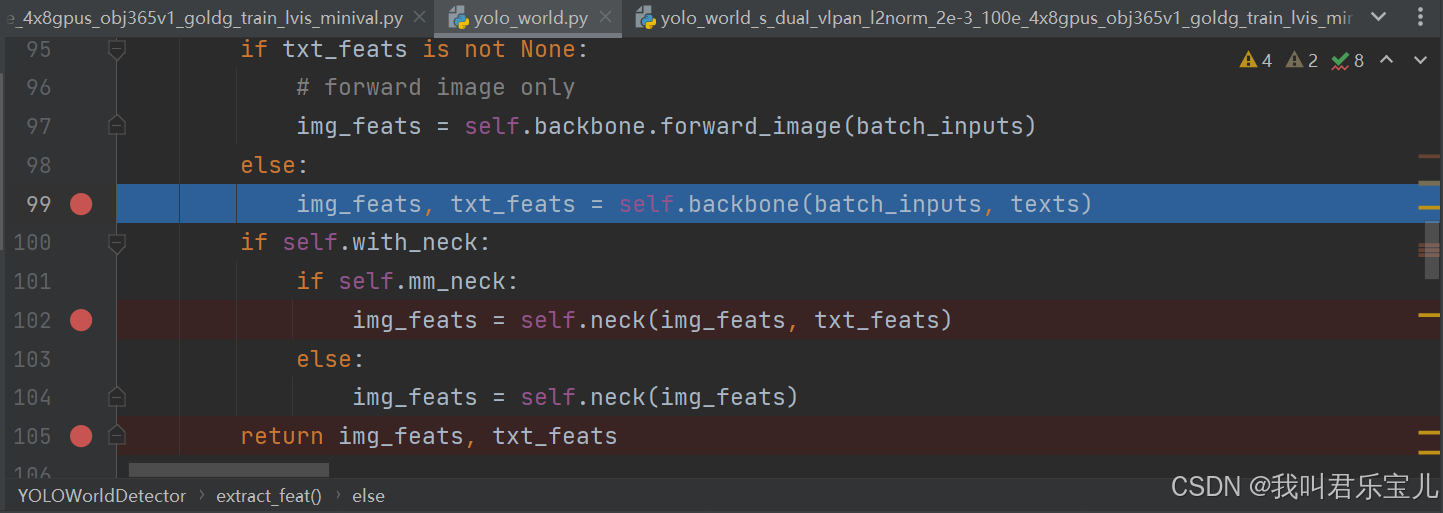
这里要走两个backbone(这部分负责特征提取),一个是yolov8(和yolov7差不多)的,一个是text clip encoder的
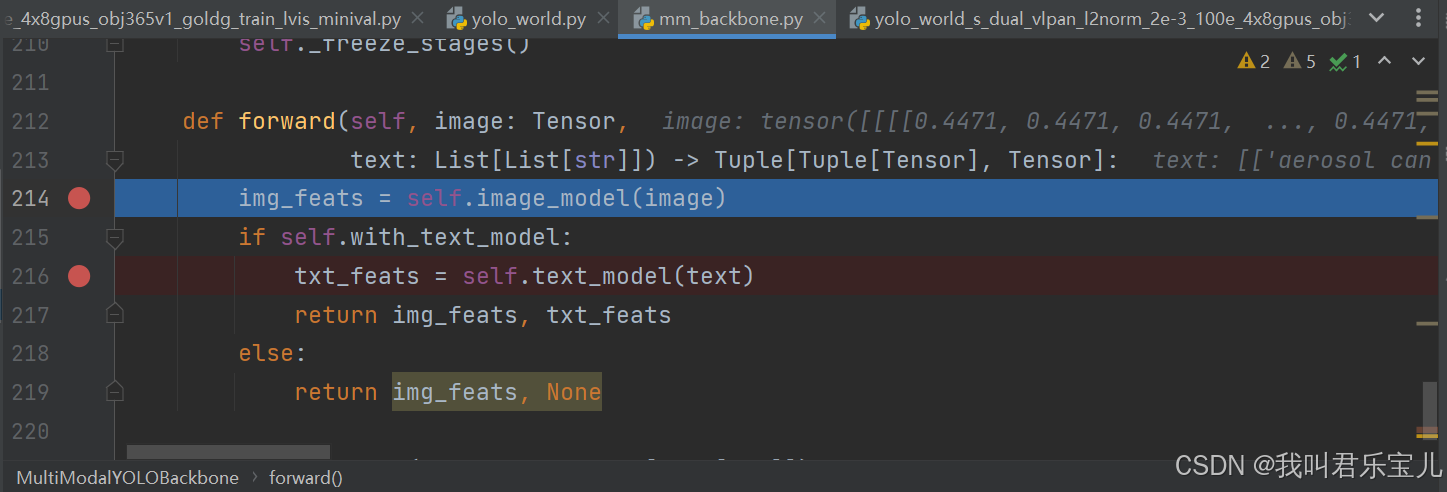
图像部分经过yolov8 backbone得到一个多层级特征(分别是80、40、20)
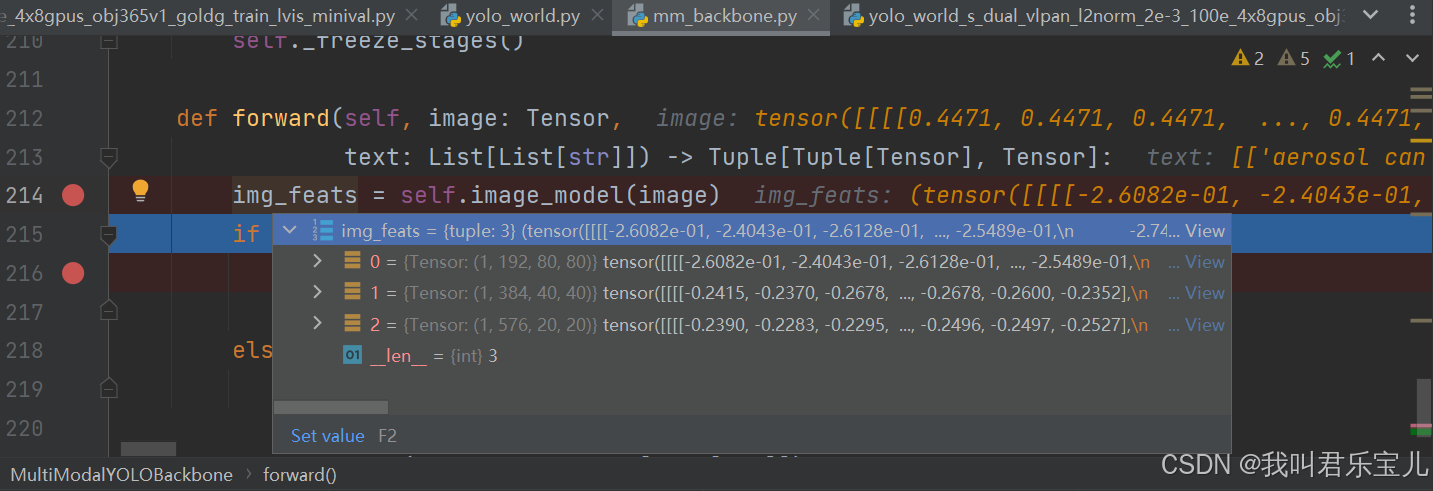
text部分有这些提示词
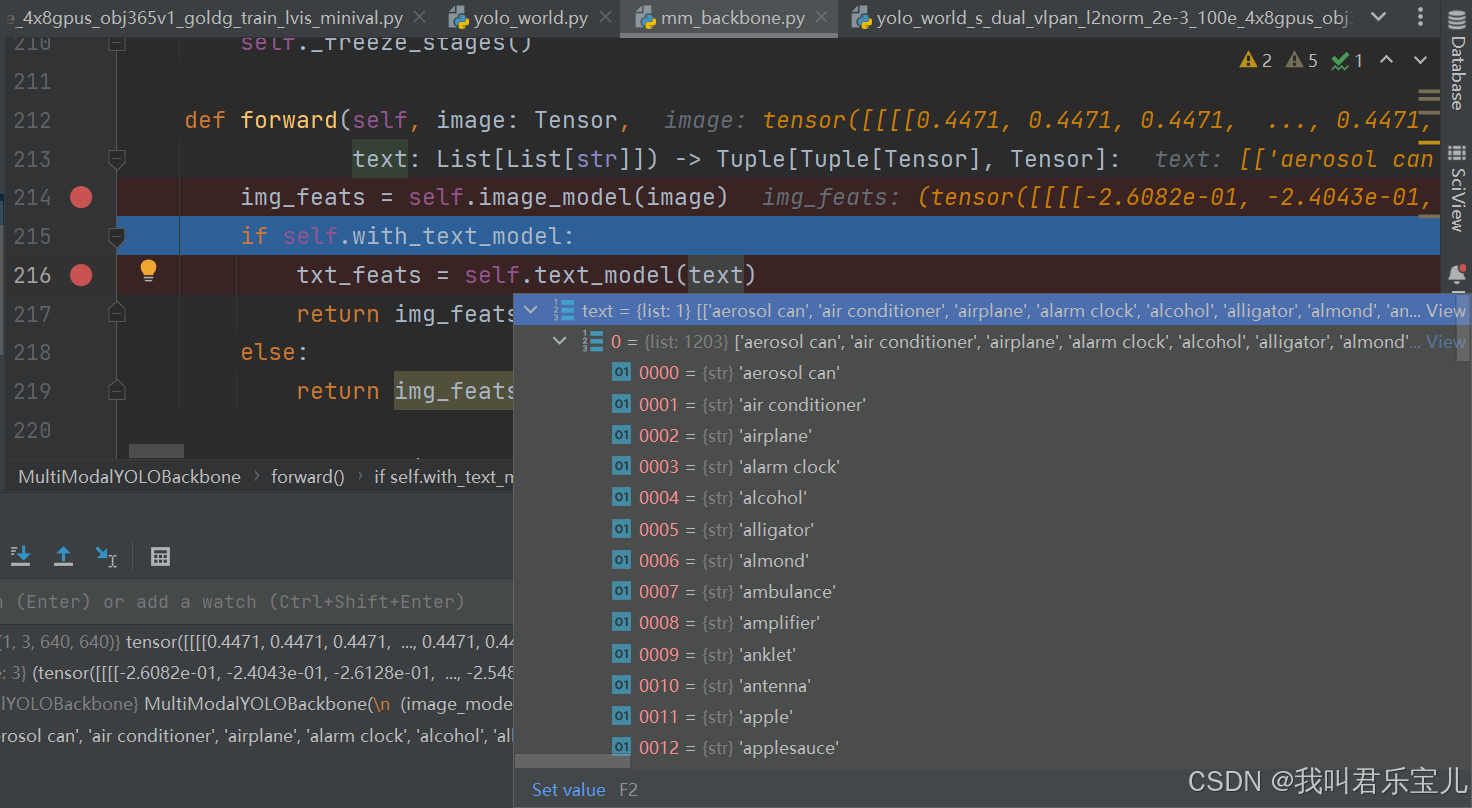
在提取text特征部分,先分词tokenizer,无论是输入的是词语还是句子,先分词
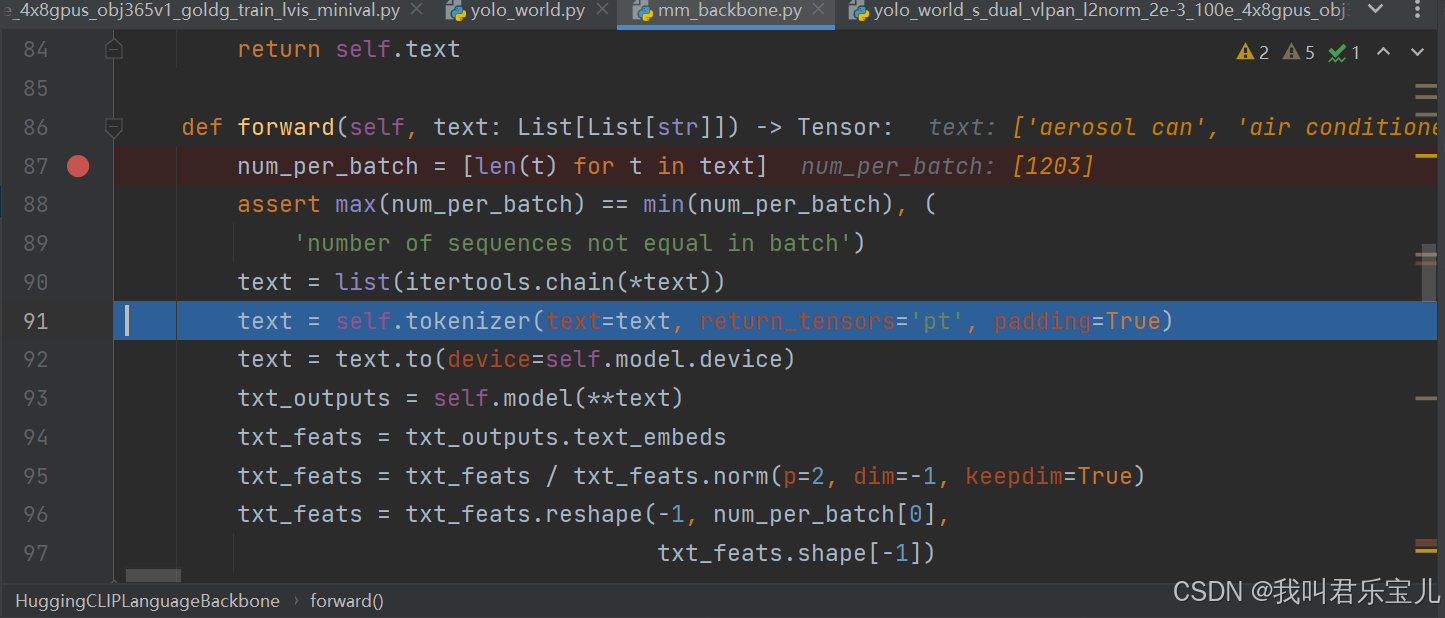
把文本切成每个token,每个词的起始位置49406和终止位置49407是一样的

分好的词传入预训练模型CLIPTextModel,这个预训练模型中一共有不重复的词49408个,把每个词映射成了512维的向量
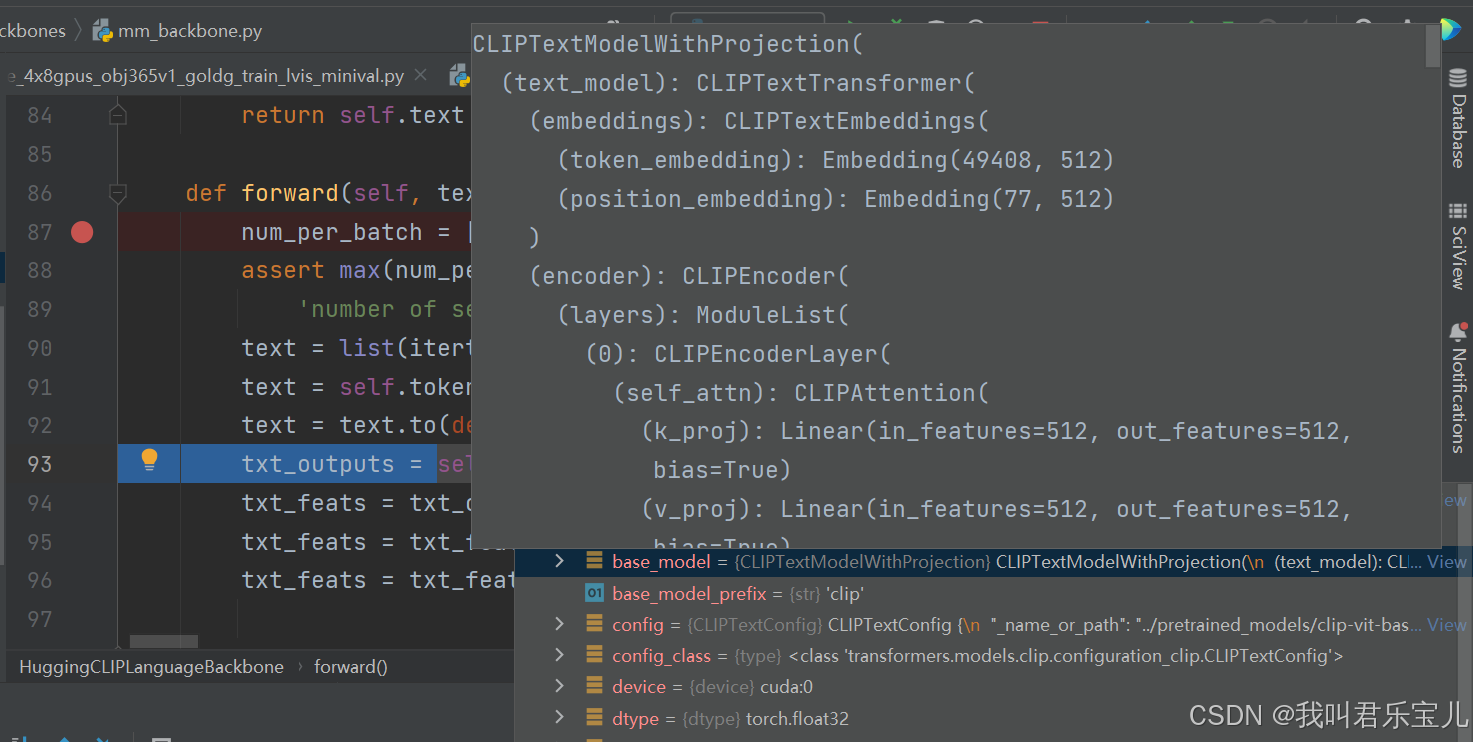
input_shape是1203*6的矩阵,输入的是1203个词语或句子,每个词语或者句子用四个id来表示
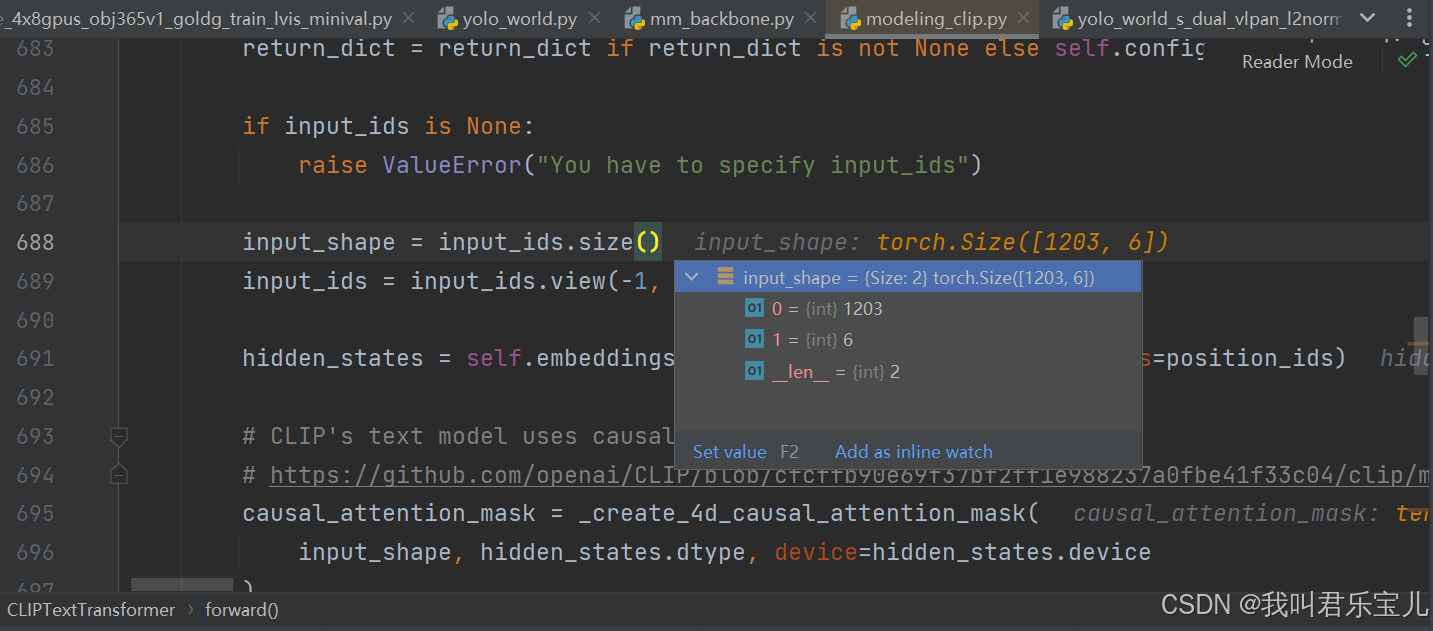
然后去找对应的512维embedding向量,将向量拿到手
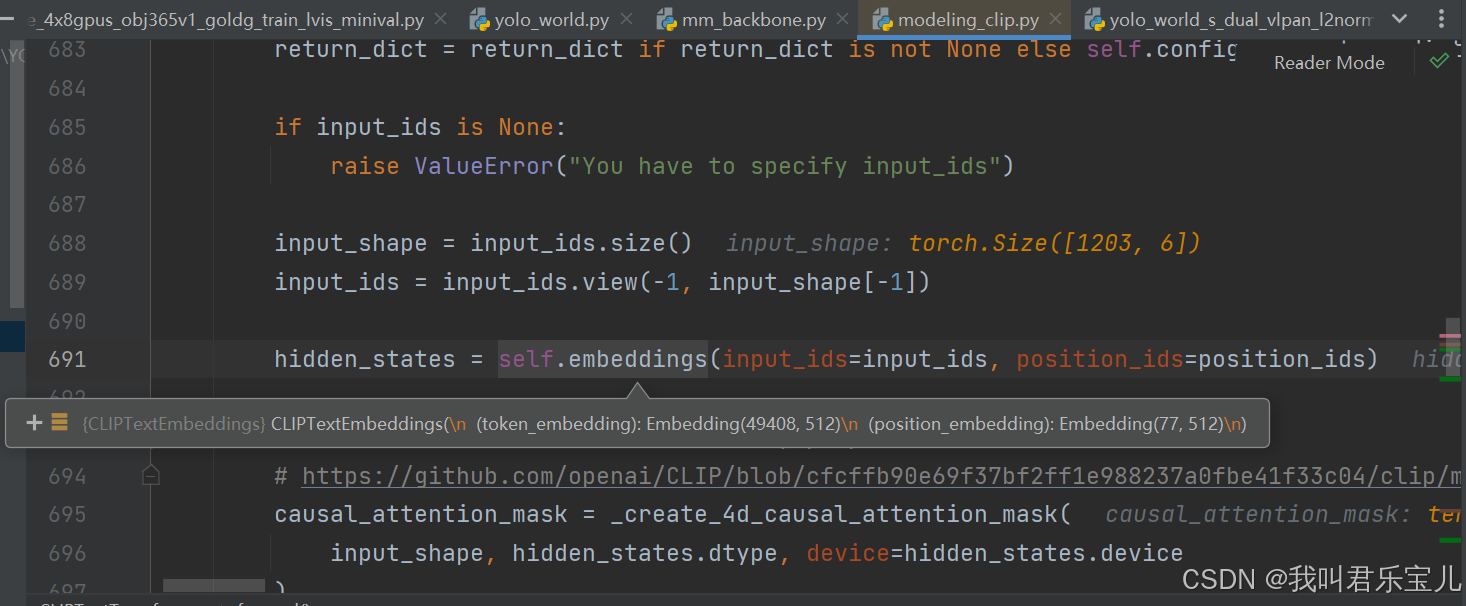
hidden_states即为找到对应的embedding的词语矩阵

这里是取最大的一个向量

汇总的一个向量,现在一共有1203个句子,每个句子有512个向量

得到文本的特征编码
当前,图像的文本特征有3个层级,文本是1x1203x512向量,将每一个词映射成一个向量,融合成一个特征
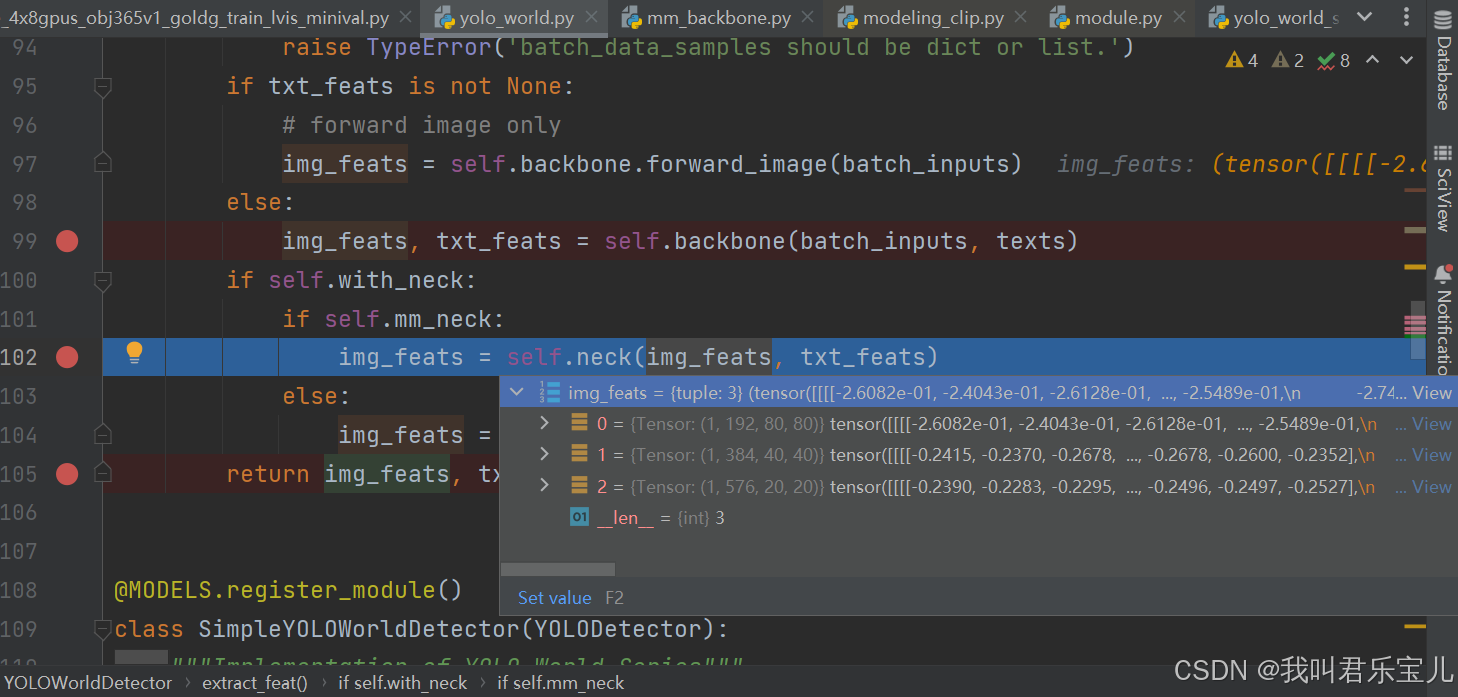
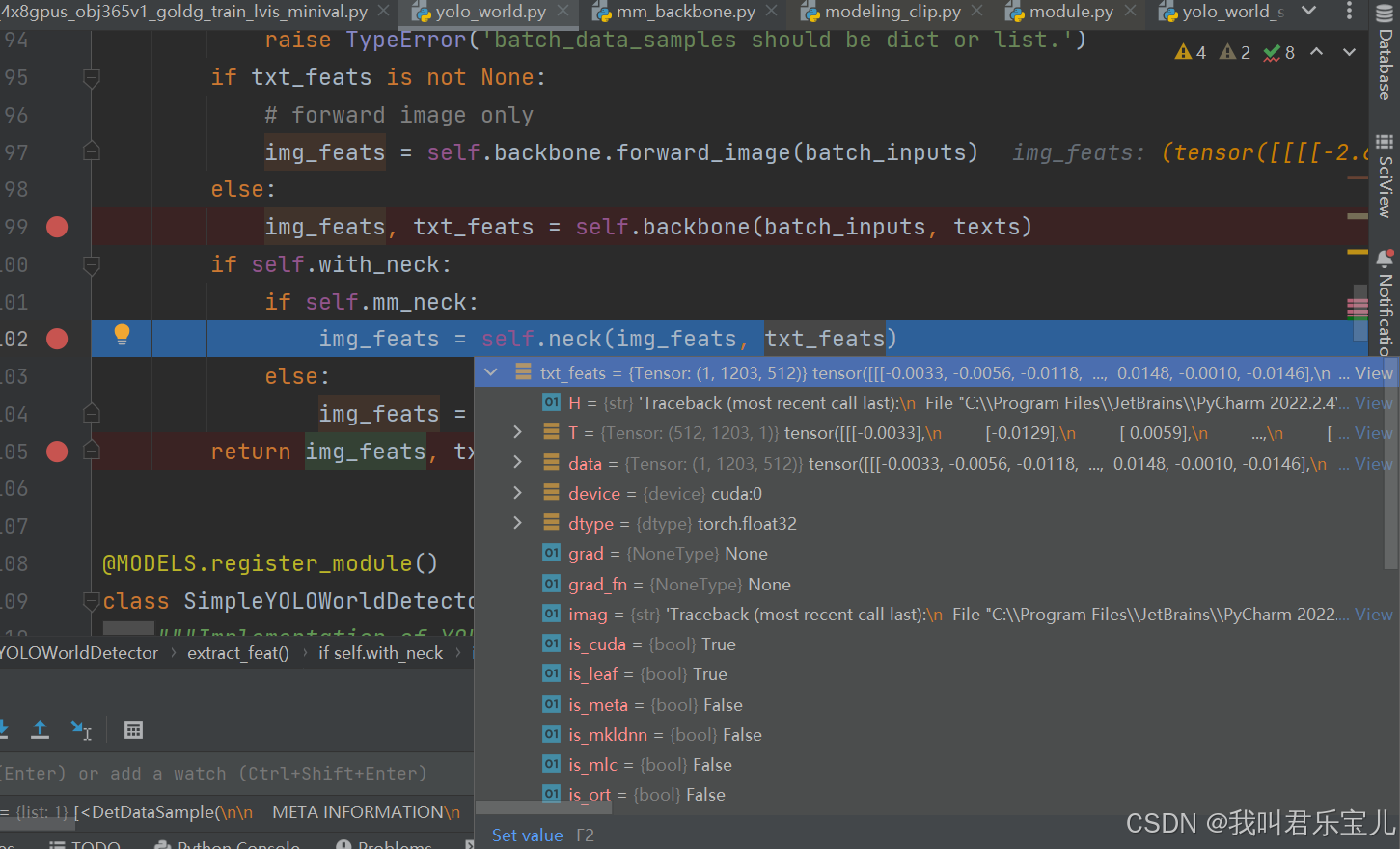
得到图像特征和文本特征后,就要走neck
feat_high和feat_low代表相邻两层级,upsample_layers做上采样方便特征融合
卷积切分,把其中一个模块继续走几个block,再与文本特征做一个attention

文本特征72行先走全连接,将文本特征变成256个通道的特征,72行reshape多头注意力机制(8头注意力),将256个通道分成8个头,每个头32个向量
图像方面做reshape同样也是8头,
五、论文解读
Real-Time Open-Vocabulary Object Detection
目前领域的方法:
yolo系列在目标检测领域取得了很好的效果,是一个实时的目标检测算法,它将目标检测视为一个回归问题,有着非常好的时间性能。
出现的问题:
但是传统的yolo算法依赖于训练数据的标注,即标注什么就检测什么,训练时未有标签的物体不会被检测到。这便出现了问题,比如使用COCO数据训练好了一个yolo模型后,该模型只能检测COCO数据集的80个类别,需要检测新物体时,只能另外寻找新的数据集重新训练
【教程】COCO 数据集:入门所需了解的一切_coco格式是什么-CSDN博客https://blog.csdn.net/sxf1061700625/article/details/136175940
近期研究
近期的很多工作开始研究vision-language model(视觉语言模型),他们通过language encoder(语言编码器)提取词语文本特征来解决open-vocabulary detection问题,例如使用BERT编码器。
YOLO-World详解
开放世界中检测万物
这是一种开放式词汇目标检测方法(open-vocabulary object method),将原有的yolo检测方法的性能提高到了开放词汇,不仅仅局限于训练的标签。
简介
该新方法基于标准的yolov8,并使用预训练的clip编码器对输入的提示词进行文本编码,并使用一种新的神经网络 Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN)来连接图像特征和文本特征,因为yolo的表现能力很大程度上依赖于训练时的表现信息,视觉信息和文本信息在一起建模,可以提高视觉语义表示。
对比
1、 传统的yolo检测算法使用的是封闭训练集进行训练,只能推理预测已经有的标签。
2、目前已经有的开放词汇检测器使用在线文本的方式进行编码并检测对象(Swin-L)。
3、先提示后检测的模式(yolo-world)首先对用户的提示进行编码,构建离线词汇表,然后检测器可以在不对提示文本编码的情况下推断离线词汇表,进行检测。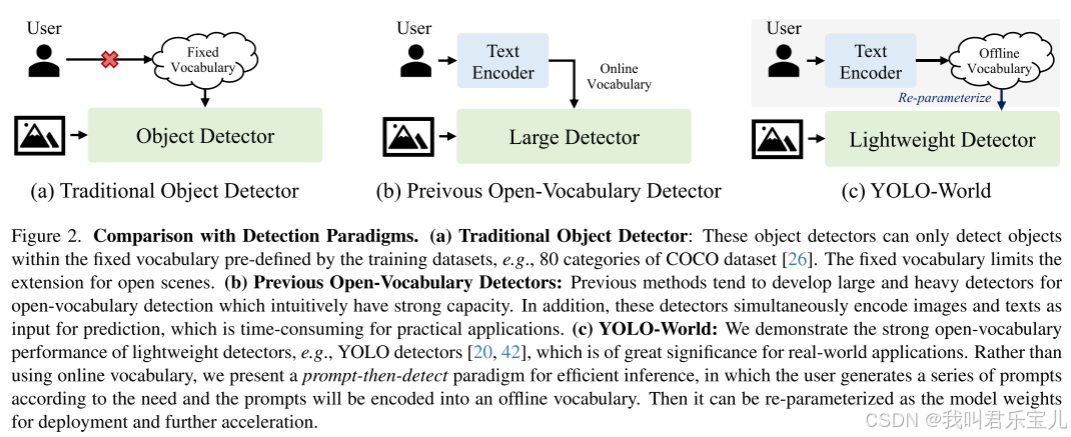
最大创新点
Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN)可以连接视觉与语言特征,为yolo-world提供文本-视觉特征结合的预训练方案。
与传统yolo算法相比,该方法能检测出固定词汇之外的目标,具有很好的泛化能力。
使用视觉图像和文本对齐的方式进行训练。
具体方法
区域-文本匹配
传统的目标检测算法都需要标签,标签里有五个值,分别是中心点x、y,长H,宽W、类别。yolo-world重新定义新的标签,将标签描述为区域-文本对(region-text),其中文本是对目标区域的具体描述。文本可以是类别名称、短语或者目标描述。
训练时,yolo-world使用图像和文本描述作为输入,并输出预测框和对应的目标嵌入(object embedding),embedding的作用是和输入的文本提示词做一个相关,看是属于哪一个类别。
模型架构
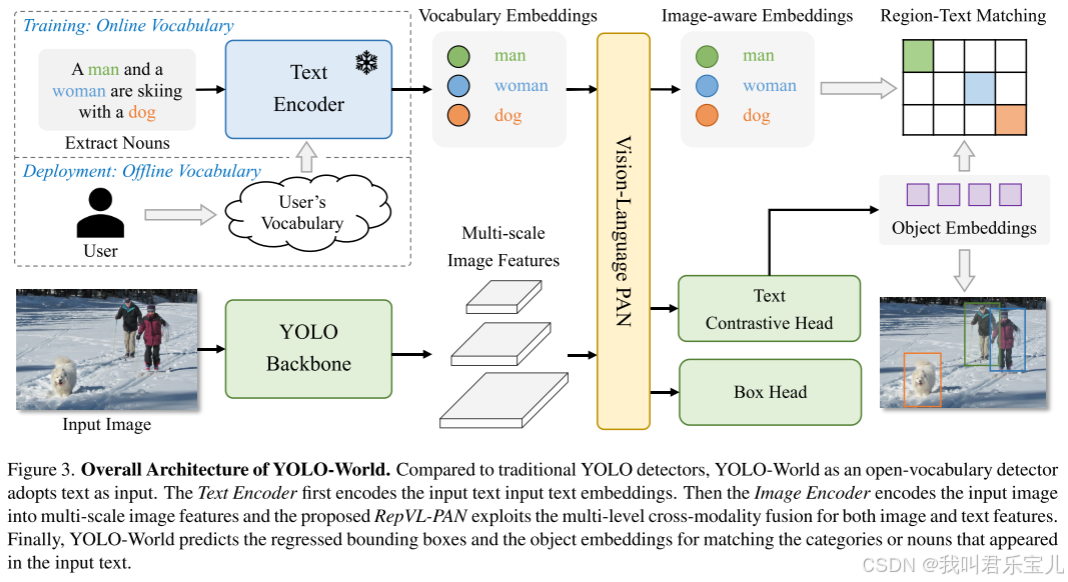
yolo-world由yolo检测器、文本编码器和Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN 可重新参数化的视觉语言路径聚合网络)组成。
给定输入文本,文本编码器将输入文本编码为文本嵌入(embedding),yolo中的图像编码器将图像编码为多尺度特征,利用RepVL-PAN网络,将图像特征和文本特征跨模态融合,增强图像和文本的表达。
yolo检测器
文本编码器

对于给定的文本T,使用CLIP预训练的Transformer编码器来提取文本嵌入(embedding),编码成CxD维的文本嵌入(C是名词个数,D是每个名词的维数,这里是256)。
提取名词使用的是b-gram算法,可以提取关键的名词作为关键的输入(比如我想找图片里的人)。
自然语言处理中N-Gram模型介绍 - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/32829048
预训练的CLIP在训练的时候以图像文本配对的方式进行自监督训练,在输入CxD维的文本嵌入时,能提供和视觉特征合得来的特征向量,方便和视觉特征做融合。
文本对比头

如何匹配文本与标准的embedding,使用相似度。先对object embedding和文本的embedding进行归一化,使用的归一化方法是L2归一化,再设置两个可学习的参数α(缩放因子)和β(移位因子),通过两个参数的内积寻找和文本最为相近的object embedding。
在线词汇训练
语料库的词语最多为80个词(与COCO做对比)。
离线词汇推理
先提示后检测策略(prompt-then-detect strategy),输入的语料可以自定义,可以包括标题或者类别,使用文本编码器来对文本进行编码(文本编码器包括名词提取n-gram和提取文本嵌入两部分)。接下来加入到视觉特征中,yolo-world做匹配。
Re-parameterizable Vision-Language PAN(可重新参数化的视觉语言PAN神经网络)
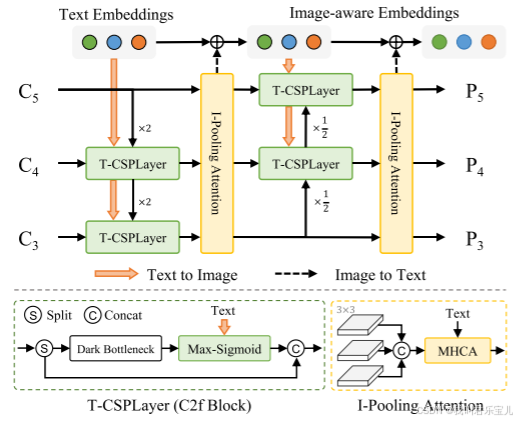
这个网络的作用是让图像和文本进行跨模态融合,C3、C4、C5就是yolo的多尺度特征图,大小分别是20x20,40x40,80x80。比如40x40的特征图,刚开始是40x40x512,切分成两份。
T-CSPLayer 文本影响图像
上边的路径先走两个卷积,text embedding有三组文本(示例),每一组文本都能编码成256维的向量,这样文本特征向量就是3x256大小。
Max的作用是让图像特征图的每一个像素点与每一个文本特征算关系,这个像素点但凡与一个文本特征有关系就说明这个像素点很重要,就要关注,权重就要被放大。
sigmoid就是将权重项归一化。
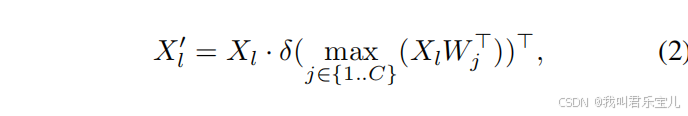
Max-Sigmoid的作用就是通过文本输入的特征编码来重新整合以下哪个区域更需要重点关注。
最终再通过cat拼接起来
I pooling Attention 图像影响文本
文本现在是一个特征向量,图像是特征图,为了匹配文本向量,把特征图做成序列。C3、C4、C5的特征图大小不一样,设计一些池化的方法将特征图pooling成3x3的区域,将三种不同尺度的特征图进行拼接,这样就是27个区域,包含三种不同尺度大小,每种尺度9个不同的区域,每个区域中有唯一的一个特征编码。
对图像来说,特征向量就是1x27xD大小,图像特征向量和文本的特征向量可以做cross-attention。
通过多头注意力机制更新文本特征向量。
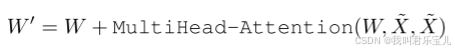
小总结
图像特征影响文本特征、文本特征影响图像特征分别做了两次,将输出的P3、P4、P5输入到yolo head中,预测目标框(bounding box)和类别(cls),获得每个区域的embedding,和输入文本特征向量做匹配,找到区域与输入文本特征向量的配对。
损失函数
区域-文本对比损失 Region-Text Contrastive Loss
1、生成区域-文本对:在训练阶段,使用yolo检测器识别图像中潜在目标的区域,并将这些区域与相应的文本描述进行配对。
2、计算相似度得分:对于每一个区域-文本对,计算其图像特征和文本特征的点积来实现。
3、构建对比损失:通过区域-文本的相似度和对象-文本的交叉熵构建对比损失Lcon,此外再加入分布焦点损失和IOU损失来构建总的损失函数。
实验
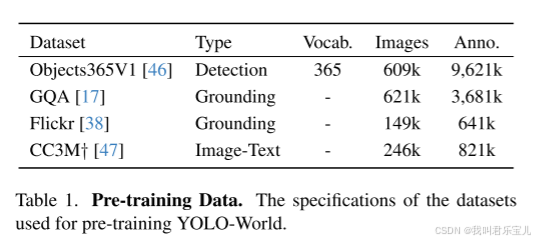
在大规模数据集上训练yolo-world,并在Lvis数据集和COCO数据集上以zero-shot的方式评估yolo-world。
zero-shot 零样本检测,即模型在没有见过某些类别的情况下,能够识别这些类别。比如老虎、狮子、豹子和猫,训练集只有老虎、狮子、豹子,但是没有猫的标签,使用一句带描述性的话来描述猫这种类别,将这段文本转化为文本嵌入,表示“猫”这种类别的特征,并与已知的类别进行对比。
在实际检测中,模型通过学到的知识来检测老虎、狮子和豹子,即使没有学过关于“猫”的特征,依然能通过文本嵌入找到类似的特征进行检测。
GQA数据集简介及数据格式介绍-CSDN博客https://blog.csdn.net/qq_40481602/article/details/125627062
关于flickr的数据集笔记_flickr30k-CSDN博客https://blog.csdn.net/weixin_45647721/article/details/125964368
评估过程
评估过程使用的是lvis minival验证集,评估指标为AP
两个条件
1、准确识别出目标的类别
2、定位准确目标的位置
【目标检测】目标检测算法评估指标(性能度量) AP,mAP 详细介绍_mean ap-CSDN博客https://blog.csdn.net/qq_24224067/article/details/108987897
AP(Average Precision)、APr(AP at Recall)、APc(AP for Common Classes)和APf(AP for Frequent Classes)定义_lvis:使用 apr、apc、apf 分别测评稀有、常见和频繁类别性能-CSDN博客https://blog.csdn.net/weixin_41012399/article/details/140818637#:~:text=%E6%80%BB%E7%BB%93%E6%9D%A5%E8%AF%B4%EF%BC%8CAP%E3%80%81APr%E3%80%81APc%E5%92%8CAPf%E9%83%BD%E6%98%AF%E7%94%A8%E4%BA%8E%E8%AF%84%E4%BC%B0%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8B%E6%A8%A1%E5%9E%8B%E6%80%A7%E8%83%BD%E7%9A%84%E9%87%8D%E8%A6%81%E6%8C%87%E6%A0%87%EF%BC%8C%E4%BD%86%E5%AE%83%E4%BB%AC%E5%88%86%E5%88%AB%E5%85%B3%E6%B3%A8%E4%B8%8D%E5%90%8C%E7%9A%84%E6%96%B9%E9%9D%A2%EF%BC%9AAP%E5%85%B3%E6%B3%A8%E6%95%B4%E4%BD%93%E5%B9%B3%E5%9D%87%E7%B2%BE%E5%BA%A6%EF%BC%8CAPr%E5%85%B3%E6%B3%A8%E4%B8%8D%E5%90%8C%E5%8F%AC%E5%9B%9E%E7%8E%87%E4%B8%8B%E7%9A%84%E5%B9%B3%E5%9D%87%E7%B2%BE%E5%BA%A6%EF%BC%8CAPc%E5%92%8CAPf%E5%88%99%E5%88%86%E5%88%AB%E5%85%B3%E6%B3%A8%E5%B8%B8%E8%A7%81%E7%B1%BB%E5%92%8C%E9%A2%91%E7%B9%81%E7%B1%BB%E5%88%AB%E7%9A%84%E6%A3%80%E6%B5%8B%E6%80%A7%E8%83%BD%E3%80%82,APr%E6%8C%87%E7%9A%84%E6%98%AF%E5%9C%A8%E4%B8%8D%E5%90%8C%E5%8F%AC%E5%9B%9E%E7%8E%87%E4%B8%8B%E7%9A%84%E5%B9%B3%E5%9D%87%E7%B2%BE%E7%A1%AE%E7%8E%87%E3%80%82
true positive(TP真正例):IOU大于阈值
false positive(FP假正例):IOU小于阈值
false negative(FN假反例):目标没有检测到
没有用到真反例,因为有无穷多个非目标框
precision(准确率)= 预测正确的目标框/全部的预测目标框
recall(召回率) = 预测正确的目标框/全部正确的目标框
得到P-R曲线后,使用11点插值法(11-point interpolation) 来计算AP(平均精度)
AP是平均召回率下的精度,AP通常计算为IoU阈值从0.5到0.95(以0.05为步长)的平均值。
APr是每个类别的平均精度。
APc是针对常见类别的平均精度。(出现次数大于等于100)
APf是针对频繁类别的平均精度。(10~100)
AP50是AP在IoU阈值为0.5时的精度。
AP75是AP在IoU阈值为0.75时的精度。
最终结果
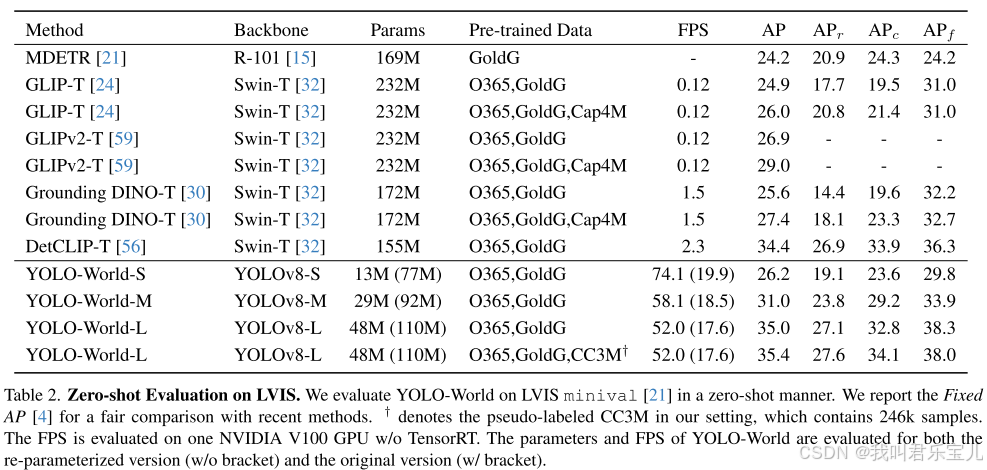
以LVIS minval数据集为基准,使用zero-shot的方式与目前比较好的方法比较。无论是从速度还是精确度来看,yolo-world-L(最后一个)均优于目前存在的方法。
与GLIP-T、Grounding DINO-T用大数据量Cap4M训练的模型相比,yolo-world-L只使用O365和GoldG训练的模型的效果要优于前者。
与DetCLIP-T相比,yolo-world使用更少的参数和速度获得了相当的性能(35.4vs34.4)。
消融实验
预训练数据部分
基于yolo-world-L和预训练的Object365数据集,使用LVIS minival进行评估
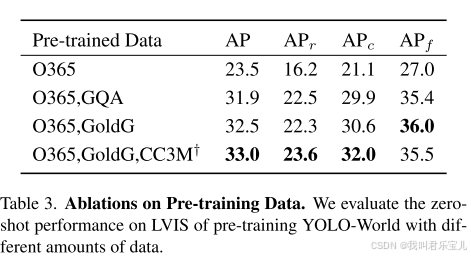
与基准的训练集O365相比,添加GQA数据集可以显著的提高性能,可以归因于GQA数据集提供了更为丰富的文本信息,可以增强模型识别大词汇对象的能力。
添加部分CC3M样本时,可以继续带来AP增益。
总之在大词汇量场景下,随着训练数据量的增加,模型的性能也不断增加,突出了利用更大更多样化数据集进行训练的好处。
网络部分
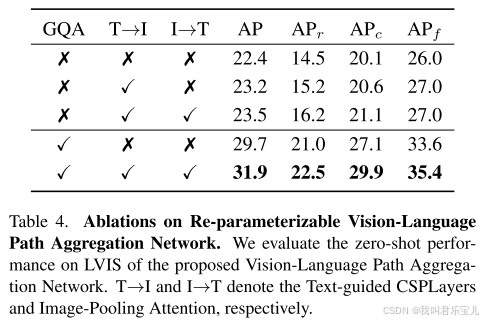
预训练数据方面,采用两种方式,只有O365,O365和GQA共同训练。
算法方面,RepVL-PAN算法包括文本引导的CSPLAyers算法和图像池注意力算法。
RepVL-PAN在文本信息丰富的情况下表现更好(GQA包含了大量的名词短语形式的文本)
文本编码器
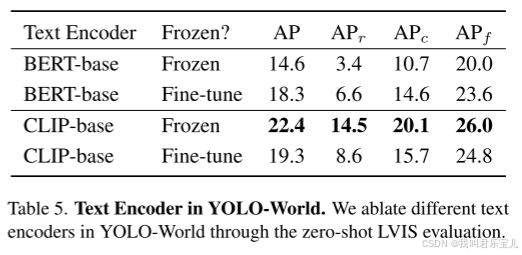
比较了使用不同文本编码器的性能,有BERT编码器和CLIP编码器,类型分为冻结和微调型。
CLIP文本编码器要优于BERT文本编码器。
在预训练期间微调BERT编码器得到了性能的优化,但是微调CLIP导致了性能的下降,原因是对于O365的微调可能让CLIP编码器只包含365个类别的信息,会降低CLIP编码器的泛化能力。
Fine-tuning yolo-world(微调)
为了在COCO数据集和LVIS数据集上进行近距离对象检测,进一步微调yolo-world模型。
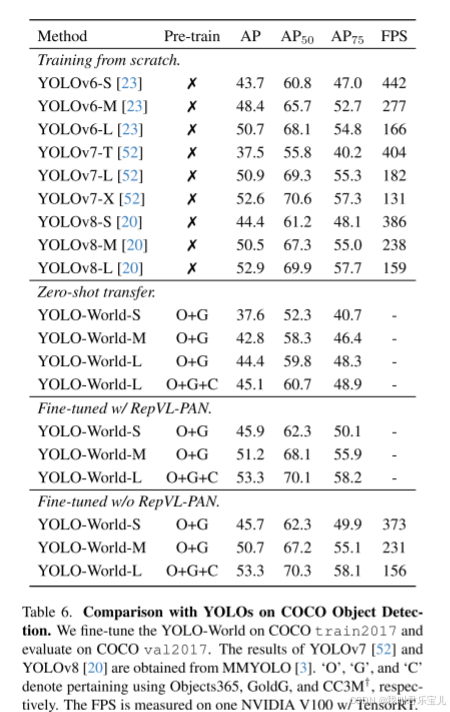
在COCO train2017数据集上进行微调,并在COCO val 2017数据集上进行评估,表明了yolo-world具有很好的泛化能力,与从头训练的方法相比,性能更好。
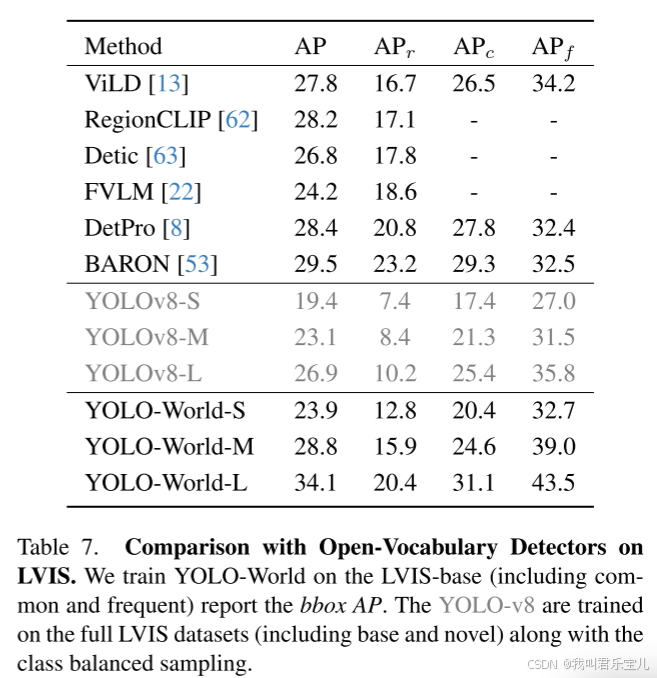
在标准LVIS数据集上对YOLO-World的微调性能进行了评估。
与基于完整LVIS数据集训练的yolo v8相比,YOLO-World实现了显著的改进,表明本文提出的预训练策略对大词汇检测的有效性。
此外,yolo-world整体性能也优于最新的基于文本提示的检测方法。

















 3202
3202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









