







Optimal and Efficient Path Planning for Partially-Known Environments 论文学习笔记
D ∗ D^* D∗主要用于解决动态路径规划问题。在使用 A ∗ A^* A∗算法进行全局路径规划后,若机器人按照规划路径行驶,中途感知到动态障碍物时(全局规划时未考虑到),再次使用 A ∗ A^* A∗算法进行路径规划无法满足实时要求。此时, D ∗ D^* D∗就可以派上用场。
与 A ∗ A^* A∗算法不同的是, D ∗ D^* D∗算法是从终点出发,往起点方向搜索。
定义
states:机器人位置directional arcs:连接任意两点之间的线段(弧段)G:终点backpointer:b(X)=Y表示状态X是由状态Y转换而来的C(X,Y)表示从状态Y到状态X的成本/花费,如果C(X,Y)存在,则表示状态Y和状态X是空间上的近邻,如果不存在或者无穷大,则称两个状态不是空间上的近邻,不能由Y直接到XOPEN:与 A ∗ A^* A∗算法的OPENlist相似,包含探索过的并且还有可能在后续规划中考虑的点CLOSE:与 A ∗ A^* A∗算法的CLOSElist相似,包含探索过的并且被移出OPENlist中的点以及障碍物tag:每个状态都有标签,如果状态X从来没有被加入OPENlist中,则tga(X)=NEW; 如果正处于OPENlist中,则tga(X)=OPEN;如果正处于CLOSEDlist中,则tga(X)=CLOSED;h(G,X):表示从终点G到状态X的预估成本k(G,X):表示从状态X被加入到OPENlist后,不论状态和值如何变化,h(G,X)取到过的最小值;- 如果
k(G,X)<h(G,X),说明状态X存在异常,此时称为RAISE状态(出现了某些状况让h值上升了);如果k(G,X)=h(G,X),说明状态X不存在异常,此时称为LOWER状态(正常优化状态)
算法描述
算法初始化中,所有的状态均为tag(X)=NEW,h(G)=k(G)=0,表示终点本身的成本为0。 在首次路径规划时,相当于执行Dijkstra算法进行寻路。
首先执行PROCESS-STATE()函数,因为是首次搜索,有k_old=h(X)。需要注意的是,在首次搜索过程中,当状态X被选作当前状态后,它会移出OPEN列表,所以肯定不会出现k_old<h(X)的情况。所以,在首次搜索中,L8-L13会被唯一执行。
当规划完成后,机器人会沿着规划路线进行移动。但是,在移动过程中,可能会出现动态障碍物或者地图中不存在的未知障碍物。这些障碍物被机器人感知之后,就需要动态规划,调整现有路线。这也是D*算法的优势之处:从受影响障碍物开始,将障碍物信息向外传递,只重新计算受影响区域。

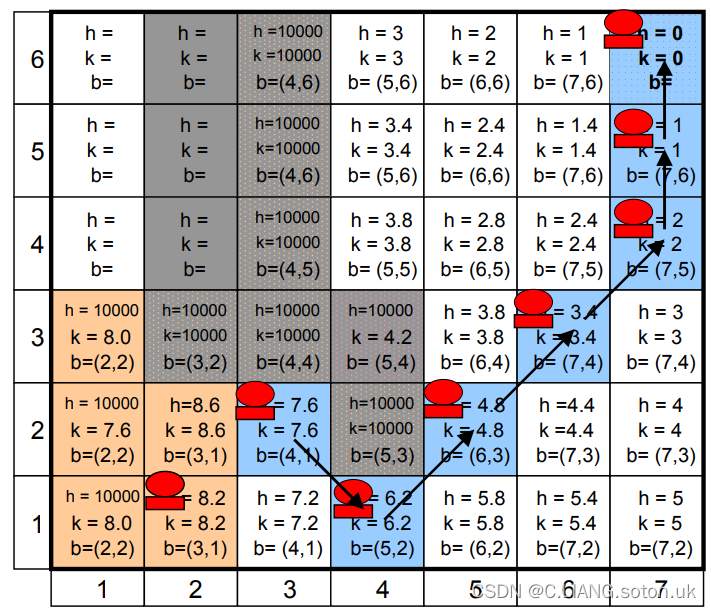
假设我们首次寻路得到了初始路径,在途中使用蓝色标识。在OPEN列表中的状态使用橙色标识,障碍物使用灰色标识:(原始PPT详见D*算法图解PPT)

上图中,起点为(2,1),终点为(7,6)。假设在机器人行驶到(3,2)后,发现状态(4,3)实际上是障碍物,无法通过。此时,机器人应该对路径进行再次规划,避开该障碍物:

此时,D*算法首先调用MODIFY-COST函数将从(4,3)到其临近状态的移动成本C(X,Y)为无穷大,并且将该状态从CLOSE列表中取出,并加入到OPEN 列表中。

之后,将(4,3)点周围的临近点都加入到OPEN列表中。之后再重复运行PROCESS-STATE函数。此时,具有最小K值的点应该是举例终点(7,6)最近的点,即点(5,4)。将该点作为当前状态继续优化:

此时,因为k_old = h(X),所以,运行的是PROCESS-STATE中的L8-L13。对于障碍物点(4,3),运行:

因为此时c(X,Y)为无穷大(用10000代表),所以,h(4,3)=100000。对于(5,4)周围的其他点,经过上述流程后没有任何操作。下一步,将点(5,4)从OPEN列表中移出,并且加入CLOSE列表。再次运行PROCESS-STATE,选取具有最小的K值的状态。

同理,在(4,4)和(5,3)作为当前点时,运行L8-L13行,没有任何操作。下一步就要选取障碍物点(4,3)作为当前点。因为k_old<h(X),先运行L4-L7。在这个过程中,h(X)>h(Y)+c(Y,X)总是不成立的,因为此时c(Y,X)为无穷大, h(X)也为无穷大。所以,L4-L7运行完成后没有任何操作。接着运行L15-L25,仅仅状态(3,2)的h值通过L17-L18发生了改变,为无穷大。
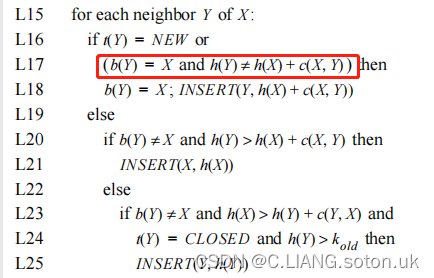
之后,继续优化,选择在OPENl列表中具有最小k值的状态(5,2)作为当前状态。因为k_old=h(X),运行L8-L13,无任何操作。继续优化,选择状态(3,2)作为当前状态:

此时,因为k_old<h(X),先运行L4-L7,无任何操作。再运行L15-L25。对于状态(3,1),(2,1),(2,2),通过L17-L8,h值升高,变为无穷大,其他点不受影响。下一步,选择状态(4,1)作为当前状态
因为k_old=h(X), 经过L8-L13,改变了状态(3,1)和(3,2)的父节点以及h值。之后继续优化,选取状态(2,2)为当前状态,

此时,k_old<h(X),先运行L4-L7,没有任何操作。继续L14-L25,L17-L8让状态(1,2),(1,1),(2,1)的h值增加。之后,继续优化,选定状态(2,1)为当前状态

因为k_old<h(X),所以,运行L4-L7以及L14-L25,但是没有发生任何操作。接下来继续优化,选择OPEN列表中具有最小k值的(3,1)为当前状态。因为k_old = h(x), 运行L8-L13,改变了状态(2,1)以及(2,2)的父代(backpoint)并且将他们放到了open列表中。

下一步,把状态(3,1)从OPEN表中删除,放到CLOSE 中。当选择下一个当前状态时,有回到了机器人当前位置(3,2),即OPEN列表中没有其他状态具有比机器人当前所在状态具有更小的k值,所以,路径规划结束。

根据父指针,将剩余路线标识出:
总结
- D* 算法的核心是将动态障碍物带来的影响传递出去。笔者认为函数PROCESS-STATE是通过推理,总结得来,而并非直观思考。所以,D的设计很巧妙,但是没有耐心和一定的归纳总结能力可能设计不出来D这样的算法。
- D* 算法保留了首次搜索后的信息,比如OPEN列表,backpoint指针等。这也为后来的D* Lite, Focused D*等方法提供了改进方向。
- D*, Lifelong Planning A* (LPA*),Focused D*, D* Lite这四种算法是一个系列的,可以一起学习。















 3331
3331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









