











前言
上午刚开心的在朋友圈庆祝了《哪吒2》登顶全球IMAX票房历史前八;
下午老板就说,小王啊,你这么懂,就拿DeepSeek做出一个《上古神话中龙族意象在流行文化中的演变》吧,记得下班前给我……
对了,记得要融合孙悟空和哪吒的痒点,结合《山海经》到《哪吒》的爆款打法,利用古典文学理论与当代精神分析双重赋能,打出我们的独特用户爽点(省略八百字)
老板的要求百爹齐放
但时间转换器从哈利波特走向现实之前,打工人的上班时间依旧是有限且有尽头的。
用传统RAG的思路应付交差吧,它只能帮你解决搜索事实的痛点
搞GraphRAG吧,老板还想要做出知识图谱与大模型生成的组合拳
你还真别说,不久前,Open AI推出Deep Research(深度研究)功能,还真能帮打工人几分钟就搞定老板的变态要求。
通过将大模型+超级搜索+研究助理的三合一,
Deep Research可以让金融机构一键生成报告、科研党一键生成综述。服务一经推出,立刻风靡全球。
但Deep Research底层模型绑定了OpenAI不说,还没办法利用本地数据。
这工作的环,闭了,但没完全闭。
基于这一思路,向量数据库公司Zilliz开源了DeepSearcher,目前在Github上已经有了1000+star。
该方案不仅结合了Deep Research的优势,在此基础上,用户还能自由选择底层大模型,并通过Milvus接入本地数据,更适合企业级场景落地。
尝鲜链接:https://github.com/zilliztech/deep-searcher
本文将通过DeepSearcher 技术分析,与传统RAG对比,以及实测展示三部分,带来相关解读。
01
RAG技术演进:从基础到增强
1.为什么我们需要RAG?
RAG(检索增强生成,Retrieval-Augmented Generation)通过整合实时搜索与大语言模型能力,解决了传统生成技术的三大痛点:
(1)知识时效性困境
大模型训练数据存在时间截断(如GPT-4仅更新至2023年)
RAG通过实时检索最新文档(如科研论文/新闻),动态扩展模型知识边界
(2)事实准确性瓶颈
纯生成模型易产生"幻觉"(Hallucination),虚构不存在的事实
RAG先检索相关证据文档,要求模型严格基于检索内容生成,显著降低错误率
(3)领域适配成本问题
微调(Fine-tuning)需要大量标注数据和计算资源
RAG仅需构建领域文档库,即可让通用模型输出专业内容(如法律/医疗场景)
2.传统RAG、Graph RAG、DeepSearcher的本质区别
假设一个你在图书馆找资料的场景:
传统RAG - 就像在图书馆找书
你知道当我们在图书馆找一本书时,通常会先看书名和简介对吧?传统RAG也是这个道理:
-
它会把所有文档内容"向量化" - 可以理解为给每段文字打上特征标签
-
当你问问题时,它就像图书管理员一样,根据这些标签快速找到最相关的内容
-
比如你问"哪吒的性格特点是什么",它就会找到描述哪吒性格的段落
-
优点是简单直接,缺点是可能会错过一些深层的关联信息
GraphRAG - 像是在查族谱
这个就比较有意思了,它更像是在查看一个互动版的族谱:
-
它会把人物、事件、关系都存成一张大网
-
每个人物是一个节点,人物之间的关系就是连线
-
当你问"哪吒和敖丙是什么关系"时,它能直接沿着关系网络找到答案
-
不只是找到表面的答案,还能发现意想不到的关联,比如他们共同的朋友或敌人
DeepSearcher - 像是在玩RPG游戏
这个方法有点像玩RPG游戏时的人物属性面板:
-
它会把信息分成不同的层次,就像游戏里的主线任务和支线任务
-
比如第一层是主要人物关系,第二层是详细的互动情节
-
当你问"描述哪吒在剧中的重要关系"时,它会先找到核心关系
-
然后逐层深入,找到具体的故事情节和细节
-
这样不会让信息太乱,层次分明更容易理解
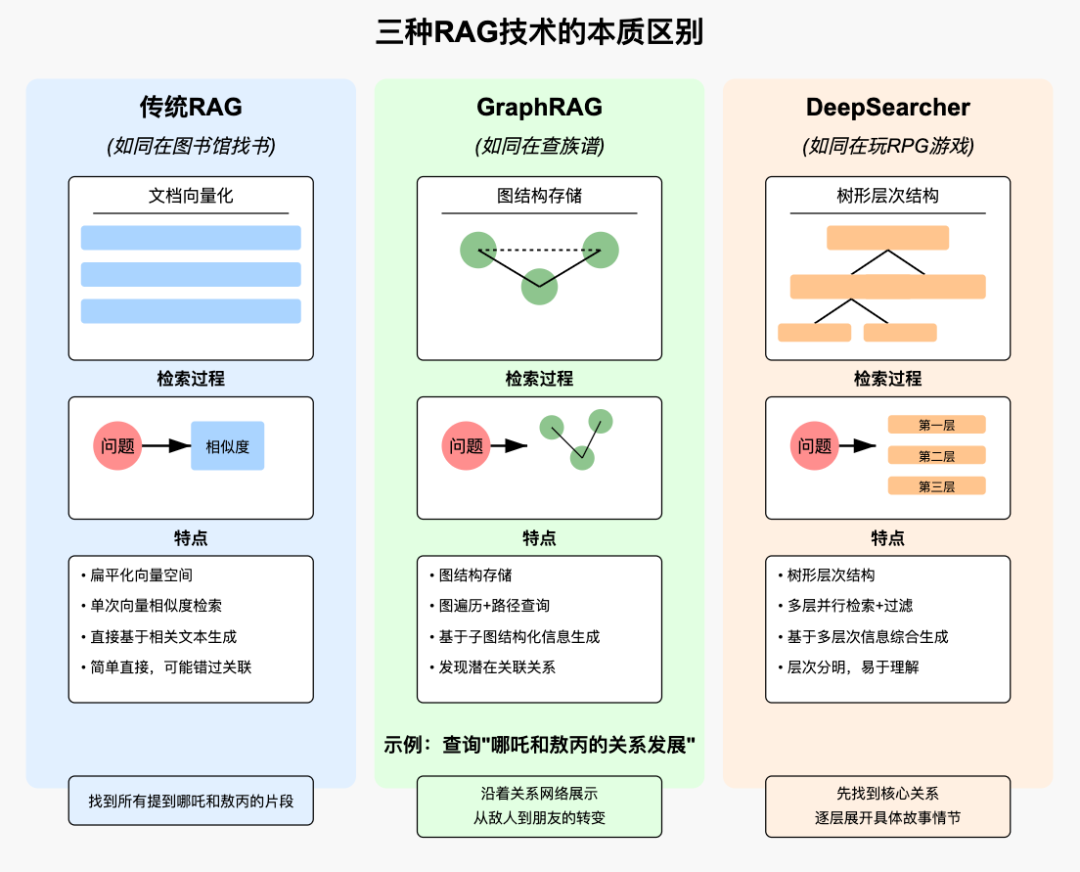
3.不同RAG技术架构对比
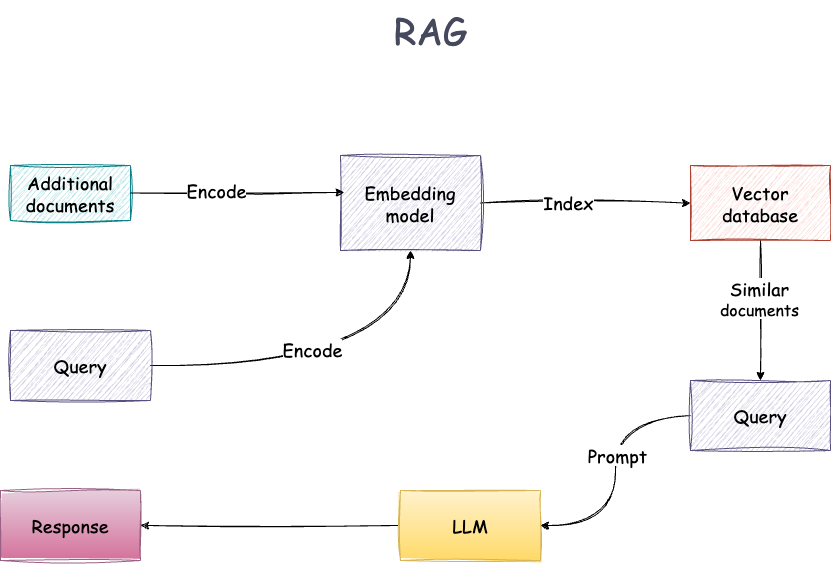
(1)传统RAG架构
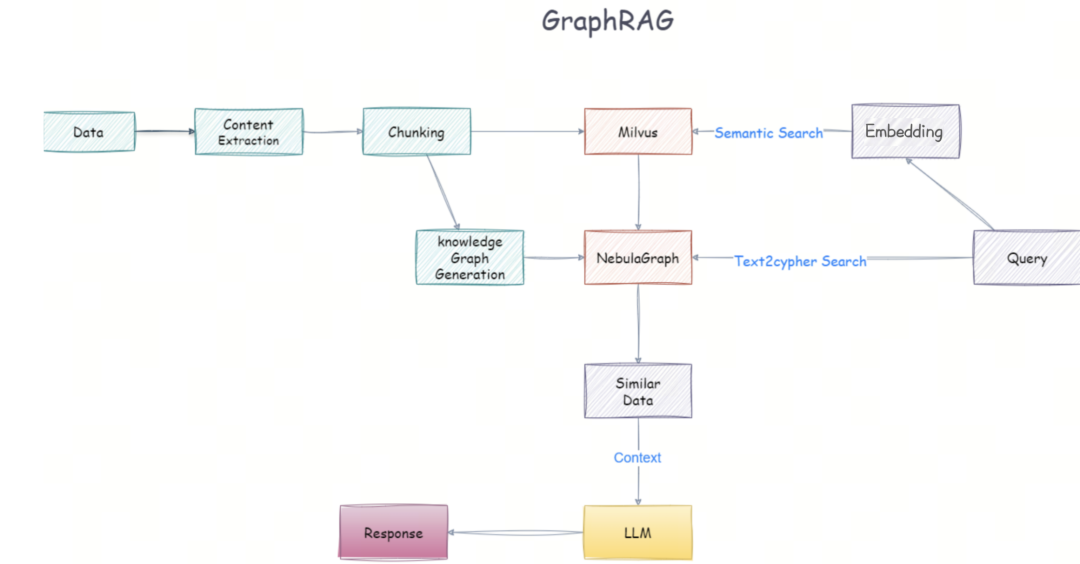
(2)GraphRAG架构
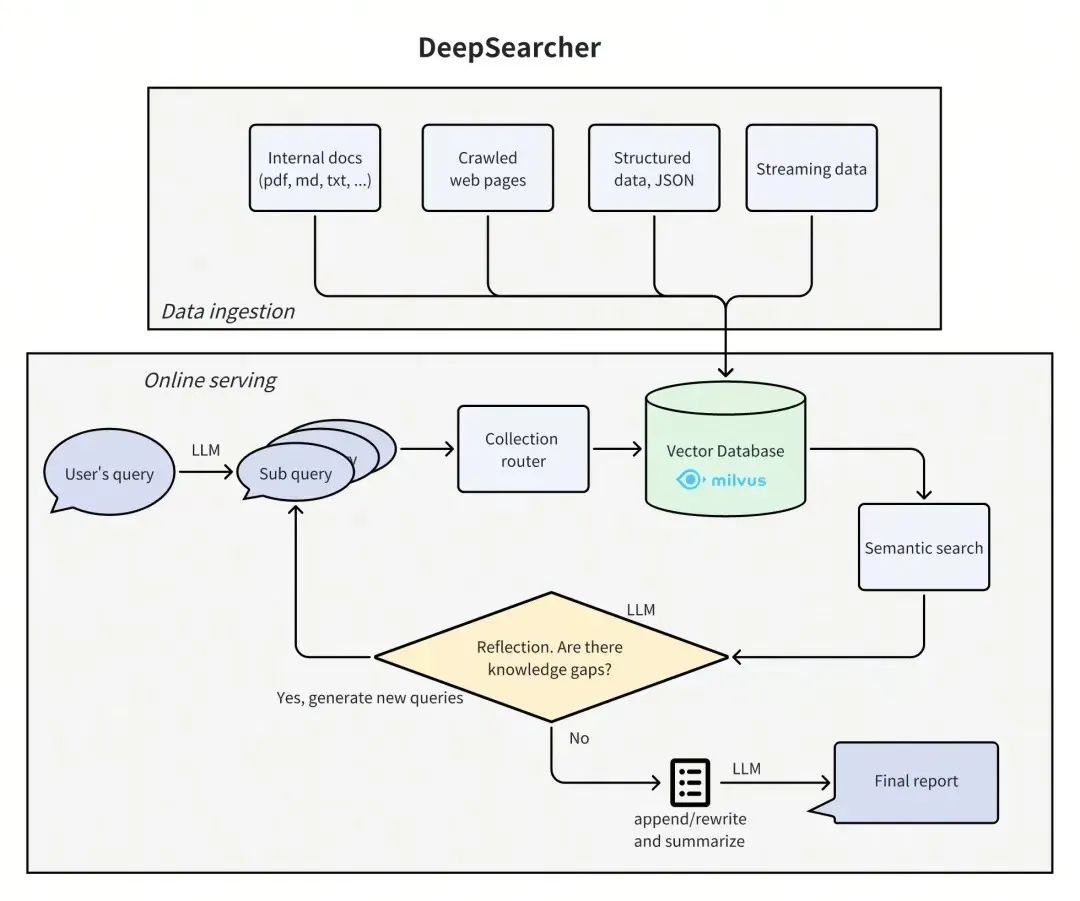
(3)DeepSearcher架构
4.不同RAG数据组织方式对比
-
RAG:采用的是扁平化的向量空间形式,让信息之间的关系更加直观。
-
GraphRAG:则是利用图结构来进行存储,这种方式非常适合表示复杂且相互关联的数据集。
-
DeepSearcher:通过树形层次结构来组织数据,并逐步反馈迭代,使得查找特定信息时能够像浏览文件夹一样方便快捷。
5.不同RAG检索机制对比
-
RAG(检索增强生成):通过比较文本向量之间的相似度来找到最相关的信息。
-
GraphRAG:结合了图结构的数据遍历和路径查询技术,能够更精准地定位相关信息。
-
DeepSearcher:采用多层次并行搜索加上智能过滤的方式,旨在从大量数据中快速准确地获取所需信息。希望这样改写能让大家更容易理解这些检索机制的特点!
6.不同RAG结果生成对比
-
RAG:直接根据相关的文字内容生成答案
-
GraphRAG:利用子图中的结构化信息来生成答案
-
DeepSearcher:结合多层信息,并逐步深入挖掘多层信息和信息之间的关系,生成综合全面且准确的答案。
02
三种RAG设计模式试验效果
1.传统RAG
(1)准备技术栈
| LLM | 向量数据库 | 开发平台 | 向量模型 |
| DeepSeek | Milvus | Dify | bge-m3 |
(2)实现步骤
-
dify中配置deepseek-r1模型
-
创建哪吒2的知识库
-
创建聊天助手关联知识库和模型
-
问答查看效果
(3)测试数据集
哪吒是一个天生反骨的少年英雄,具有雷电属性,属于阐教。
他的父亲是李靖(陈塘关总兵),母亲是殷夫人。
他的师父是太乙真人,是阐教弟子。
敖丙是东海三太子,具有冰雪属性,属于龙族。
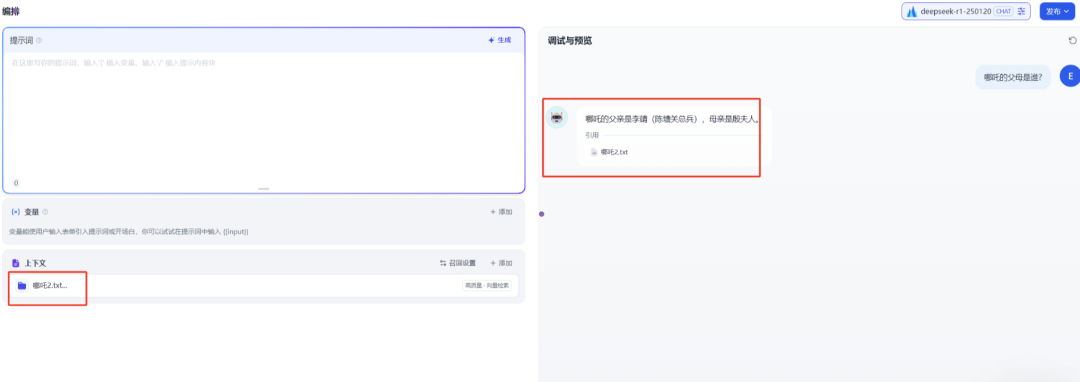
(4)测试问答
哪吒的父母是谁?
(5)问答效果
2.GraphRAG
(1)准备技术栈
| LLM | 图数据库 | 可视化平台 |
| DeepSeek | NebulaGraph | NebulaGraph Studio |
(2)实现步骤
-
使用deepseek生成一些测试数据集
-
安装NebulaGraph导入测试数据
-
Dify创建工作流应用
-
配置Nebula API调用等
-
编排工作流节点
-
测试验证问答效果
(3)Nebula中插入数据步骤
创建图空间
CREATE SPACE IF NOT EXISTS nezha2(partition_num=1, replica_factor=1, vid_type=fixed_string(128));``
**(4)使用图空间**
USE nezha2;
(5)创建角色标签
CREATE TAG role (` `name string, // 角色名` `meteorological string, // 气象属性` `faction string, // 所属阵营` `role_desc string, // 角色描述` `voice_actor string // 配音演员``);
(6)创建各种关系边
CREATE EDGE father_of (edge_time timestamp); // 父子关系``CREATE EDGE mother_of (edge_time timestamp); // 母子关系``CREATE EDGE teacher_of (edge_time timestamp); // 师徒关系``CREATE EDGE enemy_of (edge_time timestamp); // 敌对关系``CREATE EDGE friend_of (edge_time timestamp); // 朋友关系``CREATE EDGE lover_of (edge_time timestamp); // 恋人关系``CREATE EDGE brother_sister_of (edge_time timestamp); // 兄妹关系
(7)插入角色节点
INSERT VERTEX role (name, meteorological, faction, role_desc, voice_actor) VALUES` `"哪吒": ("哪吒", "雷电", "阐教", "天生反骨的少年英雄", "吕艳婷"),``"敖丙": ("敖丙", "冰雪", "龙族", "东海三太子,哪吒的挚友", "瀚墨"),``"太乙真人": ("太乙真人", "云雾", "阐教", "哪吒的师父,阐教弟子", "张珈铭"),``"殷夫人": ("殷夫人", "细雨", "人类", "哪吒的母亲,温柔贤惠", "绿绮"),``"李靖": ("李靖", "木", "人类", "哪吒的父亲,陈塘关总兵", "陈浩"),``"申公豹": ("申公豹", "风暴", "截教", "截教弟子,野心勃勃", "杨卫"),``"敖光": ("敖光", "海浪", "龙族", "东海龙王,敖丙之父", "雨辰"),``"敖闰": ("敖闰", "空间系", "龙族", "东海龙王之女", "周泳汐"),``"敖顺": ("敖顺", "毒", "龙族", "东海龙王之子", "韩雨泽"),``"敖钦": ("敖钦", "火", "龙族", "东海龙王之子", "南屿"),``"石矶娘娘": ("石矶娘娘", "沙尘", "截教", "截教弟子", "小薇"),``"结界兽": ("结界兽", "雾霭", "中立", "守护结界的神兽", "");
(8)插入各种关系
// 家庭关系``INSERT EDGE father_of VALUES "李靖" -> "哪吒": (NOW());``INSERT EDGE mother_of VALUES "殷夫人" -> "哪吒": (NOW());``INSERT EDGE father_of VALUES "敖光" -> "敖丙": (NOW());``INSERT EDGE father_of VALUES "敖光" -> "敖闰": (NOW());``INSERT EDGE father_of VALUES "敖光" -> "敖顺": (NOW());``INSERT EDGE father_of VALUES "敖光" -> "敖钦": (NOW());``// 师徒关系``INSERT EDGE teacher_of VALUES "太乙真人" -> "哪吒": (NOW());``// 朋友关系``INSERT EDGE friend_of VALUES "哪吒" -> "敖丙": (NOW());``INSERT EDGE friend_of VALUES "敖丙" -> "哪吒": (NOW());``// 敌对关系``INSERT EDGE enemy_of VALUES "申公豹" -> "太乙真人": (NOW());``INSERT EDGE enemy_of VALUES "申公豹" -> "哪吒": (NOW());``// 兄妹关系``INSERT EDGE brother_sister_of VALUES "敖丙" -> "敖闰": (NOW());``INSERT EDGE brother_sister_of VALUES "敖丙" -> "敖顺": (NOW());``INSERT EDGE brother_sister_of VALUES "敖丙" -> "敖钦": (NOW());``
**(9)测试效果**
这里我们使用NebulaGraph Studio进行测试
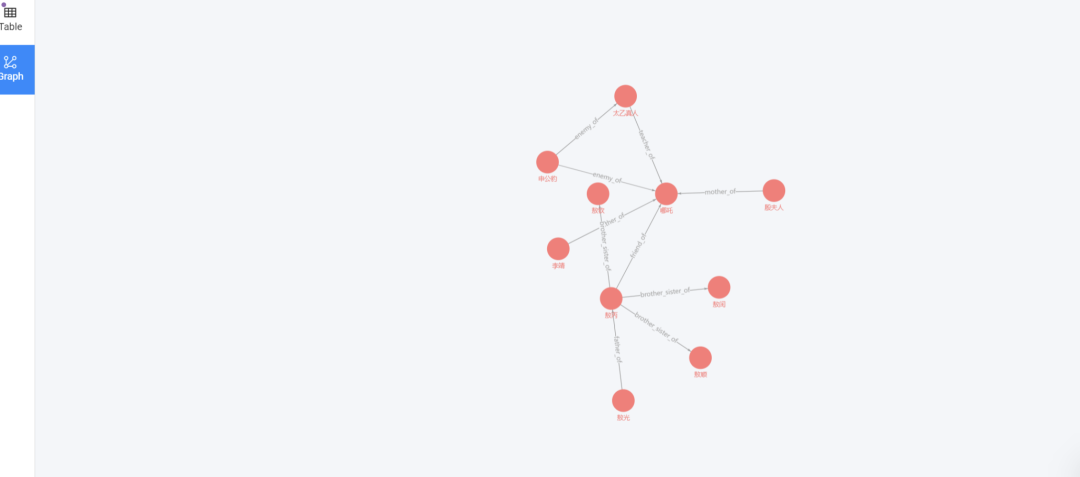
测试语句
// (查询哪吒相关所有关系)``MATCH (v1:role)-[e]->(v2:role)` `RETURN e LIMIT 10;
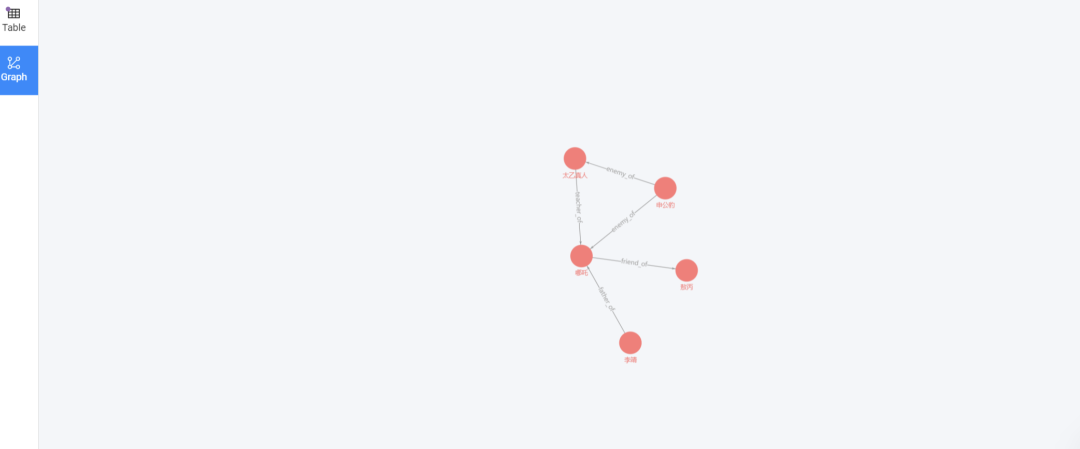
// 多跳关系查询``MATCH p=()-[*1..2]->()``RETURN p LIMIT 5;
3.DeepSearcher
说明:DeepSearcher的核心是 分层语义理解(文档结构/段落/句子/关键词的多级解析),而Dify父子检索是 索引结构优化(将文档拆分为父-子块建立层级索引)。本演示效果仅限于使用父子检索功能实现DeepSearcher的 层级索引 特性。如果对DeppSearcher其他特性有兴趣的可以参考Zilliz开源项目Github-Deep Searcher https://github.com/zilliztech/deep-searcher
(1)准备技术栈
| LLM | 向量数据库 | 开发平台 | 平台功能 | 向量模型 |
| DeepSeek | Milvus | Dify | 父子检索模式 | bge-m3 |
(2)实现步骤
-
准备分层知识文档
-
配置父子检索参数
-
创建对话选择DeepSeek-R1模型
-
LLM处理检索结果
-
测试验证问答效果
(3)测试数据集
# 角色基本信息`` ``## 哪吒``- 名称: 哪吒``- 属性: 雷电``- 阵营: 阐教``- 描述: 天生反骨的少年英雄,拥有超凡的力量和勇气``- 配音: 吕艳婷``- 性格特点: 叛逆不羁,重情重义,敢于挑战命运`` ``### 哪吒的关系网络``- 父亲: 李靖(陈塘关总兵,严厉正直)``- 母亲: 殷夫人(温柔慈爱,理解包容)``- 师父: 太乙真人(循循善诱,关爱弟子)``- 挚友: 敖丙(东海三太子,冰雪之力)``- 敌人: 申公豹(截教弟子,处处作梗)`` ``### 哪吒的剧情发展``- 初遇敖丙: 在东海边缘的相遇,两个不同世界的少年``- 修行历程: 在太乙真人门下学习法术,逐渐掌握雷电之力``- 友情萌芽: 与敖丙从互不理解到成为挚友``- 身份困扰: 面对阐教弟子和凡人双重身份的矛盾``- 成长蜕变: 在各种挑战中突破自我,寻找真我`` ``### 哪吒的能力特点``- 主要法术: 雷电操控,混天绫,乾坤圈``- 战斗风格: 灵活多变,攻击凌厉``- 特殊天赋: 天生具有超凡力量``- 成长轨迹: 从初学者到掌握强大法力`` ``## 敖丙``- 名称: 敖丙``- 属性: 冰雪``- 阵营: 龙族``- 描述: 东海三太子,温润如玉的贵族少年``- 配音: 瀚墨``- 性格特点: 温和有礼,重情重义,内心坚韧`` ``### 敖丙的关系网络``- 父亲: 敖光(东海龙王,威严庄重)``- 兄弟姐妹: `` - 敖闰(龙女,擅长空间法术)` `- 敖顺(二皇子,精通毒术)` `- 敖钦(大皇子,掌控火焰)``- 挚友: 哪吒(阐教弟子,雷电之力)``- 属下: 结界兽(守护东海结界)`` ``### 敖丙的剧情发展``- 身份困扰: 作为龙族继承人的责任与压力``- 友情抉择: 在族群立场与个人情谊间的挣扎``- 能力觉醒: 冰雪之力的不断提升与掌控``- 性格成长: 从谨慎拘谨到开朗自信``- 守护之道: 保护东海与亲友的决心`` ``### 敖丙的能力特点``- 主要法术: 冰雪操控,水系法术``- 战斗风格: 优雅从容,防守反击``- 特殊天赋: 天生亲和水元素``- 成长轨迹: 从单纯的王子到独当一面`` ``## 太乙真人``- 名称: 太乙真人``- 属性: 云雾``- 阵营: 阐教``- 描述: 阐教重要弟子,哪吒的师父``- 配音: 张珈铭``- 性格特点: 智慧通达,慈悲为怀`` ``### 太乙真人的关系网络``- 弟子: 哪吒(得意门生)``- 同门: 其他阐教仙人``- 对手: 申公豹(截教弟子)`` ``### 太乙真人的剧情参与``- 收徒教导: 发现哪吒天赋,悉心培养``- 化解危机: 多次调解哪吒与各方矛盾``- 守护正道: 对抗截教势力的渗透`` ``# 阵营势力分析`` ``## 阐教``- 代表人物: 太乙真人、哪吒``- 特点: 崇尚正统,重视秩序``- 立场: 维护天地秩序,抵制混乱``- 修行特色: 注重心性修养,讲究循序渐进`` ``### 阐教的理念``- 修行观: 重视内在修养``- 处世态度: 主动干预,匡扶正义``- 对待人间: 既重视规则,也关注个体`` ``## 龙族``- 代表人物: 敖光、敖丙``- 特点: 高贵优雅,重视传统``- 立场: 守护东海,维护龙族利益``- 统治方式: 等级分明,讲究礼制`` ``### 龙族的传统``- 治理理念: 重视血脉传承``- 对外态度: 谨慎自守,避免冲突``- 内部规则: 等级森严,重视礼法`` ``## 截教``- 代表人物: 申公豹``- 特点: 包容驳杂,手段灵活``- 立场: 追求变革,不拘一格``- 行事风格: 灵活多变,善用权谋`` ``### 截教的特点``- 修行方式: 讲究实用``- 处世态度: 积极进取,不拘形式``- 发展策略: 广收门徒,扩张势力`` ``# 重要事件与剧情发展`` ``## 东海危机``### 事件起因``- 结界异常``- 势力冲突``- 个人恩怨`` ``### 事件发展``- 哪吒与敖丙的相遇``- 各方势力的介入``- 矛盾的激化与升级`` ``### 事件影响``- 个人成长``- 势力变化``- 关系转变`` ``## 人物关系演变``### 友情的考验``- 立场差异``- 信任建立``- 共同成长`` ``### 师徒情谊``- 教导方式``- 互相理解``- 成长蜕变
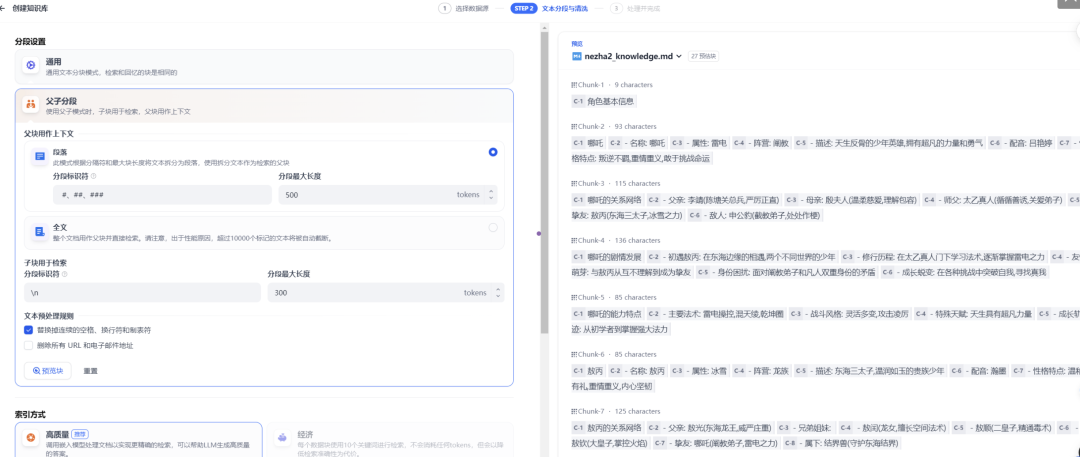
(4)新建知识库并开启父子模式
(5)测试效果
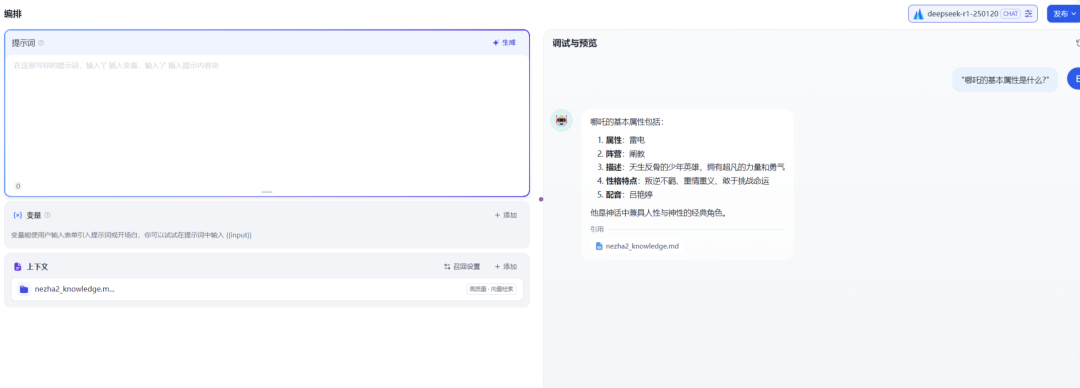
测试单层信息获取
"哪吒的基本属性是什么?"
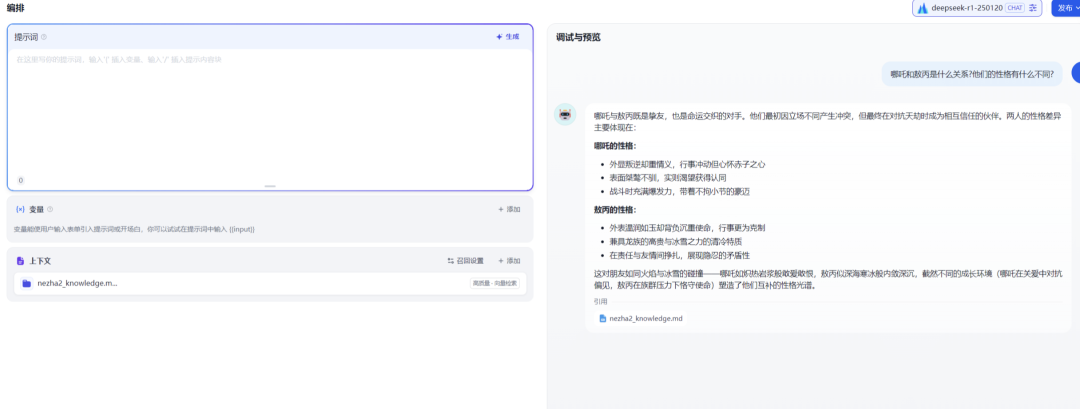
测试关系信息理解
"哪吒和敖丙是什么关系?他们的性格有什么不同?"
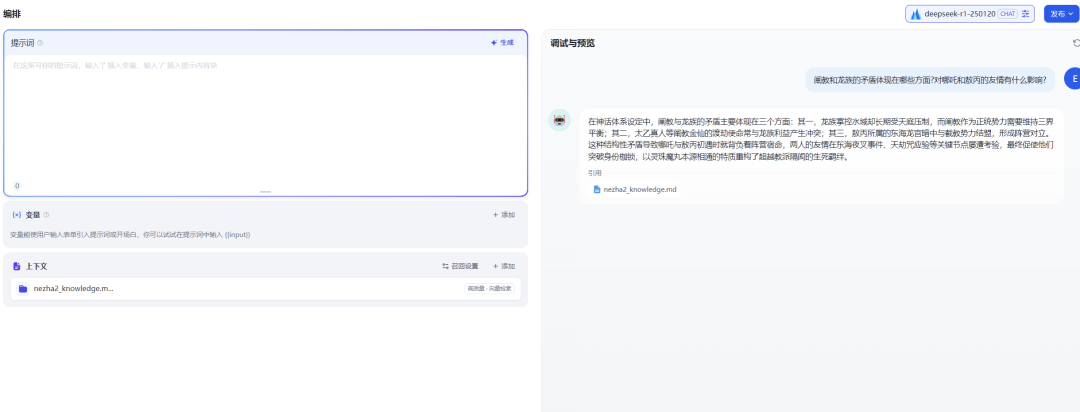
测试跨层级推理
"阐教和龙族的矛盾体现在哪些方面?对哪吒和敖丙的友情有什么影响?"
03
不同RAG模式维度对比
| 维度 | RAG | GraphRag | deepsearcher |
| 检索机制 | 向量相似性搜索,平坦检索 | 图关系查询,基于实体和关系的检索 | 粗到细的渐进检索,多阶段筛选候选 |
| 上下文处理 | 通过文本拼接提供上下文,简单直接 | 利用知识图谱关系,上下文结构化丰富 | 通过多阶段精炼,逐步提升上下文相关性 |
| 效率与扩展性 | 适合中小数据集,平坦检索可能效率低 | 处理复杂关系,图规模大时效率可能下降 | 设计为高效处理大数据,平衡效果与效率 |
| 准确性与相关性 | 依赖嵌入质量,相关性受限于检索文档 | 结构化关系提升准确性,适合复杂查询 | 多阶段精炼提高准确性,适合动态更新信息 |
| 实现复杂度 | 简单,使用标准库如LangChain即可 | 复杂,需要构建和维护知识图谱 | 较复杂,涉及多阶段检索管道,需高级设置 |
04
写在最后
1.DeepSearcher 的概念先进性
DeepSearcher 的先进性在于它突破了传统检索和生成的分步模式,深度整合深度学习,优化整个搜索过程。其核心优势包括:
更智能的检索:语言模型参与检索过程,例如生成候选查询或重新排序结果,提升相关性。例如,面对“如何选择适合我的手机?”,DeepSearcher 可根据用户历史生成更精准的检索条件。
适应性强:通过反馈循环(如强化学习)优化搜索,基于用户行为不断改进。例如,搜索结果不满意时,系统可学习调整策略。多模态支持:能处理文本、图片、视频等混合数据,适合现代应用需求,如搜索“展示红色跑车的图片和相关新闻”。
个性化能力:深度学习模型可根据用户偏好定制搜索结果,相比 RAG 和 GraphRAG 的静态检索更灵活。令人惊讶的是,DeepSearcher 的搜索过程更像人类思考,能理解上下文和意图,但这也带来效率和解释性的挑战。
2.实现 DeepSearcher 面临以下实际挑战
集成复杂性:将语言模型与搜索索引深度整合,需要设计高效的架构。例如,如何在不牺牲性能的情况下让语言模型参与检索?
实时更新:处理实时数据更新(如股票价格变化)时,确保模型及时适应,技术难度较高。系统复杂性:DeepSearcher 可能涉及多个组件(如检索模块、生成模块、学习模块),增加维护和故障排查难度。
RAG 和 GraphRAG 是成熟的范式,分别适合文档检索和关系查询,而 DeepSearcher 代表未来方向,通过深度学习优化搜索过程,适合复杂、个性化的需求。尽管它潜力巨大,但效率、解释性和数据需求仍是需要攻克的难题。实现中需关注集成复杂性和实时性,确保系统在实际应用中表现稳定。
## AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 108
108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









