









《Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation》
论文链接:https://arxiv.org/abs/1802.02611
tensorflow 官方实现: https://github.com/tensorflow/models/tree/master/research/deeplab
本文主要参考了CSDN 中的一篇文章:https://blog.csdn.net/u011974639/article/details/79518175 ,感谢博主的分享
Abstract
分割任务中常见的结构有空间金字塔池化模型(Spatial pyramid pooling module)与编码-解码结构,前者通过多个速率(rates)和多个有效视场(field-of-view)的过滤器(filter)或池化操作传入特征来编码多尺度的上下文信息,而后者网络可以通过逐渐恢复空间来捕获更清晰的对象边界信息。该文的改进:(1)DeepLabv3+ 在DeepLabv3的基础上增加了一个decoder 模型来是增强分割结果,尤其是物体边缘的分割。(2)引用了Xception中的深度可分卷积(depthwise separable convolution),应用在ASPP(Atrous Spatial Pyramid Pooling)和decoder 模型上,提高了encoder-decoder 网络的训练速度和健壮性。将模型用于 PASCAL VOC 2012 和 Cityscapes 数据上且不使用任何后处理,分别得到 89.0% 和 82.1% 的IoU。
介绍
语义分割的目的是为图像中的每个像素分配语义标签,这是计算机视觉中的基本主题之一。 在这项工作中,我们考虑使用空间金字塔池模块[18,19,20]或编码器 - 解码器结构[21,22]进行语义分割的两种类型的神经网络,其中前者通过汇集特征在不同的分辨率下来捕获丰富的上下文信息,而后者能够获得尖锐的物体边界。
为了获取不同尺度的上下文信息,DeelLab3 使用了不同速率的 atrous convolution,虽然最终的 feature map 包含了丰富的语义信息,但由于池化操作或卷积中的补偿影响,边缘信息会丢失,这可以通过应用atrous concolution 来提取更密集的特征映射来缓解。然而,考虑到现有神经网络的设计和有限的GPU内存,提取比输入分辨率小8甚至4倍的输出feature map在计算上是行不通的(即如果输出的feature map 过大会导致计算资源的问题,内存不够等)。以ResNet-101为例,当应用atrous卷积提取比输入分辨率小16倍的输出特征时,最后3个残余块(9层)内的特征必须扩大。更糟糕的是,如果需要比输入小8倍的输出特征,则会影响26个残余块(78层!)。因此,如果为这种类型的模型提取更密集的输出特征,则计算量会很大。另一方面,编码器 - 解码器模型使其自身在编码器路径中更快地计算(因为没有特征被扩张)并且逐渐恢复解码器路径中的尖锐对象边界。为了结合两种方法的优点,我们建议通过结合多尺度上下文信息来丰富编码器 - 解码器网络中的编码器模块。
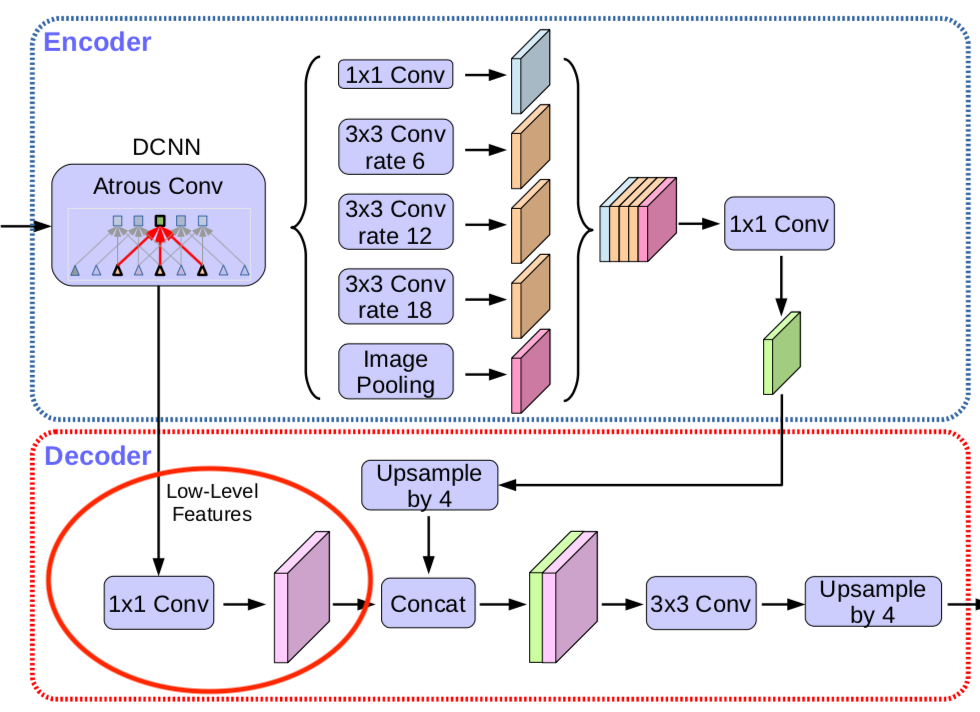
在DeepLabv3+中,使用了两种类型的神经网络,使用空间金字塔模块和encoder-decoder结构做语义分割。DeepLabv3+结合这两者的优点,在DeepLabv3的基础上拓展了一个简单有效的模块用于恢复边界信息。如下图所示:
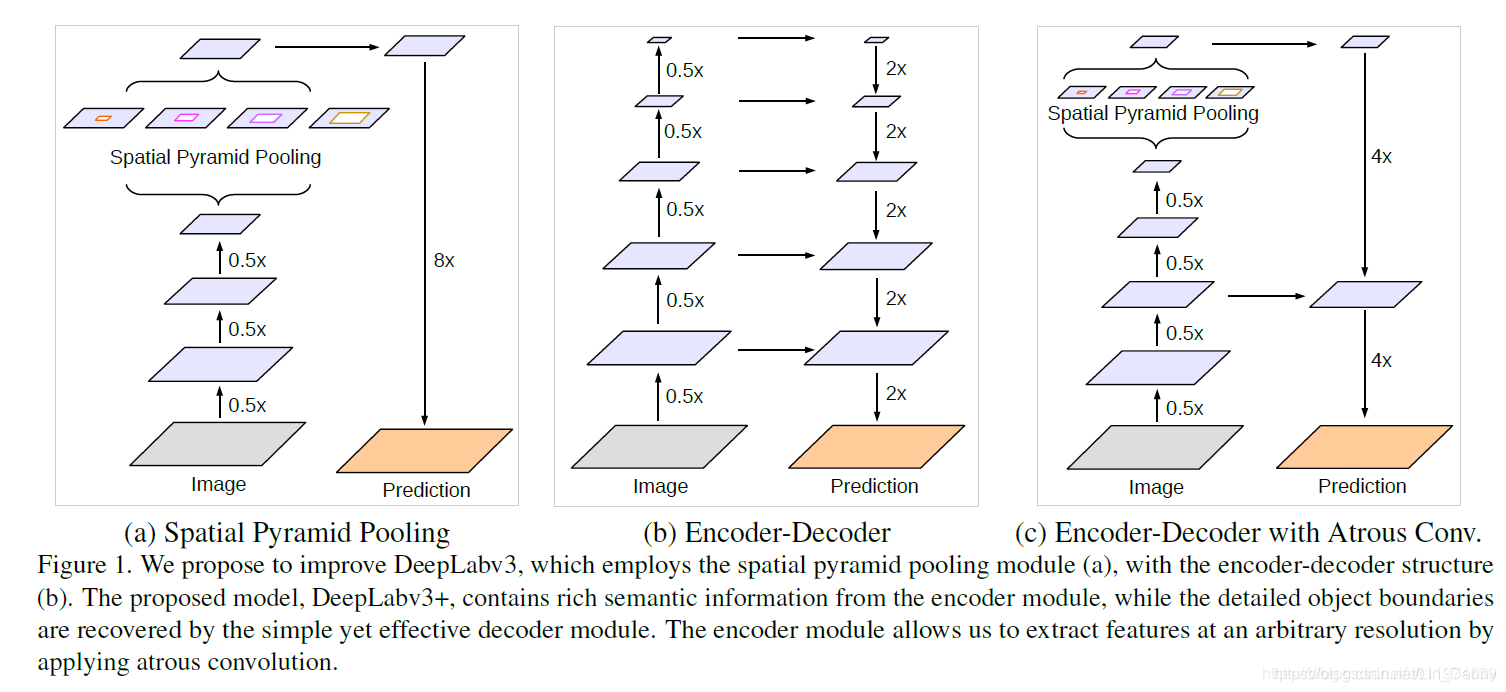
(a): DeepLabv3的结构,使用ASPP模块获取多尺度上下文信息,直接上采样得到预测结果
(b): encoder-decoder结构,高层特征提供语义,decoder逐步恢复边界信息
©: DeepLabv3+结构,以DeepLabv3为encoder,decoder结构简单
DeepLabv3的top layer输出的feature中有丰富的语义信息,可通过扩张卷积依据计算资源限制控制计算密度,配合一个decoder模块用于逐渐恢复边界信息。
在上述的encoder-decoder架构上,论文受到Xception等工作启发,将深度分离卷积应用到ASPP和decoder模块,用于快速计算并保持模型的强大学习能力。最终得到的模型在没有添加后端处理的情况下,达到了新的state-of-the-art.
论文的主要贡献在于:
- 论文提出了一个全新的encoder-decoder架构,使用DeepLabv3作为encoder模块,并添加了一个简单却有效的decoder模块
- 在提出的encoder-decoder架构中,可通过扩张卷积(atrous concolution)直接控制提取encoder特征的分辨率,用于平衡精度和运行时间
- 论文将Xception结构应用于分割任务中,在ASPP和decoder模块中加入深度分离卷积,获得到强大又快速的模型
- 模型达到了新的state-of-the-art,同时我们给出了模型设计分析细节和模型变体
Related Work
近几年基于全卷积神经网络的模型在语义分割任务上表现很好,有几种变体模型提出利用上下文信息包括多尺度输入在内的做分割,也有采用概率图模型细化分割结果。本文主要讨论使用空间金字塔池化和encoder-decoder结构、并讨论了基于Xception为主体的强大特征提取层,和基于深度分离卷积快速计算。
**空间金字塔池化(spatial pyramid pooling):**如PSPNet,DeepLab 使用多个不同网格尺度(grid scales)进行池化操作,或者使用多个不同rates的平行的 atrous卷积(称为 ASPP),这些模型在多个benchmark 都获得了不错的结果。
Encoder-Decoder: encoder-decoder结构在多个计算机视觉任务上获得成功,例如人类姿态估计、目标检测和语义分割。通常,encoder-decoder网络包含:
-
encoder模块逐步减少feature map分辨率,捕获高级语义信息
-
decoder模块逐渐恢复空间信息
在这领域上基础上,我们使用DeepLabv3作为encoder模块,并增加一个简单又有效的的decoder模块获取空间信息。
深度分离卷积: 深度分离卷积(depthwise seperable convolution)或组卷积(froup convolution)能够在减少计算消耗和参数量的同时取得相似或更好的表现,深度分离卷积已应用在多个神经网络中。我们探索了Xception架构(即使用Xception 作为 backbone),结果表明,我们的模型在语义分割任务上展现了精度和速度上的双重提升。
Methods
本节简明介绍扩张卷积和深度分离卷积,然后回顾用于DeepLabv3+ 架构中的encoder模块——DeepLabv3架构,最后展示改进后的Xception模型。
Encoder-Decoder with Atrous Convolution
Atrous Convolution:Atrous卷积推广了标准卷积运算,它允许我们明确地控制深度卷积神经网络计算的特征的分辨率,并调整滤波器的视场以捕获多尺度信息。
考虑到二维信号上使用空洞卷积,对于位置
i
i
i,在输入为
x
x
x 上应用滤波器$ w
,
输
出
为
,输出为
,输出为y$ :
y
[
i
]
=
∑
k
x
[
i
+
r
k
]
w
[
k
]
y[i] = \sum_k x[i + r k] w [k]
y[i]=k∑x[i+rk]w[k]
其中速率r 在采样点之间引入r−1个零,有效的将感受野从k×k扩展到
k
e
=
k
+
(
k
−
1
)
k_e=k+(k-1)
ke=k+(k−1),而不增加参数和计算量。
Depthwise separable convolution:深度分离卷积在MobileNet里面重点讲过,这里简单说一下:
深度可分离卷积的作用是:把标准卷积分解成深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。深度卷积对每个通道独立使用空间卷积,逐点卷积用于结合深度卷积的输出,如下图所示。深度分离卷积可以大幅度降低参数量和计算量。
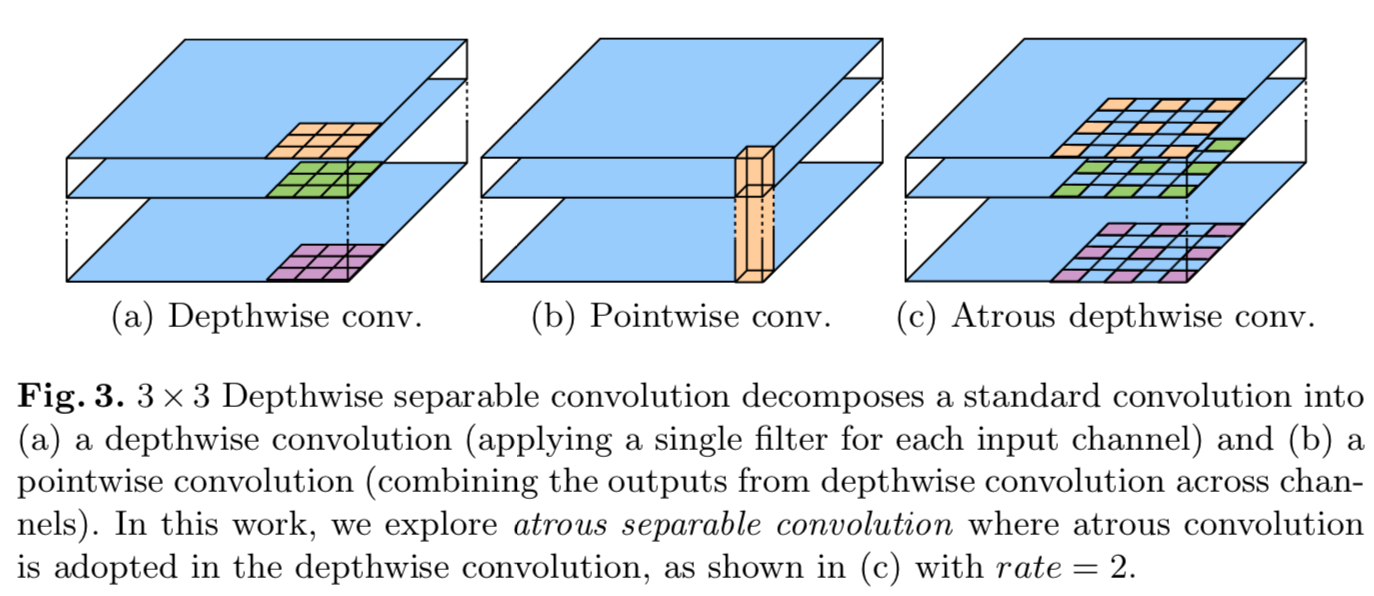
我们将atrous卷积和深度分离卷积结合到一起,即扩张分离卷积,如上图。扩张分离卷积能够显著的减少模型的计算复杂度并维持相似的表现。
DeepLabv3 as encoder:
DeepLabv3中也使用atrous卷积提取特征。我们将输入和输出的分辨率比值记为output_stride,对于图像分类任务,最终的feature map 的大小一般是输入图像的 1/32,即 output_stride=32;对于语义分割任务,将下采样(普通卷积操作)替换为atrous卷积,这样就可以调整 output_stride = 16(或8),从而进行更密集的特征提取(例如,我们应用rate = 2和rate = 4到最后两个blocks,则output_stride = 8)。
DeepLabv3的ASPP模块使用了多个平行的atrous卷积,配合了图像级特征(即全局平均池化)。我们将DeepLabv3的logit前的输出特征作为encoder-decoder模型的encoder输出。此时输出的feature通道为256并包含丰富的语义信息。另外,可已通过使用 atrous 卷积来匹配计算资源的限制。
Proposed decoder:
在原先的DeepLabv3中,取预测的feature 直接双线性上采样16倍到期望尺寸,这样的简易的decoder模块不能成功的恢复分割细节。因此加入了一个有效的 decoder 模块,如下图所示:编码器特征先进行 factor=4 的双线性上采样,然后与具有相同空间分辨率的网络主干的相应低级特征(例如,在ResNet-101 [25]中跨越之前的Conv2)连接在一起。
DeepLabv3+的整体的架构如下图所示:
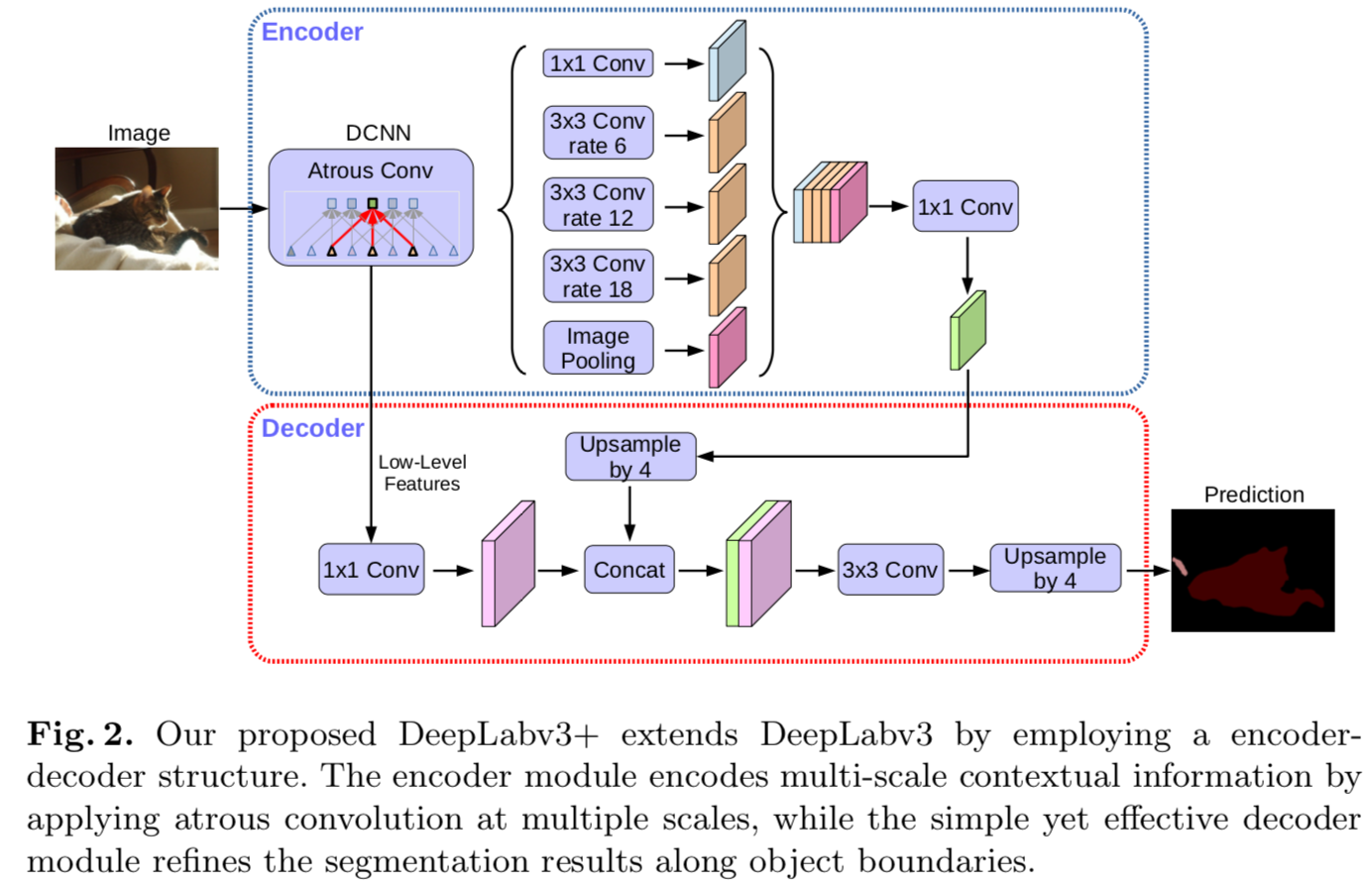
简单说一下decoder的组成:
-
encoder输出的feature的output_stride=16,经过 factor=4 的双线性上采样得到 low_level features F L F_L FL, F L F_L FL 的 o u t p u t s t r i d e = 4 output_stride=4 outputstride=4
-
再取encoder中对应着相同分辨率(即output_stride=4 )的特征层,经过1×1卷积降通道,此时输出的features记为 F H F_H FH 。这里为什么要经过1×1卷积降通道,是因为此分辨率的特征通道较多(256或512),而 F L F_L FL 输出只有256,故降通道以保持与 F L F_L FL 所占比重,利于模型学习。
-
将 F L F_L FL 和 F H F_H FH 做连接,再经过一个3×3 卷积细化feature,最终再双线性上采样4倍得到预测结果.
在实验部分展示了output_stride=16是在速度和精度上最佳的平衡点,使用output_stride=8 能够进一步提升精度,但同时伴随着是更大的计算消耗。
Modified Aligned Xcetpion
论文受到近期[MSRA组在Xception上改进工作](Aligned Xception,《Deformable convolutional networks – coco detection and segmentation challenge 2017 entry》. ICCV COCO Challenge Workshop (2017))的启发,Deformable-ConvNets对Xception做了改进,能够进一步提升模型学习能力,Aligned Xception的结构如下:
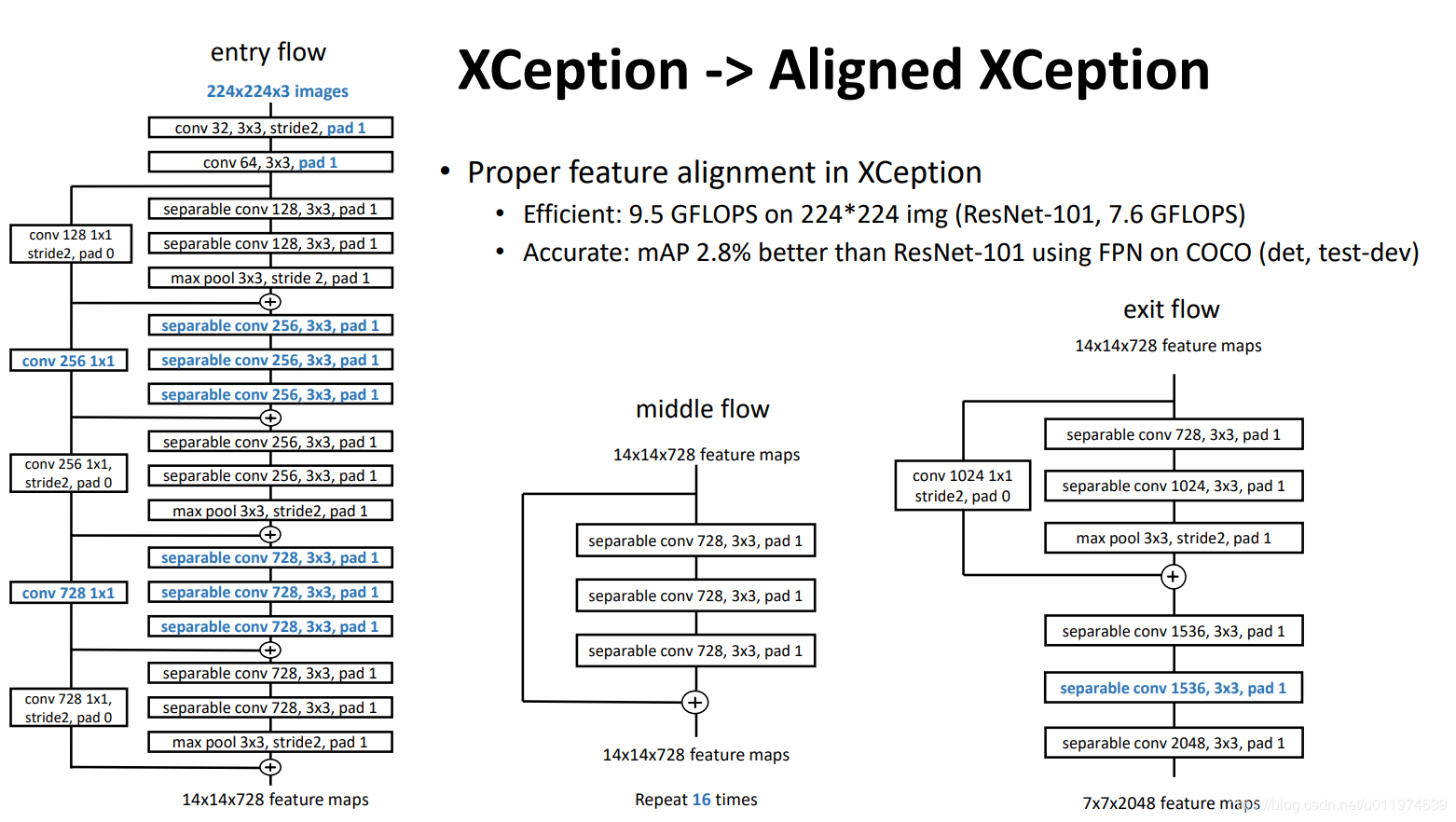
论文在MSRA的工作的基础上,进一步改进以适应语义分割任务:
- 采用与Aligned Xception 相同的结构,不同的地方在于不修改entry flow network的结构,以便快速计算和有效的使用内存
- 所有的最大池化操作替换成带下采样的深度分离卷积,这能够应用扩张分离卷积扩展feature的分辨率
- 与 [MobileNet](An-dreetto, M., Adam, H.: Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861 (2017)) 的设计相似,在每个3×3 深度卷积后增加BN层和ReLU
改进后的Xception整体结构如下:
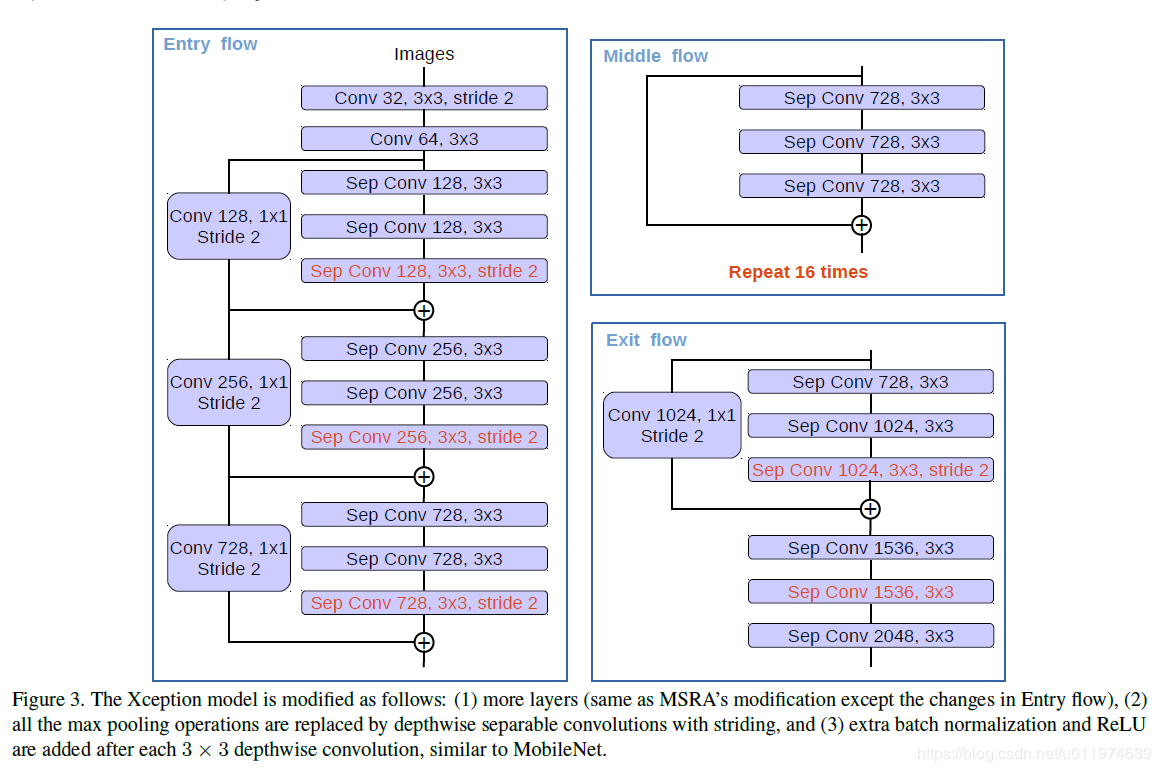
改进后的Xception为encodet网络主体,替换原本DeepLabv3的ResNet101.
Experiment
我们采用ImageNet-1k预训练的ResNet-101或修改后的Aligned Xception 来通过taros 卷积提取密集的特征图。采用与 DeepLabv3 相同的训练方式,简而言之,当output_stride = 16时,在训练期间使用相同的学习率计划(即[“poly”策略](Liu, W., Rabinovich, A., Berg, A.C.: Parsenet: Looking wider to see better. arXiv:1506.04579 (2015))和相同的初始学习率0.007)、crop大小513×513 、 batch normalization 参数,以及随机比例数据增强(random scale data augmentation) 。 请注意,我们还在解码器模块中包含批量标准化参数。
这里提出的模型是端到端(end-to-end)训练的,没有对每个组件进行分段预训练。。
Decoder Design Choise
用DeepLabv3作为encoder,对于f 个k×k 的卷积操作记为$[k×k,f] $,先前DeepLabv3是在输出结果上继续双线性上采样16倍得到预测结果,这在PASCAL VOC2012 验证集上达到了77.21%。论文在此基础上,提出了改进的decoder模块。关于decoder的设计有多个方案:
使用1×1卷积减少来自低级feature的通道数
下图示意部分为1×1 卷积:
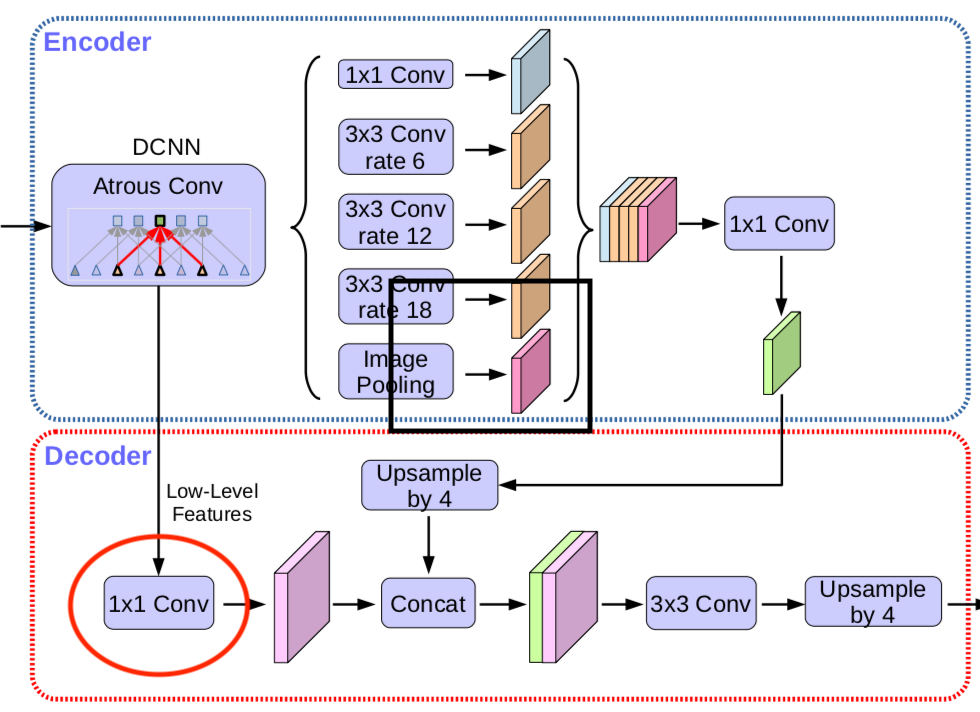
为了评估1×1 卷积的重要性,在encoder中取了 Conv2 尺寸为[3×3,256] 为输出,减少通道数在48到32之间性能最佳。结果如下表:

最终采用了[1×1,48]来做通道降维。
是否需要3×3卷积逐步获取分割结果
即下图示意部分3×3卷积恢复信息:
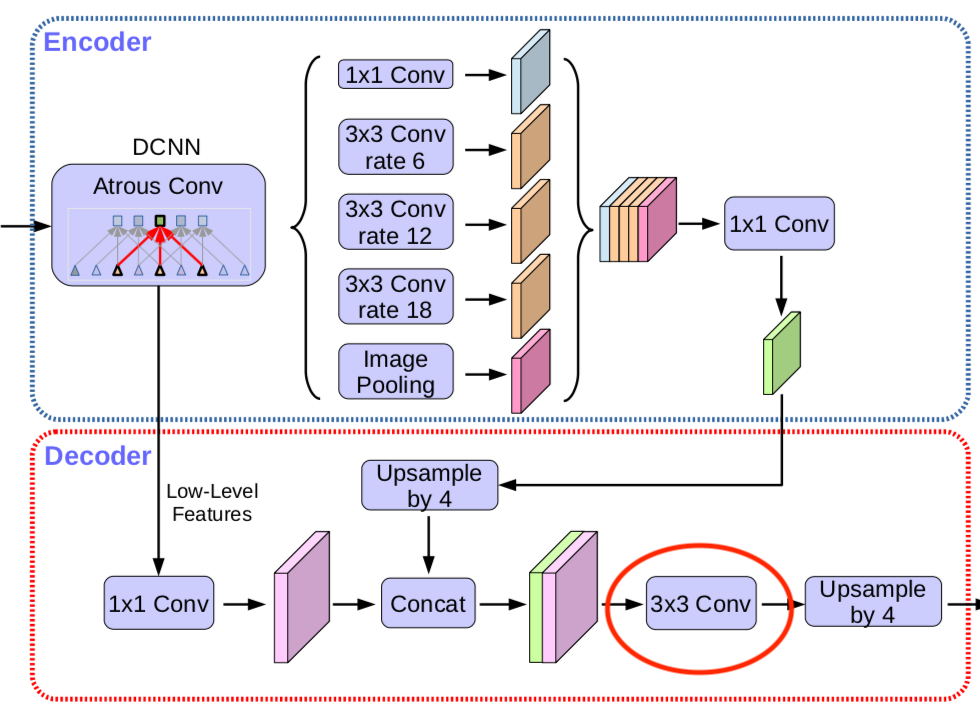
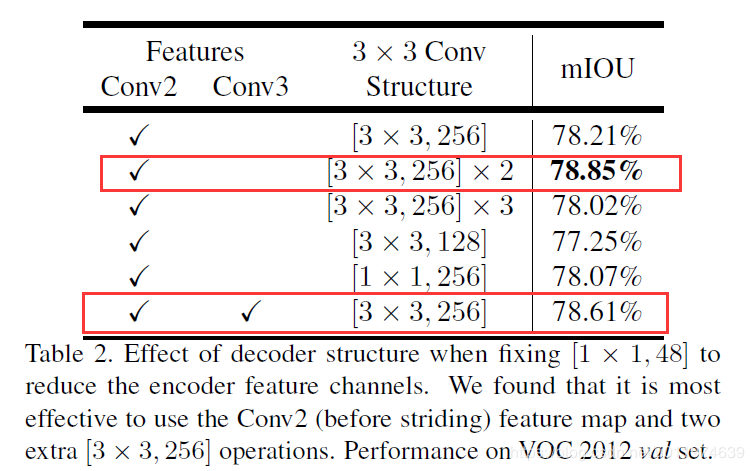
实验部分包括使用1×1,256 的卷积,一组、二组、三组的3×3,256 卷积,使用3×3,128 的卷积,结果如下:
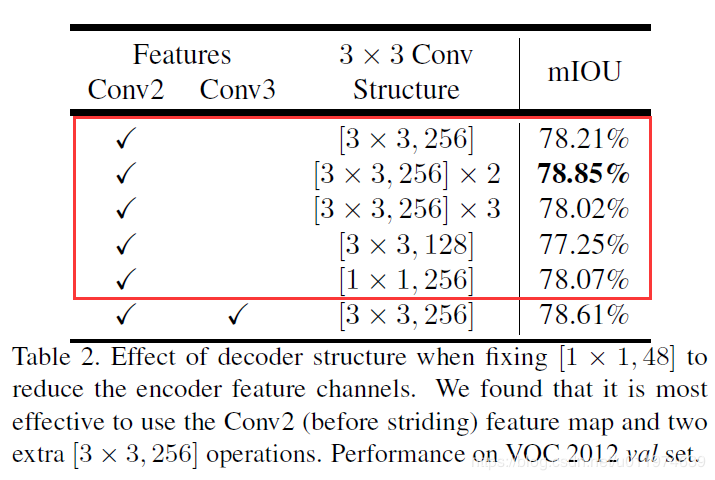
结果显示使用两组3×3,256 卷积性能最佳。
使用哪部分的低级特征帮助提供细节
即下图示意部分:
论文实验了如果使用Conv2 和Conv3 同时预测,Conv2 上采样2倍后与Conv3 结合,再上采样2倍,结果如下:
这并没有显著的提升性能,考虑到计算资源的限制,论文最终采样简单的decoder方案,即取Conv2 Conv2Conv2上采样后再与top feature concatenate。
ResNet-101 as Network Backbone
以ResNet为encoder模型,测试了以下几种变体:
- Baseline: 在下表的第一组。都没有使用decoder。测试了不同output_stride output_strideoutput_stride,多尺度输入,左右翻转操作。
- Adding decoder: 下表的第二组。采用的encoder。平均多增加了20B的计算消耗。
- Coarser feature maps: 测试了使用output_stride=32 ,这样计算速度更快。但是相对于output_stride=16 准确率下降了1-2%左右。
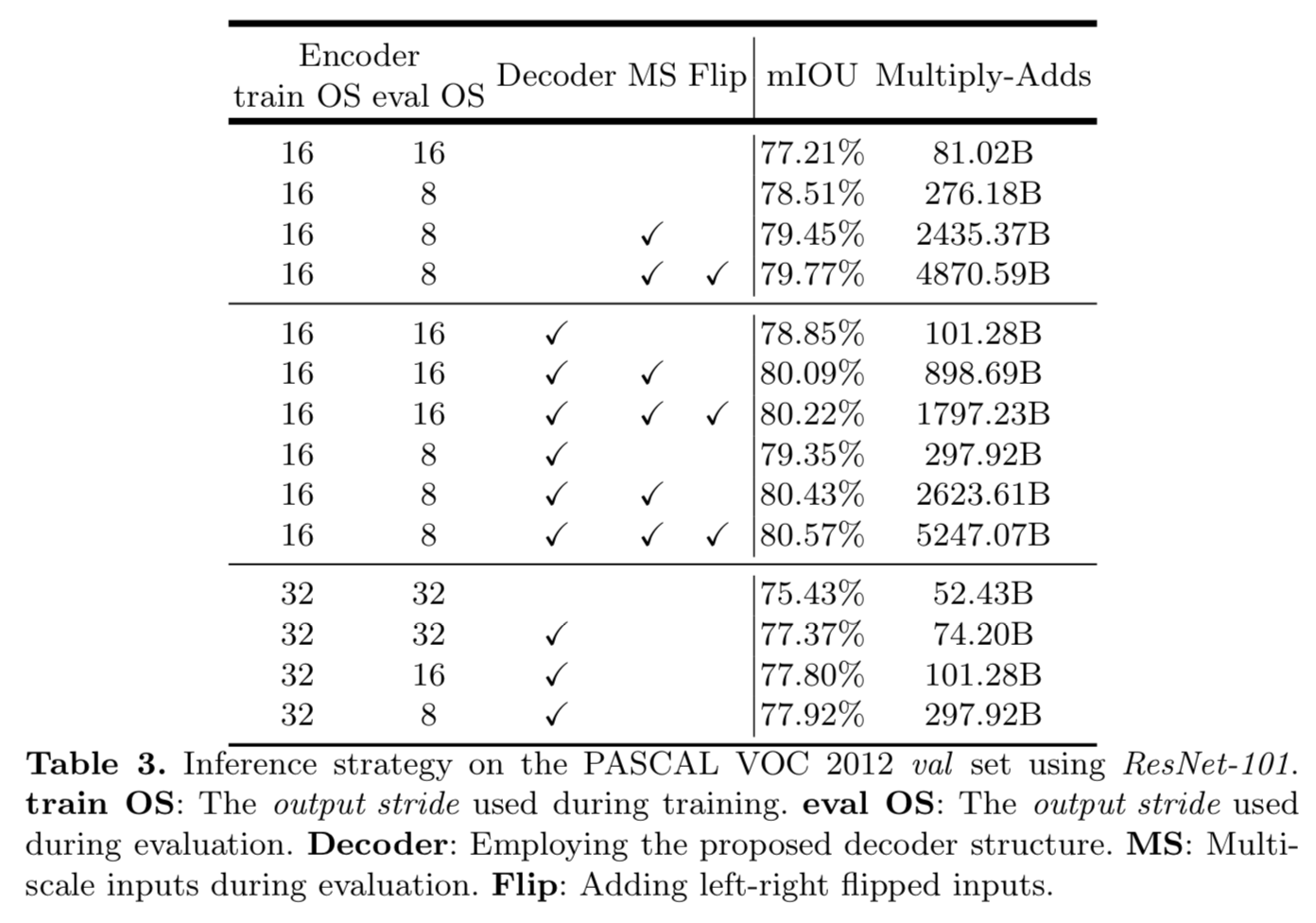
可以看到使用多尺度MS MSMS计算量计算量增加一个数量级,使用左右翻转Flip FlipFlip计算量翻倍。
Xception as Network Backbone
ImageNet pretraining: 改进后的Xception网络在ImageNet-1K上做了预训练。训练设置如下:
| 选项 | 配置 |
|---|---|
| 优化器 | Nesterov momentum optimizer,momentum = 0.9 |
| 学习率 | 初始学习率0.05,2个epochs衰减0.94 |
| weight_decay | 4e-5 |
| 硬件 | 同步使用50 GPUs |
| batchsize | 每个GPU取32 |
| image size | 299x299 |

可以看到Modified Xception性能要好点。
整体的使用Modified Xception做为网络骨架,使用如下几种变体:
- Baseline: 不使用decoder.
- Adding decoder: 添加了decoder.
- Using depthwise separable convolution: 在ASPP和decoder中使用深度分离卷积。计算量下降了30-40%.
- Pretraining on COCO: 在MS-COCO数据集上预训练
- Pretraining on JFT: 在IamgeNet-1K和JFT-300M上预训练
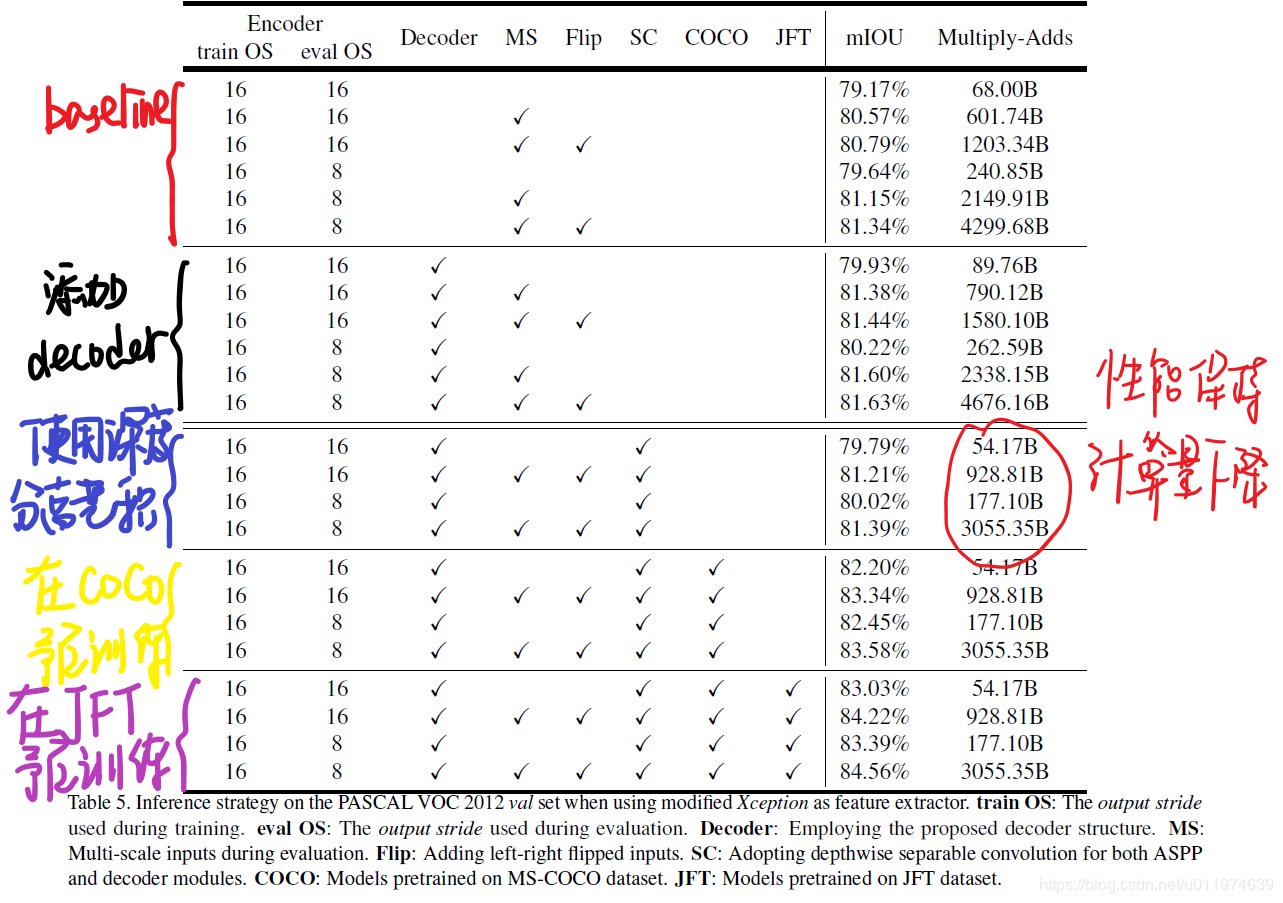
上图copy 自博客https://blog.csdn.net/u011974639/article/details/79518175
可以看到使用深度分离卷积可以显著降低计算消耗。
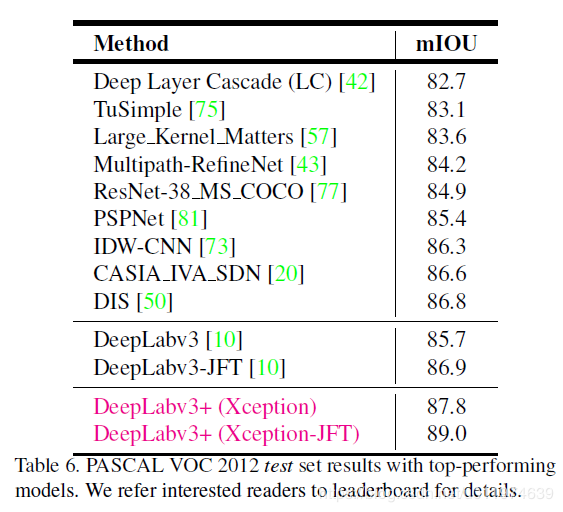
与其他先进模型在VOC12的测试集上对比:
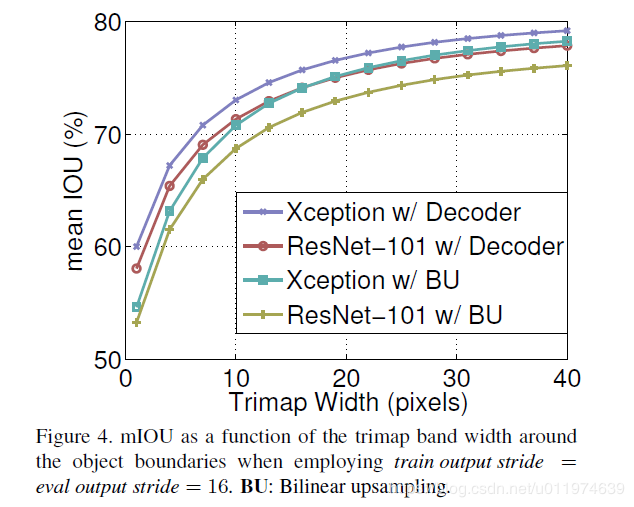
在目标边界上的提升
使用trimap实验测量模型在分割边界的准确度。计算边界周围扩展频带(称为trimap)内的mIoU。结果如下:
与双线性上采样相比,加decoder的有明显的提升。trimap越小效果越明显。
加了decoder的可视化结果如下:

















 2048
2048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









