







今天分享另一篇利用CLIP预训练模型进行聚类的论文,首先对于这个题目的THE PRINCIPLE OF RATE REDUCTION我是比较困惑的,我之前并没有接触过,但没关系,原文中会解释,文章中提到用the principle of Maximal Coding Rate Reduction来学习特征表示,这个原则叫做最大编码率衰减原则,详见出处[1]。 如果有对预训练模型感兴趣的,也可以看看我分享的上一篇来自CVPR的论文,指路[2]: CVPR 2024 论文研读 《MoDE: CLIP Data Experts via Clustering》-CSDN博客。
方法
模型的整体框架如下:
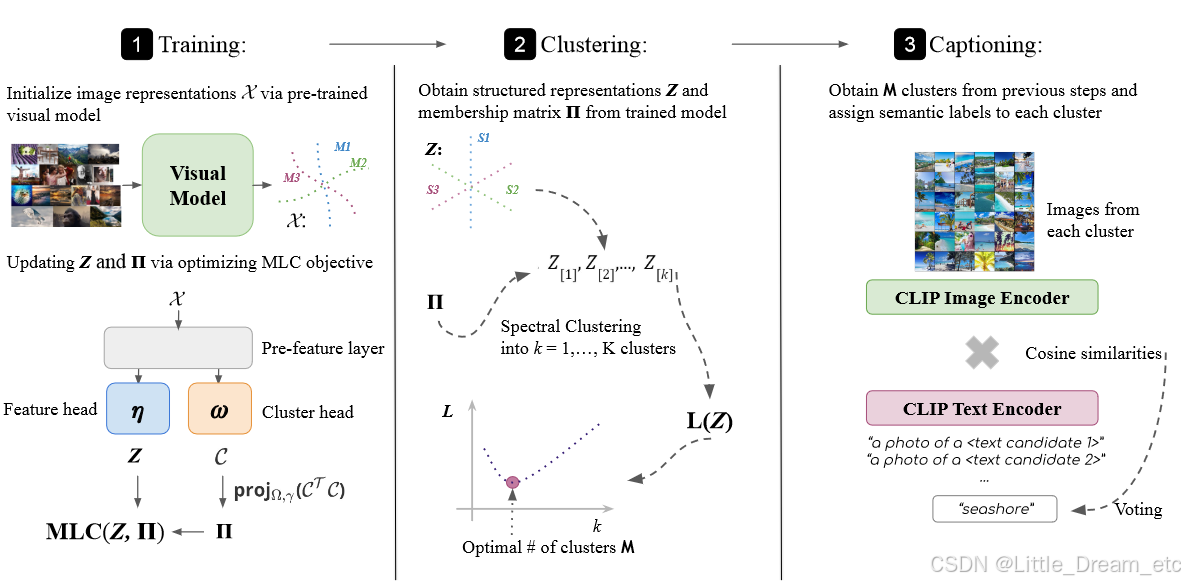
左:在训练阶段,CPP从一个大的预训练模型中初始化特征和聚类隶属度
,并通过优化( MLC )目标更新
和
。中间:一旦训练完成,CPP通过编码长度L ( · )准则选择最佳聚类数。右:CPP通过计算候选文本和图像之间的余弦相似度,并对最合适的标签进行投票,为每个类分配语义标签。
回顾MLC
最大编码率衰减原则
原文首先回顾了MLC(Ding et al., 2023),MLC考虑利用最大编码率衰减原则学习一个表示,并给出了如下定义:
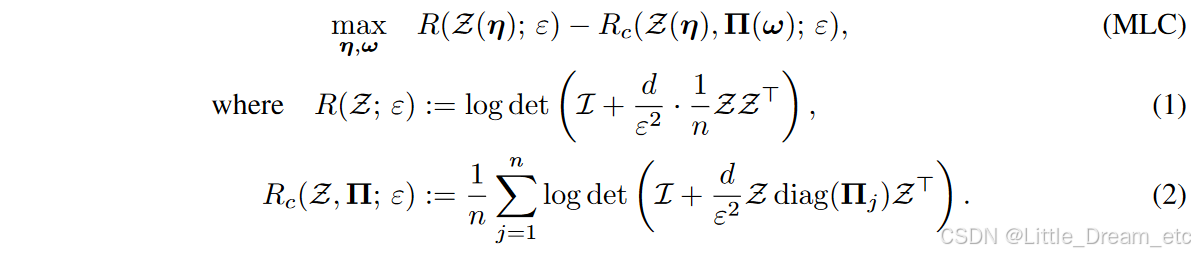
其中,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











