







看到一个名为在线梯度下降的方法,之前没有遇到过,今天再次看到就搜索一下
在线梯度下降的方法是考虑到在线学习的优化
在线学习是增量学习的一种。
在线学习:
online learning强调的是学习是实时的,流式的,每次训练不用使用全部样本,而是以之前训练好的模型为基础,每来一个样本就更新一次模型,这种方法叫做OGD(online gradient descent)。这样做的目的是快速地进行模型的更新,提升模型时效性。
在线学习认为数据的分布是可以任意的,甚至是为了破坏我们的策略而精心设计的。
统计学习考虑算法所求得到的模型与真实模型的差距。数据由真实模型产生,如果能有无限数据、并在包含有真实模型的空间里求解,也许我们能算出真是模 型。但实际上我们只有有限的有噪音的数据,这又限制我们只能使用相对简单的模型。所以,理想的算法是能够用不多的数据来得到一个不错的模型。
在线学习的一个主要限制是当前只能看到当前的和过去的数据,未来是未知,有可能完全颠覆现在的认知。因此,对在线学习而言,它追求的是知道所有数据 时所能设计的最优策略。同这个最优策略的差异称之为后悔(regret):后悔没能一开始就选定最优策略。我们的希望是,时间一久,数据一多,这个差异就 会变得很小。因为不对数据做任何假设,最优策略是否完美我们不关心(例如回答正确所有问题)。我们追求的是,没有后悔(no-regret)。
online learning其实细分又可以分为batch模式和delta模式。batch模式的时效性比delta模式要低一些。分析一下batch模式,比如昨天及昨天的数据训练成了模型M,那么今天的每一条训练数据在训练过程中都会更新一次模型M,从而生成今天的模型M1。
而batch learning或者叫offline learning强调的是每次训练都需要使用全量的样本,因而可能会面临数据量过大的问题。
batch learning一般进行多轮迭代来向最优解靠近。online learning没有多轮的概念,如果数据量不够或训练数据不够充分,通过copy多份同样的训练数据来模拟batch learning的多轮训练也是有效的方法。
SGD则每次只针对一个观测到的样本进行更新。通常情况下,SGD能够比GD“更快”地令 逼近最优值。当样本数 特别大的时候,SGD的优势更加明显,并且由于SGD针对观测到的“一条”样本更新 ,很适合进行增量计算,实现梯度下降的Online模式(OGD, OnlineGradient Descent)。
在线凸优化
回顾下上次聊的专家问题,在 时刻专家
时刻专家 的损失是
的损失是") ,于是这个时刻Weighted Majority(WM)损失的期望是
,于是这个时刻Weighted Majority(WM)损失的期望是") ,是关于这
,是关于这 个专家的损失的一个线性组合(因为权重
个专家的损失的一个线性组合(因为权重 关于的和为1,所以实际上是在一个simplex上)。将专家在时刻的损失看成是这个时候进来的数据点,于是我们便在这里使用了一个线性的损失函数。
关于的和为1,所以实际上是在一个simplex上)。将专家在时刻的损失看成是这个时候进来的数据点,于是我们便在这里使用了一个线性的损失函数。
虽然WM的理论在上个世纪完成了[Littlestone 94, Freund 99],将其理论拓展到一般的凸的函数还是在03年由Zinkevich完成的。当时Zinkevich还是CMU的学生,现在在Yahoo! Research。话说Yahoo! Research的learning相当强大,Alex Smola(kernel大佬),John Langford(有个非常著名的blog),这些年在large scale learning上工作很出色。
回到正题。我们提到在online learning中learner遭受的累计损失被记成") ,如果挑选
,如果挑选 的策略集
的策略集 是凸的,而且损失函数
是凸的,而且损失函数") 关于是凸的,那么我们称这个问题为Online Convex Optimization(OCP)。通常我们将表示成一个向量,例如WM中的
关于是凸的,那么我们称这个问题为Online Convex Optimization(OCP)。通常我们将表示成一个向量,例如WM中的 ,所以记
,所以记 。
。
在线梯度下降
Zinkevich提出的算法很简单,在时刻做两步操作,首先利用当前得到数据对进行一次梯度下降得到 ,如果新的不在中,那么将其投影进来:
,如果新的不在中,那么将其投影进来:
),")
这里") 是关于的导数(如果导数不唯一,就用次导数),
是关于的导数(如果导数不唯一,就用次导数), 是学习率,
是学习率,") 是投影子,其将不在中的向量
是投影子,其将不在中的向量 投影成一个与最近的但在中的向量(如果已经在中了,那就不做任何事),用公式表达就是
投影成一个与最近的但在中的向量(如果已经在中了,那就不做任何事),用公式表达就是=\arg\min_{y\in\mathcal{H}}\|x-y\|") 。此算法通常被称之为 Online Gradient Descent。
。此算法通常被称之为 Online Gradient Descent。
先来啰嗦几句其与离线梯度下降的区别。在离线的情况下,我们知道所有数据,所以能计算得到整个目标函数的梯度,从而朝最优解 迈出坚实的一步。而在online设定下,我们只根据当前的数据来计算一个梯度,其很可能与真实目标函数的梯度有一定的偏差。我们能保证的只是会减小的值,而对别的项的减少程度是未知的。当然,我们还是一直在朝目标前进,只是可能要走点弯路。
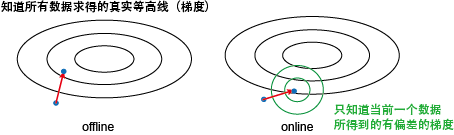
那online的优势在哪里呢?其关键是每走一步只需要看一下当前的一个数据,所以代价很小。而offline的算法每走一个要看下所有数据来算一 个真实梯度,所以代价很大。假定有100个数据,offline走10步就到最优,而online要100步才能到。但这样offline需要看1000 个数据,而online只要看100个数据,所以还是online代价小。
于是,我们很容易想到,offline的时候能不能每一步只随机抽几个数据点来算一个梯度呢?这样,每一步代价也会很少,而且可能总代价会和online一样的少。当然可以!这被称之为Stochastic Gradient Descent,非常高效,下回再谈把。
在这里,的作用是什么呢?记得在ML中的目标函数通常是损失+罚(+\lambda f(h)") )的形式。例如ridge regression就是平方误差+
)的形式。例如ridge regression就是平方误差+ 罚,lasso是平方误差+
罚,lasso是平方误差+ 罚,SVM是hinge loss+罚。最小化这个目标函数可以等价于在
罚,SVM是hinge loss+罚。最小化这个目标函数可以等价于在\le\delta") 的限制下最小化
的限制下最小化") 。
。 和
和 是一一对应的关系。实际上就是定义了一个凸子空间,例如使用罚时就是一个半径为的球。所以,Online Gradient Descent可以online的解这一类目标函数,只是对于不同的罚选择不同的投影子。
是一一对应的关系。实际上就是定义了一个凸子空间,例如使用罚时就是一个半径为的球。所以,Online Gradient Descent可以online的解这一类目标函数,只是对于不同的罚选择不同的投影子。
下面是理论分析。记投影前的")
") 。因为是凸的且
。因为是凸的且 在其中,所以对
在其中,所以对 投影只会减少其与的距离,既
投影只会减少其与的距离,既 。记
。记") ,注意到
,注意到

由于 是凸的,所以有
是凸的,所以有
-\ell_t(h^*)\le \langle\nabla_t,h_t-h^*\rangle \le \frac{1}{2\eta_t}\big(\|h_t-h^*\|^2 - \|h_{t+1}-h^*\|^2\big) + \frac{\eta_t}{2}\|\nabla_t\|^2.")
取固定的 ,对进行累加就有
,对进行累加就有\le \frac{1}{2\eta}\|w_1-w^*\|^2+\frac{\eta}{2}\sum_{t=1}^T\|\nabla_t\|^2") 。记的直径为
。记的直径为 ,且对所有有
,且对所有有 成立(既Lipschitz常数为
成立(既Lipschitz常数为 ),再取
),再取 ,那么
,那么
\le LD\sqrt{T}.")
这个bound可以通过设置变动的学习率加强
下面是参考在线学习算法
机器学习通过对训练数据集进行训练,获得相应的模型,如分类模型,回归模型等。对训练集数据进行训练有一个学习的过程。
一种是通过批量训练(学习),收集一批训练数据,对数据同时训练获得最终的参数模型。
一种是在线学习,一次仅训练一个样本,其过程可分成三个步骤:(1) 接收到一个样本;(2) 对该样本的标注进行预测;(3) 获得该样本的真实标注,算法根据该样本标注的反馈更新模型参数,获得函数标识。
与在线学习接近的是随机梯度下降。目前统计推理和机器学习均会建模,并使某一个目标函数最小化,如误差平方和。一个标准的更新方法是梯度下降法,即根据所有数据计算该目标函数的梯度,模型参数沿该梯度方向减少而获得更新。由于同时计算所有数据的梯度代价很大,计算非常复杂,因此,一种有效的更新方法应运而生,即通过一个样本获得的梯度去近似全数据获得的梯度。通过从训练集中多次随机采样的方法获得样本,经过多次迭代直到算法收敛。当数据有重复的时候,如重复一倍,批量梯度下降有一倍的计算冗余,而随机梯度下降则能避免上述问题,使得模型的更新更有效,因此被广泛使用。
可以理解为随机梯度下降法求解问题。
。















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









