







最近看Fractional Max-pooling 时,中提到了Dropconnect,一时间忘记了,就找出原文看了一下。
参考 原文:Regularization of Neural Networks using DropConnect
现在总结一下,
其实在实验中我们经常使用的是dropout ((Hinton et al., 2012).)方法,这篇文章提出的dropconnect的方法只是对其进行了简单的改进
dropout是在全连接时,进行的随机放弃连接,文中介绍其是在进行激活函数运算之后乘以一个二进制的掩码矩阵(矩阵的中的0,1是随机的),这样就是dropout的计算,这样可以起到减少overfitting的作用,具体是减少前后神经元的一种适应性的依赖(在我看来就是惯性吧)。

dropconnect则是在激活函数之前进行的随机去掉连接,可以减少一些计算吧。
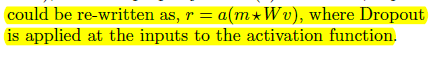
上面是从计算的角度看还是十分明显的,下面是参考网上的一篇的博文中的图,

将文中激活与权重看作是一个大的整体中的两个部分的话,这样的话,上图还是很清晰的。

这是原文中给出的图像,dropconnect的效果和dropoup比的话,会有一些提升,但是两者还是比较相似的,差别不大。















 453
453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









