






代码来源:GitHub - LittleNyima/code-snippets
1.ddpm与ddim采样时间和效果的对比
使用cifar-10数据集,训练轮数皆为50轮。采样过程均生成32张图。
ddpm:

Sampling took 58.68 seconds.
ddim:

Sampling completed in 1.44 seconds
对比可以看出,ddim的速度明显比ddpm快多了。不过效果嘛。。。可能是训练的次数不够吧,确实也看不出什么东西。不过ddpm训练出来的东西确实比ddim要少掉san些(?)
然后又用原作者提供的权重模型跑了一下两个的sampling:
DDPM:

Sampling took 60.04 seconds.
DDIM:

Sampling completed in 1.44 seconds
又用CelebA数据集跑了一次,选取了前10000张照片,100epoch
ddpm:

图片 ddpm_20250304-154744.png 用时 59.24 秒
ddim:

ddim_20250304_154848用时1.44 秒
2、ddpm采样过程中噪声项 的作用?
的作用?
测试了一下删除的效果(使用celebA数据集的训练结果)。发现无法生成图片。大部分的采样结果是一片黑,少部分的采样结果能隐约看见人的轮廓,背景为深蓝色,其余黑色。
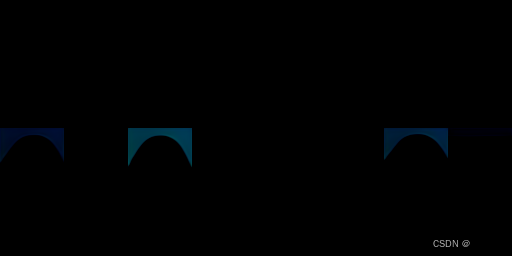
调节的系数大小,并比较
epsilon_scale = 0.5 # 0.1 ~ 1.0 之间的值
epsilon = epsilon_scale * torch.randn_like(images)
①epsilon_scale = 0.25

②epsilon_scale = 0.5

③epsilon_scale = 0.75

③epsilon_scale = 1.0

③epsilon_scale = 1.1

③epsilon_scale = 1.5
③epsilon_scale = 2
可以发现,随着系数的降低,sample出来的图像亮度降低,逐渐趋于同质化,且没有背景(背景为纯色)
以下为出现这个原因的一些猜想。
- ①噪声没有正确弥补,导致采样过程中图像亮度降低
在每个时间步 t,由 UNet 预测,但预测结果不可能完全准确,它会有 误差
,即:
如果 epsilon 过小,意味着 σ_t * ε 几乎被移除,每一步的计算变成:
由于 UNet 的噪声预测有 累积误差,这些误差没有被 σ_t * ε 平衡掉,而是 一步步减少图像信号的整体强度,导致亮度降低。
- ②生成的样本多样性降低,很多样本会塌缩
σ_t * ε 代表了 采样过程中增加的随机性,本质上它会给图像提供一些 额外的方差信息,防止采样塌缩。当 epsilon 过小,去噪的方差越来越小,使得生成图像的 像素值逐渐收敛到一个固定的均值,导致:生成的 不同样本变得越来越相似,缺乏多样性(趋于同质化),同时亮度逐渐衰减,因为整个图像像素值在不断向某个固定值塌缩。
3.ddim步数与生成时间、图像质量之间的关系
修改跳步采样时的步数
num_train_timesteps: int = 1000, # 训练时的时间步数
beta_start: float = 0.0001, # beta 的起始值
beta_end: float = 0.02, # beta 的结束值
sample_steps: int = 20, # 采样过程中使用的时间步数逐渐增加时间步数,查看采样结果与运行时间

sample_steps=2 ddim_20250304_165359用时0.40 秒

sample_steps=5 sample_steps=2ddim_20250304_165641用时0.58 秒

sample_steps=10 ddim_20250304_165818用时0.87 秒

sample_steps=20 ddim_20250304_170000用时1.43 秒

sample_steps=100 ddim_20250304_170139用时5.94 秒

sample_steps=500 ddim_20250304_170322用时28.86 秒

sample_steps=500 ddim_20250304_170634用时58.80 秒
采样的步数和生成时间大概成线性关系(或者是幂指数关系?)
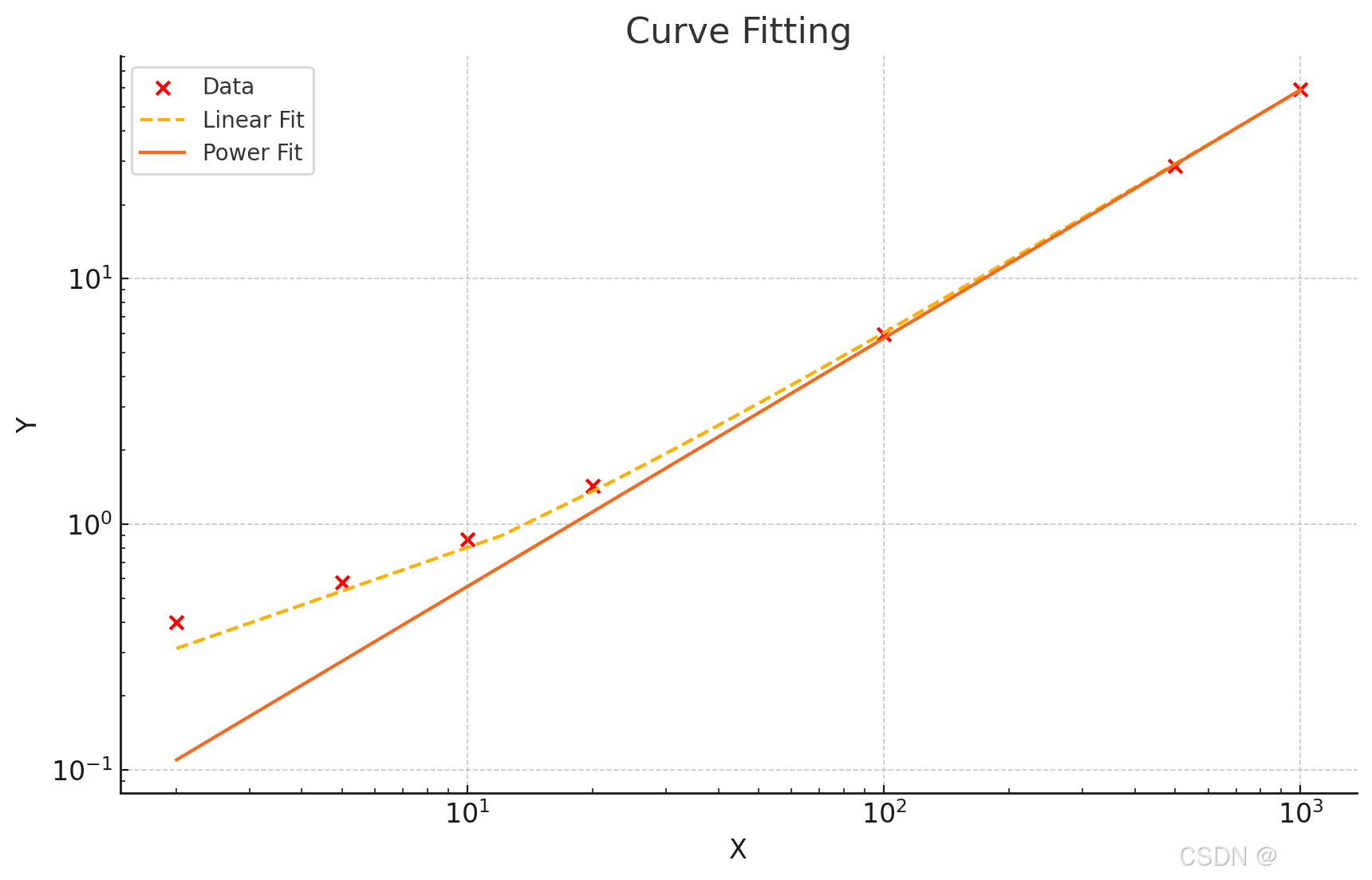
4.ddim增加随机值eta
以上所展示的图都是eta=0时的情况。下在不同的sample_steps情况下增加eta,查看训练效果。
首先是在sample_steps=20的情况下
eta=0.5

sample_steps=20,eta=1.0

好像也没什么变化?
以下是猜想:
初始噪声 (x_T) 是随机的:DDIM 采样仍然是 从随机噪声 x_T 开始的,即便 eta=0,初始输入 x_T 仍然是高斯噪声。由于 DDIM 只是一个 确定性的映射,不同的 x_T 仍然会导致不同的 x_0,所以 生成的样本还是多样的。
尝试在sample_steps=20比较小的情况下试一下

sample_steps=2,eta=1.0

可见ddim采样中,随机噪声项eta对于采样结果的影响并不大。原因猜想可能有以下几个:
固定初始噪声噪声,修改eta:
eta=0


eta=1
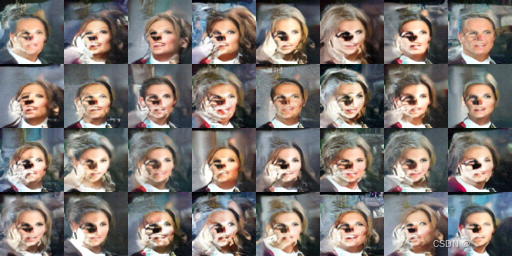

eta=3


eta=5


















 2907
2907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









