







可解释多模态融合的作用在于通过整合不同模态(如文本、图像、语音等)的互补信息,提升模型决策的透明性和可信度,使人类能够直观理解模型如何从多源数据中提取特征、关联语义并生成最终结果。
目前人工智能数据量越来越多、来源模态越发多样,可解释多模态融合在交叉领域的应用非常必要,是增强文章创新点的强大工具。
我精心整理的8篇可解释多模态融合的论文将为大家提供全面的创新思路。
对资料感兴趣的可以 [丝 xin] 我~~
一、Explainable Multimodal Emotion Recognition
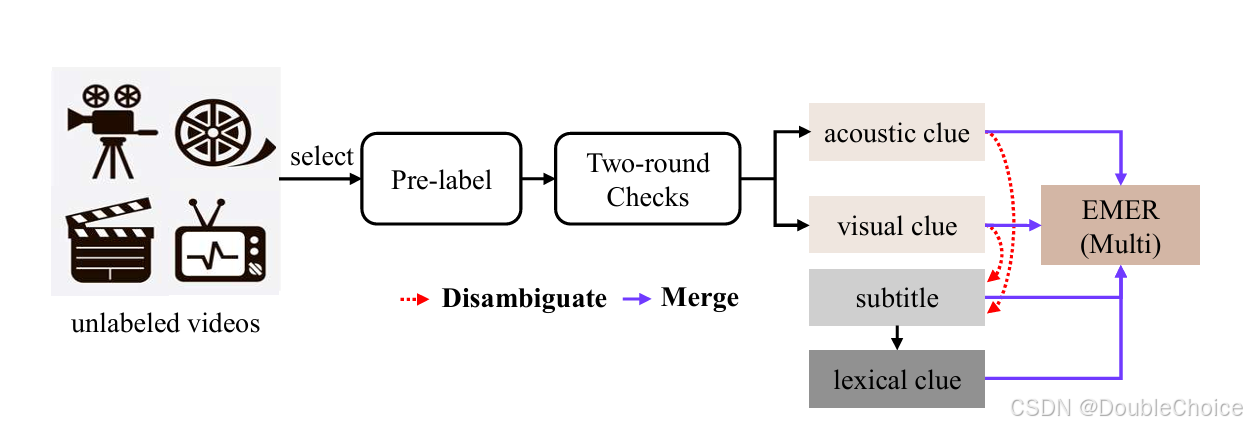
1.方法
-
任务定义与框架
提出可解释多模态情感识别任务,要求模型不仅预测情感标签,还需提供支持预测的多模态证据和推理过程,以提高标签可靠性。 -
数据集构建
-
基础数据:基于MER2023数据集。
- 多模态标注流程:
-
预标注:利用GPT-4V分析视频帧和音频转文本,生成初步描述。
-
人工校验:通过两轮人工检查修正预标注中的错误(如幻觉描述、关键线索缺失)。
-
消歧与融合:借助GPT-3.5整合视觉、声学与文本线索,生成最终的多模态描述。
-
-
开放词汇标签提取:从EMER中通过大语言模型提取开放情感标签。
-
-
基准模型与评估
-
多模态大语言模型(MLLMs):选用支持视频/音频的模型(生成EMER描述。
- 评估指标:
-
情感识别:基于标签集合的重叠率。
-
文本生成质量:BLEU、METEOR、ROUGEₗ等匹配指标。
-
消歧策略对比:分析不同字幕整合策略对性能的影响。
-
-
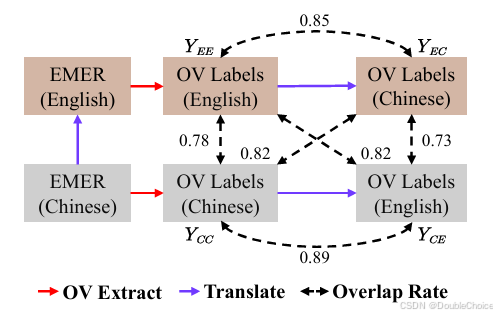
2.创新点
-
任务创新
提出可解释多模态情感识别任务(EMER),突破传统“一热编码”标签限制,通过生成解释提升标签可靠性,并支持开放词汇情感识别。 -
方法论创新
-
多模态线索融合:结合视觉、声学与文本线索,利用大语言模型实现跨模态消歧与推理。
-
低成本标注框架:通过预标注+人工校验的半自动化流程降低标注成本,同时保证数据质量。
-
-
数据集与评估创新
-
构建EMER数据集:首次提供包含多模态解释与开放标签的情感识别基准。
-
多维度评估体系:设计兼顾情感识别准确性与生成解释合理性的指标,并验证其相关性。
-
-
应用扩展
将EMER作为多模态大语言模型(MLLMs)的评测基准,推动模型在音视频文本联合理解能力上的进步。
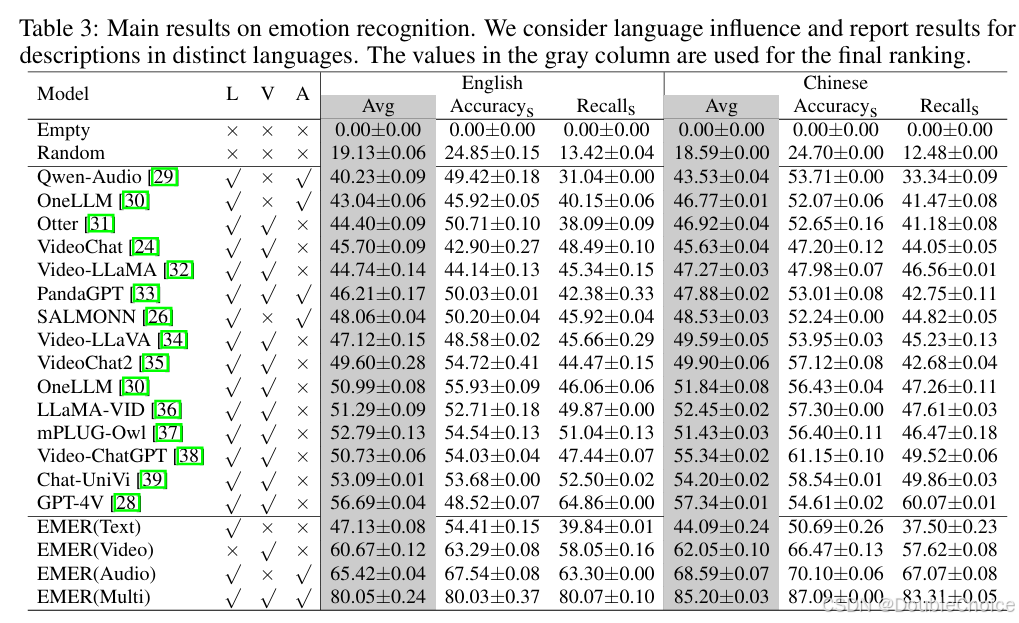
二、MusicLIME: Explainable Multimodal Music Understanding 
1.方法
-
数据预处理与特征重构
-
数据清洗:采用箱线图方法处理异常值,确保数据质量。
-
特征相关性分析:通过皮尔逊相关系数分析负荷与天气、经济等变量的关联性。
-
时间序列重构:将每个时刻的负荷数据扩展为包含历史48个采样点的56维特征向量。
-
数据标准化:使用Min-Max归一化处理多源异构数据。
-
-
模型架构设计
- ResNet特征提取:
-
采用ResNet网络。
-
残差块设计解决深度网络梯度消失问题,通过跳跃连接保留原始特征。
-
使用Batch Normalization加速训练收敛。
-
- LSTM时序建模:
-
接收ResNet输出的3D特征向量。
-
包含2层LSTM网络,通过Dropout防止过拟合。
-
- ResNet特征提取:
-
多任务预测扩展
-
天气变量预测:将模型应用于干球温度、湿度等天气变量的预测,验证模型在关联因素预测中的有效性。
-
-
实验验证
-
对比模型:与MLR、LSTM、CNN、ResNet、CNN-LSTM等模型对比。
-
评估指标:采用RMSE、MAPE、MAE、APE等指标评估预测精度。
-
计算效率分析:统计模型参数量和运行时间。

-
2.创新点
-
多模态可解释性方法:
首次提出针对音乐多模态模型的模型无关解释框架MusicLIME,解决了单模态解释方法无法捕捉跨模态交互的问题。 -
全局解释框架:
提出将局部解释聚合为全局视角的方法,帮助用户理解模型在类别级别的行为模式,弥补了传统LIME仅关注单实例的局限。 -
跨模态贡献对比:
通过特征重要性分数,量化音频和歌词在不同任务中的贡献差异,例如:-
情感识别中音频主导。
-
流派分类中歌词与音频共同作用。
-
-
数据集构建与验证:
整理并开源两个多模态音乐数据集,填补了现有公开数据在音频-歌词配对上的不足,并通过跨数据集实验验证方法的鲁棒性。 -
领域适配性优化:
针对音乐特点优化特征处理,使解释更符合音乐领域的直觉。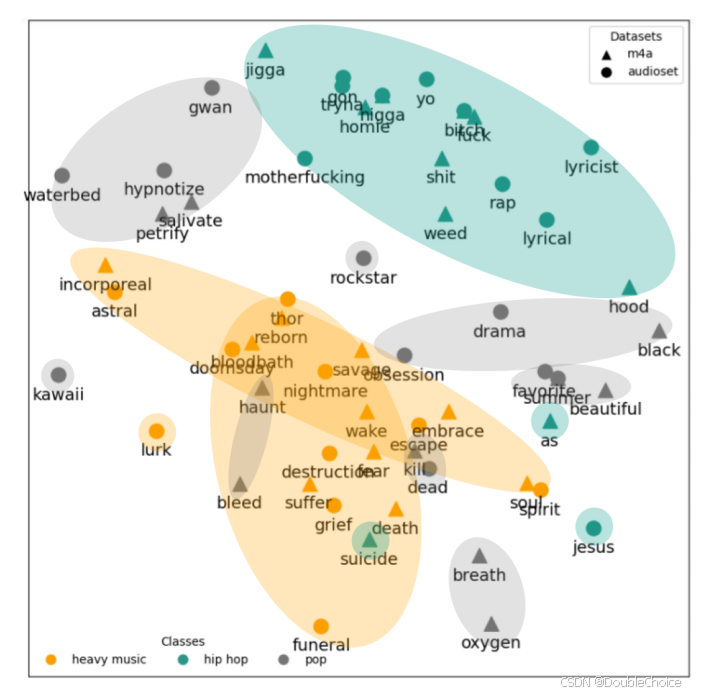

















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









