







- SVM 和 LR 的区别和联系 当面试官问LR与SVM的问题时,他们会问些什么_Matrix_cc的博客-CSDN博客
- SVM推导,及使用对偶的原因,SVM 核函数选择 SVM 高频面试题 - 知乎
- svm 对缺失数据敏感吗,为什么,决策树呢。
- 决策树是如何处理缺失数据的。决策树是如何处理不完整数据的? - 知乎
- svm 如何处理多分类
- 为什么 svm 采用最大间隔。答:鲁棒,对未知数据泛化更好
- svm 选取样本问题,如何增加样本点。
- 什么时候选择 svm 算法,什么时候选择决策树算法。答: svm 更适合处理特征多的样本。 而决策树处理特征多的样本时容易发生过拟合。
- 贝叶斯是线性分类器吗
- LR 可不可以做非线性分类,如何理解线性模型中的线性:LR本身是个线性模型,虽然加上了sigmoid函数,但是它的分类平面是线性的,可以做非线性分类,需要做一个非线性映射 逻辑斯蒂回归能否解决非线性分类问题? - 辛俊波的回答 - 知乎
- 逻辑斯特回归是分类模型,为什么叫回归:

- LR可不可以用MSE作为损失函数?为什么 不可以,原因
- LR怎么解决过拟合?1、减少特征的数量:1)手动选择需要保留的数据 2) 使用模型选择的算法 2、正规化:保留所有特征,但是减小参数θ 的大小。
- 比较 LR 和 GBDT,什么情景下 GBDT 不如 LR
- LR的特征为什么要离散化?1、计算简单 2、简化模型 3、增强模型的泛化能力,不易受噪声的影响
- 1. 比较 LR 和 GBDT:(1) LR 是一种线性模型,而 GBDT 是一种非线性的树模型,因此通常为了增强模型的非线性表达能力,使用 LR 模型之前会有非常繁重的特征工程任务;(2) LR 是单模型,而 GBDT 是集成模型,通常来说,在数据低噪的情况下,GBDT 的效果都会优于 LR;(3) LR 采用梯度下降方法进行训练,需要对特征进行归一化操作,而 GBDT 在训练的过程中基于 gini 系数选择特征,计算最优的特征值切分点,可以不用做特征归一化。
- 2.GBDT 不如 LR 的地方:
- 一方面,当需要对模型进行解释的时候,GBDT 显然会比 LR 更加 “黑盒”,因为我们不可能去解释每一棵树。相比之下。LR 的特征权重能够很直观地反映出特征对不同类样本的贡献程度,也正因为如此好理解,很多时候我们可以根据 LR 模型得到的分析结论做出更有说服力的营销和运营策略;另一方面,LR 模型的大规模并行训练已经非常成熟,模型迭代速度很快,业务人员可以很快得到模型的反馈,并对模型进行针对性的修正。而 GBDT 这样的串行集成方式让它的并行十分困难,在大数据规模下训练速度十分缓慢。
- bagging 和 boosting 的区别 答案
- 偏差小,方差大说明什么?说明是过拟合,需要降低模型复杂度。反之呢?欠拟合,需要增加模型复杂度。
- 有哪些算法需要进行归一化?机器学习算法在什么情况下需要归一化?_Running_you-CSDN博客_什么时候需要归一化
- 决策树,GBDT,随机森林的区别
- 介绍一下 xgboost,xgboost 和 GBDT 的区别,优缺点 XGBoost 原理 及 常见面试题 - 知乎机器学习算法中 GBDT 和 XGBOOST 的区别有哪些? - 知乎
- XGBoost是怎么选择最佳分裂点的?决策树和GBDT呢?1)XGBoost是使用贪心算法来分裂,两个 for 循环,第一个 for 遍历所有特征,第二个 for 找出最佳的特征值作为分裂点选分裂点的依据 score 为分裂前后损失函数的减少量,根据每次分裂后产生的增益,最终选择增益最大的那个特征的特征值作为最佳分裂点。分裂后两侧的值相加或减去分裂前的值 2)决策树是使用Gini系数来进行划分。3)GBDT是使用回归树,回归树的划分方法是对于任意划分特征 A,对应的任意划分点 s 两边划分成的数据集 D1 和 D2,求出使 D1 和 D2 各自集合的平方损失最小,同时 D1 和 D2 的平方损失之和最小所对应的特征和特征值划分点。
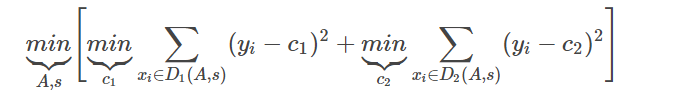
- XGBoost怎么处理缺失值?1)在某列特征上寻找分裂节点时,不会对缺失的样本进行遍历,只会对非缺失样本上的特征值进行遍历,这样减少了为稀疏离散特征寻找分裂节点的时间开销。2)另外,为了保证完备性,对于含有缺失值的样本,会分别把它分配到左叶子节点和右叶子节点,然后再选择分裂后增益最大的那个方向,作为预测时特征值缺失样本的默认分支方向。3)如果训练集中没有缺失值,但是测试集中有,那么默认将缺失值划分到右叶子节点方向。
- XGBoost怎么并行的?树的生成是并行的吗?
- Xgboost的特征重要性是怎么做的?

- GBDT为什么使用回归树,为啥不用分类树? 原因是 GBDT 每次拟合的都是梯度值(连续值),因此要使用回归树
- 如何判断分类器的好坏(分类器的评价指标)
- 介绍 Kmeans 算法,Kmeans是否收敛?为什么能收敛?K-Means 优化的目标是每个样本离其所属类中心点的距离平方和,
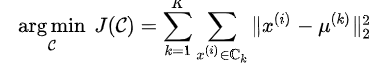 ,在每一步迭代过程中分为两个步骤:更新中心点以及更新样本的所属类。这两个步骤都会使目标函数减小。因此一定会收敛。也可以把 K-Means 看做 EM 算法的特例,EM 算法是可以保证收敛的。
,在每一步迭代过程中分为两个步骤:更新中心点以及更新样本的所属类。这两个步骤都会使目标函数减小。因此一定会收敛。也可以把 K-Means 看做 EM 算法的特例,EM 算法是可以保证收敛的。 - 样本不均衡的处理方法:权重调整,采样(过采样和欠采样),SMOTE方法(合成新的少数类样本,合成的策略是对每个少数类样本a,从它的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本,过采样:SMOTE算法_YJ语的博客-CSDN博客_smote算法),对样本不均衡不敏感的指标(F1),focal_loss: focal loss 的两个性质算是核心,其实就是用一个合适的函数去度量难分类和易分类样本对总的损失的贡献。
 增加一个调节因子降低易分类样本权重,聚焦于困难样本的训练
增加一个调节因子降低易分类样本权重,聚焦于困难样本的训练 - EM 算法
- 精确率,准确率,召回率和ROC、AUC 准确率、精确率、召回率、F1值、ROC/AUC整理笔记_学习容易上瘾-CSDN博客_准确率 召回率
- PR曲线 【机器学习】一文读懂分类算法常用评价指标 | 郭耀华's Blog
- AUC原理和计算方法 AUC的计算方法_SCUT_Sam-CSDN博客_auc计算公式
- AUC的物理意义:任取一对(正、负)样本,正样本的 score 大于负样本的 score 的概率,代码实现AUC AUC代码实现
- 贝叶斯和朴素贝叶斯的区别
- 分类树和回归树的区别
- 决策树的原理
- 什么是生产模型和判别模型
- PCA和LDA两者的区别 机器学习(十六)— LDA和PCA降维 - 深度机器学习 - 博客园
- 目标函数,损失函数,代价函数之间的区别?
- 目标函数是最终需要优化的函数,其中包括经验损失和结构损失。
- obj=loss+Ω
- 经验损失 (loss) 就是传说中的损失函数或者代价函数。结构损失 (Ω) 就是正则项之类的来控制模型复杂程度的函数。
- 什么算法需要归一化,什么不用?归一化的作用是什么?面试题总结(2)——机器学习哪些算法需要归一化_u014535528的博客-CSDN博客
- 多分类和多标签的区别,多分类和多标签的损失函数一般怎么选择?
- KL散度与交叉熵的区别 KL散度与交叉熵区别与联系_Dby_freedom的博客-CSDN博客_kl散度和交叉熵的区别
- 为什么要做特征归一化/标准化?为什么要做特征归一化/标准化? - shine-lee - 博客园


















11-14
 3708
3708
3708
03-15
1万+
1万+
06-11
4167
4167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









