






【LSTM+Transformer】作为一种混合深度学习模型,近年来在学术界和工业界都受到了极大的关注。它巧妙地融合了长短期记忆网络(LSTM)在处理时序数据方面的专长和Transformer在捕捉长距离依赖关系上的优势,从而在文本生成、机器翻译、时间序列预测等多个领域取得了突破性的进展。
这种创新的结合不仅提升了模型的预测精度,还优化了性能和训练效率,使其在序列分析任务中展现出卓越的能力。例如,最新的混合架构模型在Nature子刊上发表,以及准确率高达95.65%的BiLSTM-Transformer模型,都是这一领域的杰出代表。
为了促进大家对LSTM+Transformer技术的深入理解,并激发新的研究思路,我们精心挑选了过去两年内发表的20篇顶尖论文。这些论文涵盖了该领域的最新研究成果,包括论文全文、发表期刊以及相关代码资源,旨在为研究人员和实践者提供宝贵的参考和启发。
三篇论文详解
1、Vision Transformers and Bi-LSTM for Alzheimer's Disease Diagnosis from 3D MRI
方法
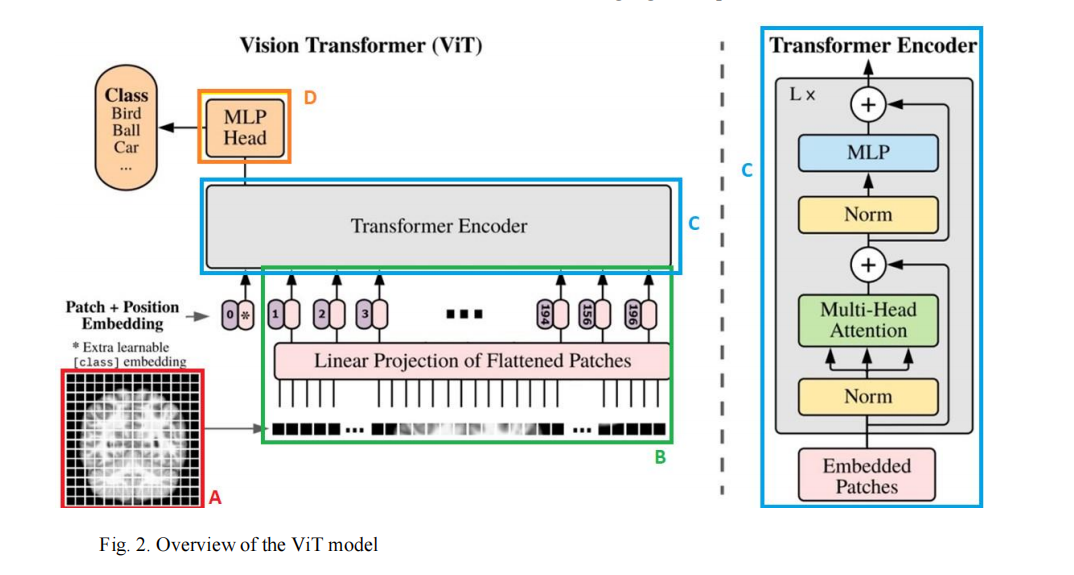
本文提出了一种结合视觉Transformer(ViT)和双向长短期记忆网络(Bi-LSTM)的方法,用于从3D MRI图像中诊断阿尔茨海默病(AD)。具体方法如下:
-
预处理:使用MATLAB的计算解剖工具箱(CAT12)和统计参数映射12工具(SPM12)进行去颅骨处理,以隔离和提取大脑区域,并进行归一化和配准处理。
-
特征提取:使用预训练的ViT模型从每个2D切片中提取特征。ViT通过将输入图像划分为一系列不重叠的固定大小的图像块,然后将这些图像块展平成一系列1D嵌入向量(称为token),再通过位置嵌入提供空间信息,并通过多个Transformer块进行特征提取。
-
Bi-LSTM序列分类:将ViT提取的MRI切片特征作为Bi-LSTM网络的输入,进行AD的二元分类。Bi-LSTM能够捕捉数据的时间依赖性和长期依赖性,通过其门控机制有效防止梯度消失,提高模型的训练效率和准确性。
创新点
-
ViT和Bi-LSTM的结合:本文首次提出将ViT用于提取3D MRI图像切片的特征,然后使用Bi-LSTM对这些特征进行序列建模和分类,这在AD的诊断中是一个新颖的方法。
-
使用预训练的ViT模型:利用在大规模数据集(如ImageNet)上预训练的ViT模型进行特征提取,这有助于在较小的数据集上实现有效的转移学习。
-
Bi-LSTM的应用:通过Bi-LSTM对ViT提取的特征序列进行建模,有效地捕捉了特征之间的时间依赖性,这对于分析大脑区域间的复杂关系尤为重要。
-
针对3D MRI的优化:尽管ViT主要针对2D图像设计,但本文通过将3D MRI数据在轴向平面上标准化并切割成2D切片,使得预训练的2D网络模型可以用于转移学习,提高了对3D MRI数据的处理能力。
-
早期诊断的潜力:该方法能够提供准确的AD早期诊断,这对于及时的治疗和管理疾病、减缓疾病进展和提高患者的生活质量至关重要。
IMG_256
2、Integrating LSTM and BERT for Long-Sequence Data Analysis in Intelligent Tutoring Systems
方法
-
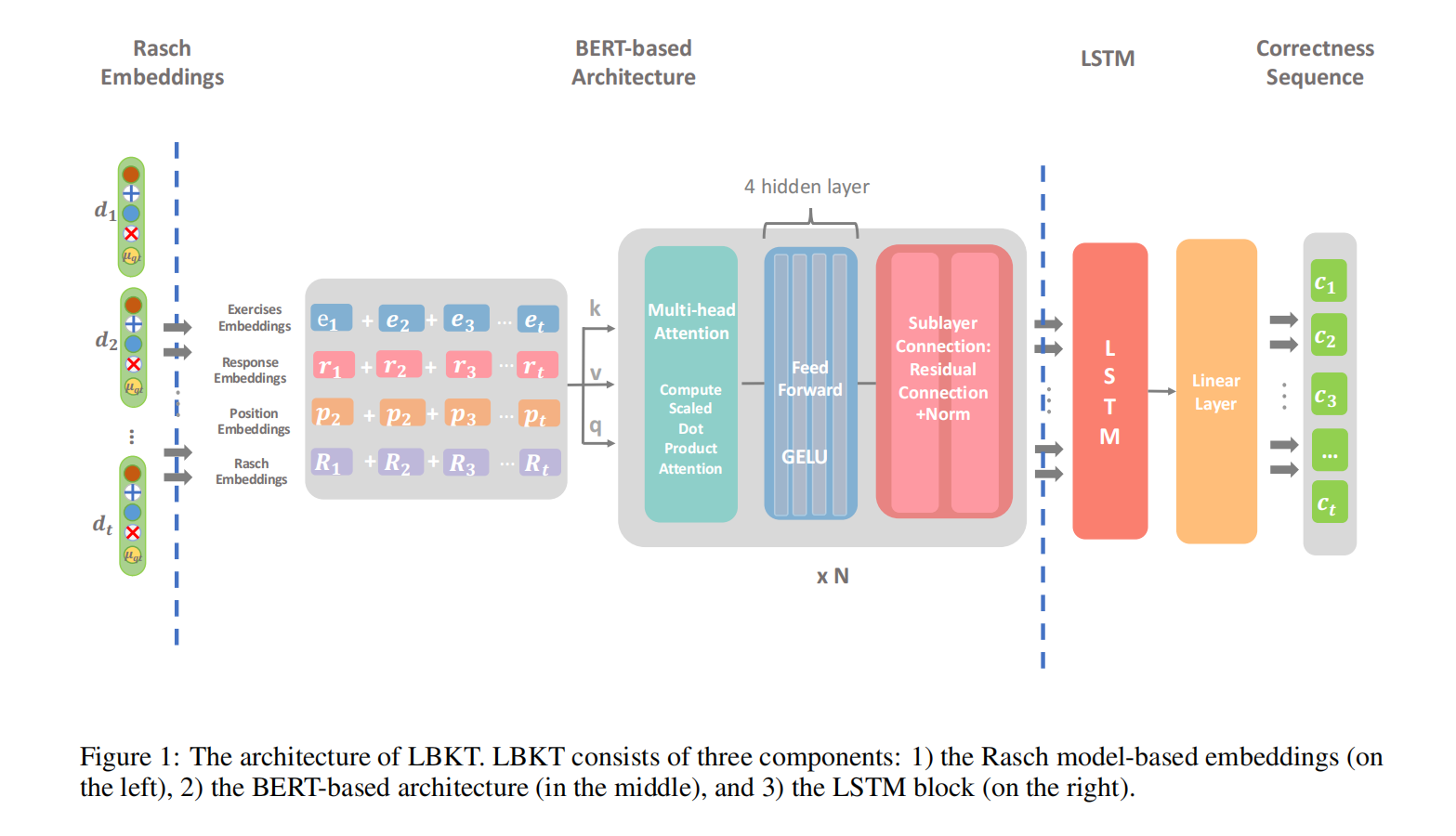
模型架构:提出了一个名为LBKT的新型知识追踪模型,该模型结合了BERT和LSTM的优势,用于处理大规模数据集中的长序列数据。
-
数据集:使用了包括assist12、assist17、algebra06、EdNet和Junyi Academy在内的五个基准数据集来验证LBKT模型的有效性。
-
评估指标:使用准确率(ACC)和曲线下面积(AUC)作为性能评估指标,并使用训练速度、速度比和内存使用情况作为处理长序列数据的性能指标。
-
基线模型:与BEKT、AKT、DKVMN、SSAKT和LTMTI等最新模型进行了比较。
-
超参数设置:为了与每个模型进行比较,使用了相同的参数设置进行模型训练,包括批量大小、训练/测试拆分、嵌入大小、优化器、学习率、损失函数、调度器、dropout率、训练周期和早期停止条件。
-
问题陈述:知识追踪的关键在于预测学生在序列中的下一个答案的正确性。
创新点
-
LBKT模型:首次提出将BERT和LSTM结合用于知识追踪模型,特别针对长序列数据处理进行了优化。
-
Rasch模型基础的嵌入:使用Rasch模型来处理学生行为数据中的不同难度级别信息,提高了模型的性能和可解释性。
-
长序列数据处理:LBKT在处理长序列数据时展现出更快的速度和更低的内存成本,比传统的基于深度学习的知识追踪方法更具优势。
-
消融研究:通过消融研究分析了LBKT各个组成部分对整体性能的影响,证明了LSTM组件在处理长序列数据时的重要性。
-
t-SNE可视化:使用t-SNE工具展示了模型的嵌入策略,证明了Rasch嵌入在处理难度级别特征方面的有效性。
IMG_256
3、XTM: A Novel Transformer and LSTM-Based Model for Detection and Localization of Formally Verified FDI Attack in Smart Grid
方法
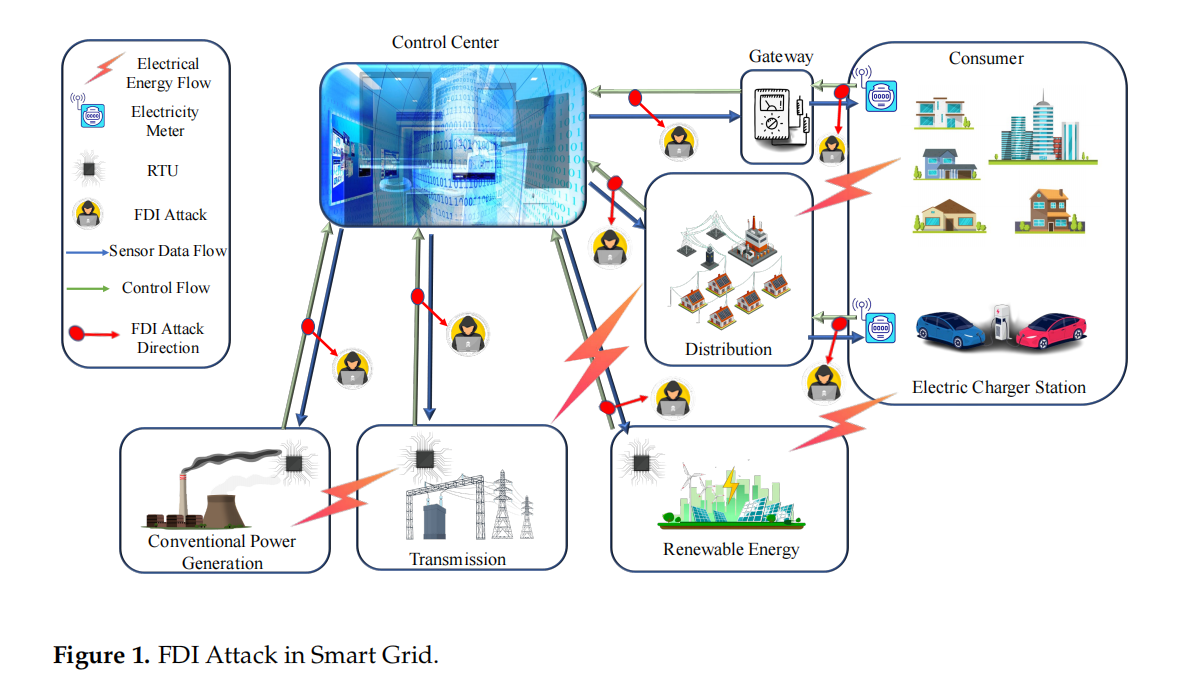
本文提出了一个名为XTM的新型混合深度学习模型,用于检测和定位智能电网中的虚假数据注入(FDI)攻击。XTM结合了变换器(Transformer)和长短期记忆网络(LSTM),以实时场景下检测数据入侵并确定其确切位置。具体方法如下:
-
预处理:使用去颅骨处理、归一化和配准来准备MRI图像数据,以消除无关信息并减少噪声。
-
FDI存在检测模块(FPDM):使用预训练的Transformer模型处理过去48小时的传感器测量数据,并通过LSTM网络预测下一小时的测量值。通过计算预测值和实际值之间的误差,使用阈值判断系统是否受到攻击。
-
位置检测模块(LDM):采用多标签分类方法,同时对每个传感器进行分类,以确定攻击的确切位置。该模块的输入包括FPDM的预测输出和实际传感器测量值。
-
评估:使用均方根误差(RMSE)、均方误差(MSE)和平均绝对误差(MAE)等指标来评估模型的预测准确性。同时,使用精确度、召回率和F1分数等分类指标来评估攻击检测的准确性。
创新点
-
提出XTM模型:首次将Transformer算法应用于智能电网FDI攻击检测领域,结合LSTM以提高检测和定位的准确性。
-
新的阈值选择方案:引入了一种新的阈值选择方法,以替代传统的坏数据检测(BDD),提高了检测FDI攻击的准确性。
-
多标签分类方法:在位置检测模块中使用多标签分类方法,可以同时对所有传感器进行分类,确定攻击的确切位置。
-
数据集和攻击向量的详细讨论:提供了详细的数据集和攻击向量构建过程,包括如何生成攻击向量以及如何使用形式化方法验证攻击向量。
-
在不同数据集上的评估:在IEEE-14母线系统上使用小时级和分钟级数据集对模型进行了训练和评估,证明了模型在不同时间粒度下的有效性和可扩展性。
-
高检测准确率:XTM模型在检测FDI攻击方面达到了几乎100%的检测准确率,并在位置检测模块中实现了非常高的行准确率(RACC)。
IMG_256

















 5886
5886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









