






Autoware 障碍物车辆意图与轨迹预测
yeye.liu@foxmail.com
Autoware 中预测道路中其他车辆的意图与轨迹部分在一篇博士毕业论文的第四章中进行了详细解释,本篇博客是对论文第四章第解释。
论文中采用的方法为用粒子滤波器进行预测。其中提到机器学习的方法需要事先知道场景情况才能进行学习并实现预测,然而不可能得知所有的驾驶场景来为机器学习算法提供训练数据,因此不采用机器学习的方法。我认为是因为粒子滤波器的方法较为成熟,并且也有效,也许相关机器学习算法当时还不够成熟,所以论文作者没有将机器学习算法应用于预测。现在,用机器学习算法来预测、决策,甚至将机器学习算法应用于整个智能驾驶过程是当下及未来的研究趋势。(仅代表个人看法,很有可能是不正确的)
有关粒子滤波器的解释,这个视频讲解的较为简单清晰:Particle Filter Explained without Equations
论文全文
论文全文(含注解)
Chapter 4 Behavior planner based intention and trajectory estimation
4.1 Introduction
4.1.1 Problem Definition
目的:预测其他车辆的可能的意图与轨迹
方法有三个:确定性模型、机器学习、概率模型
确定性模型:因为预测时模拟不确定性至关重要,所以排除确定性模型
机器学习:机器学习需要已知所有可能的驾驶场景的数据,特别是一些罕见的场景,因此也不适用
概率模型:使用粒子滤波器进行预测
4.1.2 Contributions
方案:behavior planner + multi-cue particle filter
使用一个行为规划器(behavior planner)来充当复杂的行为模型,与非参数概率滤波器(multi-cue particle filter)共同解决不确定性
图4-1列出了我们的方案较传统方法的优越性。

4.1.3 Solution Approach
此文中,用 “behavior” 来表示自车行为或其他车辆滤波(预测)前的动作,用 “intention” 来表示滤波后的(预测的)其他车辆的动作。
我们的意图与轨迹预测算法——粒子滤波器,包含一个被动模式的行为规划器 Passive Behavior Planner(与应用于自车路径规划的 behavior planner 略有不同)。图4-2为预测系统图。
 算法主要包含三个部分:轨迹提取、被动行为规划器和多线索粒子滤波器。图中,观察指的是被追踪的物体,来自第三方目标检测与追踪模块的输出;算法的输出为意图与轨迹可能性,这些输出将传入局部规划,用来规划自车轨迹。
算法主要包含三个部分:轨迹提取、被动行为规划器和多线索粒子滤波器。图中,观察指的是被追踪的物体,来自第三方目标检测与追踪模块的输出;算法的输出为意图与轨迹可能性,这些输出将传入局部规划,用来规划自车轨迹。
- 轨迹提取:从地图中提取所有可行轨迹与轨迹中内嵌的交通规则
- 被动行为规划器:粒子从行为模型中采样,也就是从 Passive Behavior Planner 中采样获得。
- 多线索粒子滤波器:利用观察对每个采样粒子进行权重计算,最后,对权重进行归一化并计算每个意图与每条轨迹的可能性。
4.2 Passive Behavior Planner
被动行为规划器模拟的是其他车辆的行为,也就是其他车辆的决策器。规划器模拟的其他车辆的动作越准确,预测结果越好。图4-3比较了自车的行为规划器与用于预测其他车辆的规划器。

自身的规划器输出的是一条发送给控制的路径,而被动规划器假设令其他车辆执行运动这一步,即其输出的直接是控制型号:速度 𝑣,,加速度 𝑎,行为 𝑏𝑒h,和预期的当下位置 𝑝𝑜𝑠𝑒。
图4-4(a)展示的是要估计的意图状态,对于图4-4(a)中指出的每一个意图,都应该在被动行为规划器中存在一个相应的建模此意图的行为,如图4-4(b)所示。

4.3 Uncertainty Modeling using Particle Filter
粒子滤波器的思想是通过一系列的加权样本
χ
𝑡
\chi_𝑡
χt近似估计在 𝑡 时刻置信状态 belief state
𝑏
𝑒
𝑙
(
𝑥
𝑡
)
𝑏𝑒𝑙(𝑥_𝑡)
bel(xt),如式4.1所示。
x
t
x_t
xt 是状态向量,
z
z
z 为观察向量,
χ
𝑡
𝑖
\chi^𝑖_𝑡
χti表示状态
x
t
x_t
xt 的第
i
i
i 个样本。式4.1用重要性采样来计算后验,因为很难从目标分布中采样,所以可以从重要性分布
q
(
x
)
q(x)
q(x) 中采样,然后根据式4.2来计算权重。

在粒子滤波器中,后验分布的采样成为粒子,在4.3中用 𝜒 表示,
M
M
M 指的是最大粒子数。每一个粒子
x
t
[
m
]
x_t^{[m]}
xt[m] 是在
t
t
t 时刻状态的具体实例。

粒子集
χ
𝑡
\chi_𝑡
χt 中的假设状态
x
t
x_t
xt 的选取需要满足与贝叶斯滤波器的后验置信
b
e
l
(
x
t
)
=
P
(
x
t
∣
z
t
,
u
t
)
bel(x_t)=P(x_t|z_t,u_t)
bel(xt)=P(xt∣zt,ut) 成比例,如式4.4所示。其中,
z
z
z 表示观察,
u
u
u 表示控制信号。

ω
t
[
m
]
\omega_t^{[m]}
ωt[m] 表示粒子的重要性系数,成为权重。粒子的权重
ω
t
[
m
]
\omega_t^{[m]}
ωt[m] 是粒子(状态)为
x
t
[
m
]
x_t^{[m]}
xt[m] 时观察为
z
t
z_t
zt 的概率,如式4.5所示。因此被加权的粒子集近似贝叶斯滤波器的后验
b
e
l
(
x
t
)
bel(x_t)
bel(xt)。

4.3.1 General Particle Filter Algorithm
一般粒子滤波器算法如算法1所示。
χ
𝑡
−
1
\chi_{𝑡-1}
χt−1 为前一次迭代(
t
−
1
t-1
t−1时刻)的粒子集,
u
t
u_t
ut 为(
t
t
t 时刻)控制信号,
z
t
z_t
zt 为(
t
t
t 时刻)观察,粒子集
χ
𝑡
−
1
\chi_{𝑡-1}
χt−1 的大小为
M
M
M,即共采样了
M
M
M 个粒子,
x
t
[
m
]
x_t^{[m]}
xt[m] 为在当前时刻
t
t
t 假设的粒子状态,由粒子集
χ
𝑡
−
1
\chi_{𝑡-1}
χt−1 中的 第
m
m
m 个粒子生成。

第1行:首先设置两个空粒子集
χ
𝑡
ˉ
\bar{\chi_𝑡}
χtˉ、
χ
t
\chi_t
χt;
第2 - 4行:对粒子集 χ 𝑡 − 1 \chi_{𝑡-1} χt−1 中的每个粒子 m m m,根据其前一时刻的状态 x t − 1 [ m ] x_{t-1}^{[m]} xt−1[m] 来采样状态 x t [ m ] x_t^{[m]} xt[m],并计算其权重 ω t [ m ] \omega_t^{[m]} ωt[m] 。第三行表示从状态转移分布 p ( x t ∣ u t , x t − 1 [ m ] ) p(x_t|u_t,x_{t-1}^{[m]}) p(xt∣ut,xt−1[m]) 采样出 x t [ m ] x_t^{[m]} xt[m],权重 ω t [ m ] \omega_t^{[m]} ωt[m] 由采样状态为 x t [ m ] x_t^{[m]} xt[m] 时观察为 z t z_t zt 的概率计算得到,权重将当前时刻 t t t 时刻的观察考虑到粒子集中去。
第7 - 10行:粒子滤波器中最重要的步骤——重采样。粒子 x t [ i ] x_t^{[i]} xt[i] 从粒子集 χ 𝑡 ˉ \bar{\chi_𝑡} χtˉ 被提取的概率与它的权重成正比,即粒子的权重越大,其被选中的概率越大。将被选中的粒子 x t [ i ] x_t^{[i]} xt[i] 加入结果粒子集 χ t \chi_t χt 中。这一步实际上实现的是把不重要的、与真实状态非常不相符的粒子排除掉,将粒子分布从之前的置信度转移至逼近目标置信度。
4.3.2 Custom Particle Filter using Passive Behavior Planner
状态空间向量
x
x
x 与观察向量
z
z
z 如表4.1、4.2所示。观察可以从第三方模块中得到,例如目标追踪与转向灯检测,表4.2列出来被用到的观察。

最主要的改进是使用确定性行为规划器(被动行为规划器)来作为状态转移分布来生成假设状态
x
t
[
m
]
x_t^{[m]}
xt[m],如公式4.6所示,代替了算法1中的第三行。假设行为规划器模仿的是一个司机在遵守交通规则的情况下所做出的驾驶行为。

多线索滤波器(multi-cue particle filter)即累积使用多个观测线索来实现准确性更高的评估器。对算法1中的第四行加以改进,综合考虑多个观察因素(由传感器传来的观察结果)来计算权重,如式4.7所示。
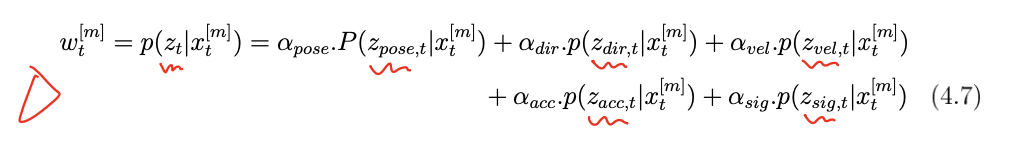
这里考虑到的观察有位置
p
o
s
e
pose
pose、方向
d
i
r
dir
dir、速度
v
e
l
vel
vel、加速度
a
c
c
acc
acc 和转向信号
s
i
g
sig
sig。重要性因子
α
\alpha
α 用来保持权重归一化:
α
p
o
s
e
+
α
d
i
r
+
α
v
e
l
+
α
a
c
c
+
α
s
i
g
=
1
\alpha_{pose} + \alpha_{dir} + \alpha_{vel} + \alpha_{acc} + \alpha_{sig} = 1
αpose+αdir+αvel+αacc+αsig=1。关于更多的权重的计算细节由4.4.3部分给出。改进的粒子滤波器算法如算法2所示。

对于被估计的每条路径和每个意图都用单独的粒子滤波器来预测。这样就可以通过减少每个粒子滤波器的维度来提高性能。从表4.1中可以看出状态的维度为8维,这需要很大数量的粒子,然而我们把这个维度降到了6维(指的是去掉了 Traj 和 Beh 这两维)。除了提高性能外,使用单独的粒子滤波器可以控制粒子的数目。在重采样过程中,排除掉没有意义的粒子会导致粒子数目减少。最少数目的粒子对于保持所有意图都在算法结果中呈现至关重要。
4.4 Estimation Algorithm
算法包括三步:轨迹提取(初始化)、粒子采样、测量更新(权重计算)
4.4.1 Trajectory Extraction (Initialization)
对于检测的车辆,提取其所有的可行路径。然后添加两条额外的路径代表其右行路径和左行路径。图4-5中,粉色框表示被检测车辆,左边显示的是路网地图的道路中心线,右边显示的是提取出来的四条路径,两条分支路径,一条是直行一条是左转。长的路径代表其全局规划路径。

当一条新的路径出现时,一系列新的粒子将会从初识先验分布中采样。

4.4.2 Particle Sampling
粒子采样过程由算法的第三行实现。行为规划器同时考虑路网地图和其他的观察到的车辆。正如式4.6所示,行为规划器通过利用地图和当前的观察来从 x t − 1 x_{t-1} xt−1 中计算得出 x t x_t xt。
例如,假设被检测的车辆处于一个路口中距离停止线10米的地方,前一个状态
x
t
−
1
m
x_{t-1}^m
xt−1m 如表4.3中的第一列所示。从被动行为规划器的角度来说,这个车应该停止。因此第
m
m
m 个粒子的状态
x
t
x_t
xt 将如表4.3的第二列所示。第三列值得是路口没有停止信号情况下的状态转换。

4.4.3 Weight Calculation
通过计算估计的分布与检测到的传感器线索的相差程度来过滤采样的粒子。如式4.8所示,每个粒子的权重根据传感器数据——位置、方向、速度、加速度和转向灯信号信息计算得到。
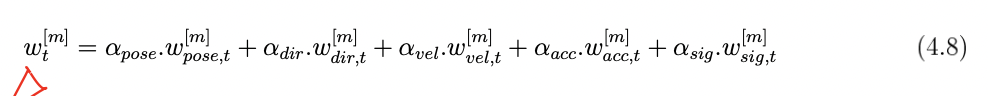
考虑传感器噪声非常重要,可以假设每个传感器的测量噪声值相同,但是这是不准确的,因为各传感器的精度不同。我们通过给每个权重乘以一个因子
α
\alpha
α 的方法来将传感器噪声的影响考虑进来。重要性因子
α
\alpha
α 必须满足条件
∑
c
u
e
α
=
1
\sum^{cue}\alpha = 1
∑cueα=1。
位置线索权重
式4.10、4.9代表分布
P
(
z
p
o
s
e
,
t
∣
x
t
[
m
]
)
P(z_{pose,t}|x_t^{[m]})
P(zpose,t∣xt[m]),
ω
p
o
s
e
,
t
m
\omega_{pose,t}^{m}
ωpose,tm 表示观察到的位置
z
p
o
s
e
z_{pose}
zpose 粒子位置
x
p
o
s
e
,
t
[
m
]
x_{pose,t}^{[m]}
xpose,t[m] 的距离差。

方向线索权重
式4.11代表分布
P
(
z
d
i
r
,
t
∣
x
t
[
m
]
)
P(z_{dir,t}|x_t^{[m]})
P(zdir,t∣xt[m]),方向权重
ω
d
i
r
,
t
m
\omega_{dir,t}^{m}
ωdir,tm 由观察到的
z
θ
z_\theta
zθ 与采样粒子的方向
x
p
o
s
e
,
t
[
m
]
x_{pose,t}^{[m]}
xpose,t[m] 的差计算得到。式4.11、4.12 包含了车辆的朝向语义。
 速度线索权重
速度线索权重
式4.13代表分布
P
(
z
v
e
l
,
t
∣
x
t
[
m
]
)
P(z_{vel,t}|x_t^{[m]})
P(zvel,t∣xt[m]),速度权重
ω
v
e
l
,
t
m
\omega_{vel,t}^{m}
ωvel,tm 由根据目标追踪器观察到的
z
v
e
l
z_{vel}
zvel 与用被动行为规划器采样的速度
x
v
e
l
,
t
[
m
]
x_{vel,t}^{[m]}
xvel,t[m] 的差计算得到。

加速度线索权重
式4.14代表分布
P
(
z
a
c
c
,
t
∣
x
t
[
m
]
)
P(z_{acc,t}|x_t^{[m]})
P(zacc,t∣xt[m]),速度权重
ω
a
c
c
,
t
m
\omega_{acc,t}^{m}
ωacc,tm 由根据目标追踪器观察到的
z
a
c
c
z_{acc}
zacc 与用被动行为规划器采样的速度
x
a
c
c
,
t
[
m
]
x_{acc,t}^{[m]}
xacc,t[m] 的差计算得到。

转向信号线索权重
式4.15、4.16代表分布
P
(
z
s
i
g
,
t
∣
x
t
[
m
]
)
P(z_{sig,t}|x_t^{[m]})
P(zsig,t∣xt[m]),速度权重
ω
s
i
g
,
t
m
\omega_{sig,t}^{m}
ωsig,tm 由观察到的
z
s
i
g
z_{sig}
zsig 与采样的速度
x
s
i
g
,
t
[
m
]
x_{sig,t}^{[m]}
xsig,t[m] 的差计算得到。如果两个值相匹配,我们将权重设为0.9,我们假设转向灯检测有0.1的噪声。

权重之所以这样计算的考虑因素
选择以上权重计算方法是因为此方法计算效率最高且计算结果具有可解释性。理论上式4.8应该计算所有传感器信息的联合概率,但是计算联合概率的方法存在两个问题。一个问题是很多采样粒子不在当前状态附近,因此导致有效粒子少,从而需要使用很大数量的粒子;另一个问题是当一个传感器线索的重要性因子 α \alpha α 很小时,其他传感器线索权重的贡献度也会很小。为了解决这两个问题,我们假设所有的传感器线索都是独立的,因此使用权重的集合而不是联合概率(即相加而不是相乘?)。
计算完权重之后,我们对粒子进行归一化,因此 ∑ m ω t [ m ] = 1 \sum_m\omega_t^{[m]} = 1 ∑mωt[m]=1,权重较小的权重会被排除并由新的采样代替,新的采样粒子是由拥有大权重(置信度高)的粒子得到的。
4.4.4 Importance factor setup
初始时因子 α \alpha α 取相同的值 α = 0.2 \alpha = 0.2 α=0.2,这满足 ∑ c u e α = 1 \sum^{cue}\alpha = 1 ∑cueα=1。但是这些重要性因子应该被更有效地利用。传感器和感知模块通常通过计算方差或噪声概率来表示其数据可靠性。这些方差可以被映射到重要性因子上,当某个感知测量不够可靠时,应该减小其重要性因子,因此其对总权重的贡献就会减小。在我们的实验中,我们手动调整重要性因子的值,来达到使某项感知测量失效的目的。例如,为了比较是否使用转向灯信息所带来的结果的不同,我们可以设置 α s i g = 0 \alpha_sig=0 αsig=0,其他重要性因子 α p o s e = α d i r = α v e l = α a c c = 0.25 \alpha_{pose} = \alpha_{dir} = \alpha_{vel} = \alpha_{acc} = 0.25 αpose=αdir=αvel=αacc=0.25。
4.5 Evaluation Results
测试场景:三岔路口、四岔路口、路口(有停止标记+无停止标记)、公交站台
将预测系统的预测结果与车辆的实际行为做对比来检测系统的性能。
用两个值来辨别意图和轨迹。一个是平均权重,即所有粒子的归一化权重的平均值,这个平均值在重采样后计算得到;另一个是概率,即剩余粒子数(去掉权重小的粒子后)与总粒子数的比值,这个值在重采样前计算得到。
在粒子滤波器重采样时,弱粒子会被新的粒子取代,这些新的粒子是由围绕前一步最好的状态的正态分布中取得的。有时当新粒子生成时,权重会达到峰值。经过几次迭代后便会恢复整体趋势。增加粒子数会最小化这样的峰值状况,但是会影响预测系统的效果。在实验中我们控制这些变化(峰值)不足以大到影响预估过程。
表4.4列出了本部分讨论到所有实验。

实验案例解释:车辆本身规划出来一条路径,且跟随这条规划路径行驶,即车辆的实际行驶路径(如车辆的行驶路径为 L)。本文的预测系统对车辆每一步的行驶意图做预测,与实际行驶轨迹做比较则可以判断出预测系统的性能。至于轨迹预测,指的是假如预测系统对每一步的行驶意图预测正确,那么与此同时,也能体现出预测系统对于车辆在面临多条可行路径的情况下,对其实际要沿着哪条轨迹行驶的判断是正确的。
4.5.1 Three-way Intersection
如图4-7所示,车辆有两条可行路径。这里假设交通灯为绿灯,且转向灯感知信息不可得(不开感知中检测转向灯部分)。

图4-8展示了车辆规划器生成的行为的速度和状态转移信息。目标意图可从速度图中看出。

对于路径 L,图4-9展示了对应每个意图(Forward, Stop, and Yield)的粒子的平均权重。图4-10展示了最有可能被选择的意图。对于路径 F,相关的意图权重有图4-11所示。



4.5.2 Four-way Intersection
实验场景如图4-12所示。

在实验中,可以使能或失能转向灯信号这一感知线索,同样也可以使能或失能停止这一信息(1.车辆在停止线停止,2.车辆在停止线行驶)。对实验结果的分析体现了使用更多的感知信息对实验结果准确性的影响。
Goal F: No Stoping, turn signal sensing on
图4-13展示了用于估计图4-14中车辆意图的平均权重。开始时,各意图的权重类似,所以选择某一意图的置信度很低,但是之后就可以清晰地看出只有一个可能的意图,尽管其他意图也有很小的可能性。图4-13可以很明显地表明预测的意图与车辆真实的行为在绝大多数情况下都高度匹配,特别是在路口区域。在这个实验中,路径F的预测可能性最大,正如图4-15所示,预测的车辆沿着路径 F 行驶的可能性为0.8。



Goal F: No Stoping, turn signal sensing off
图4-16、图4-17显示的结果与上一实验相同,表明在这个场景下,转向灯信号对最终估计结果的影响不大。然而,对比图4-13与图4-16,可以看出有转向灯信息的时候意图的权重略高。同样的结论也可以通过对比图4-15与图4-18得到。



Goal F: Stopping, turn signal sensing on/off
图4-19展示了没有转向灯信息时的权重和意图,图4-20展示了有转向灯信息时的权重和意图。我们可以从结果中看出使用转向灯信号是怎样影响结果的。


当车辆在停止线停止的时候,我们失去了判断行驶路径的速度信息,因此对于粒子滤波器来说,没有足够的证据来推断车辆要沿着哪条路径行驶,尤其是当不考虑转向灯信号时。由图4-21可以看出,当车辆在停止线停车时,算法被迷惑住,不能预测出正确的路径,但是一旦车辆继续行驶,算法就能准确预测。利用转向灯信息,这个问题就可以被解决。如图4-22所示,当有了转向灯信息,算法在这种情况下就能对正确的路径给出高置信度。


当车辆的驾驶司机忘记开转向灯或者临时改主意时,尽管算法正确地选择了路径 F,路径 L 和路径 R 仍然由同样高的可能性。
Goal L
图4-23也比较出了使用转向灯信号对算法更早地预测出轨迹的影响。在没有转向灯信号的情况下,一旦车辆开始在路口转向,算法依旧能正确地估计车辆的行驶轨迹(在1秒到2秒的时间内)。

Goal R
我们可以获得连贯的预测结果,但是在没有转向灯信息且车辆在停止线停止的情况下,算法不能准确预测车辆的意图。事实上,即使是人来判断,也无法给出正确的结果。
Bus Stop and Parking Scenario
场景如图4-24所示。

在这种场景下,我们加入来一个新的意图——停车(Parking)。实验结果如图4-25所示。

Overtaking Scenario
在对停止对公交车进行超车的情景下,自车需要判断相邻车道的那辆车会不会让道。如果判断其让道意图的置信度很高时,自车便可以安全地换道。图4-26展示了对邻车的意图估计。结果表明邻车打算让车,使自车超过公交车。在这种情况下,自车的规划器就会决定一条安全的换道路径。

Conclusion and Summary
本算法的目的是给出道路中其他车辆每个意图和路径的可能性。我们的方法首先对每一个意图和路径都使用一个粒子滤波器;然后使用一个决定性行为规划器提供每个粒子的预期运动模型;之后利用多个感知输入,如位置、速度、加速度和转向灯信号,通过比较预期状态和实际的感知信息来计算粒子权重。结果表明,我们的算法能够在复杂场景下准确地预测车辆意图和轨迹。















 818
818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









