








【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
虽然循环神经网络的从零开始实现对了解循环神经网络的实现方式具有指导意义,但并不方便。本节将展示如何使用深度学习框架的高级API提供的函数更有效地实现相同的语言模型。我们仍然从读取时光机器数据集开始。
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
一、定义模型
高级API提供了循环神经网络的实现。我们构造一个具有256个隐藏单元的单隐藏层的循环神经网络层rnn_layer。事实上,我们还没有讨论多层循环神经网络的意义(这将在深度循环神经网络中介绍)。现在仅需要将多层理解为一层循环神经网络的输出被用作下一层循环神经网络的输入就足够了。
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens)
我们使用张量来初始化隐状态,它的形状是(隐藏层数,批量大小,隐藏单元数)。
state = torch.zeros((1, batch_size, num_hiddens))
state.shape
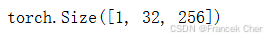
通过一个隐状态和一个输入,我们就可以用更新后的隐状态计算输出。需要强调的是,rnn_layer的“输出”(Y)不涉及输出层的计算:它是指每个时间步的隐状态,这些隐状态可以用作后续输出层的输入。
X = torch.rand(size=(num_steps, batch_size, len(vocab)))
Y, state_new = rnn_layer(X, state)
Y.shape, state_new.shape
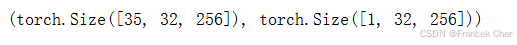
与循环神经网络的从零开始实现类似,我们为一个完整的循环神经网络模型定义了一个RNNModel类。注意,rnn_layer只包含隐藏的循环层,我们还需要创建一个单独的输出层。
#@save
class RNNModel(nn.Module):
"""循环神经网络模型"""
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32)
Y, state = self.rnn(X, state)
# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
# 它的输出形状是(时间步数*批量大小,词表大小)。
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output, state
def begin_state(self, device, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
# nn.GRU以张量作为隐状态
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device)
else:
# nn.LSTM以元组作为隐状态
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device),
torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device))
二、训练与预测
在训练模型之前,让我们基于一个具有随机权重的模型进行预测。
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
d2l.predict_ch8('time traveller', 10, net, vocab, device)

很明显,这种模型根本不能输出好的结果。接下来,我们使用循环神经网络的从零开始实现中定义的超参数调用train_ch8,并且使用高级API训练模型。
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)
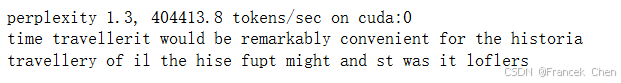
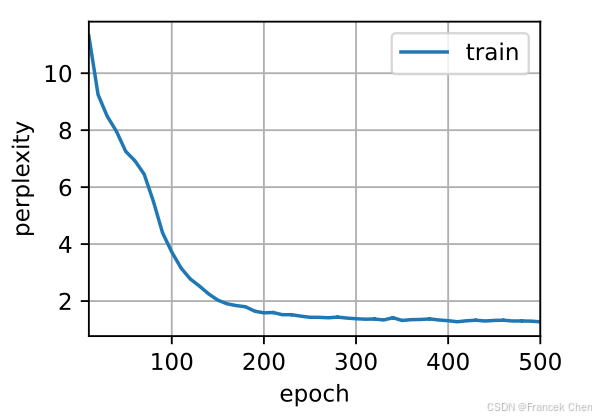
与上一节相比,由于深度学习框架的高级API对代码进行了更多的优化,该模型在较短的时间内达到了较低的困惑度。
小结
- 深度学习框架的高级API提供了循环神经网络层的实现。
- 高级API的循环神经网络层返回一个输出和一个更新后的隐状态,我们还需要计算整个模型的输出层。
- 相比从零开始实现的循环神经网络,使用高级API实现可以加速训练。


















 1168
1168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











