







博客内容将首发在微信公众号"跟我一起读论文啦啦",上面会定期分享机器学习、深度学习、数据挖掘、自然语言处理等高质量论文,欢迎关注!

从本篇文章开始,将开启spark学习和总结之旅,专门针对如何提高spark性能进行总结,力图总结出一些干货。
无论你是从事算法工程师,还是数据分析又或是其他与数据相关工作,利用spark进行海量数据处理和建模都是非常重要和必须掌握的一门技术,我感觉编写spark代码是比较简单的,特别是利用Spark SQL下的DataFrame接口进行数据处理,只要有python基础都是非常容易入门的,但是在性能调优上,许多人都是一知半解,写的spark程序经常陷入OOM或卡死状态。这时深入了解spark原理就显得非常有必要了。
本系列总结主要针对Hadoop YARN模式。
RDD(Resilient Distributed Datasets)
RDD是spark中最基本的数据抽象,存储在exector或node中,它代表一个 “惰性,”“静态”,“不可变”,“分布式“的数据集合,RDD基本介绍在网上上太多了,这里就不做详细介绍了,主要讲下以下内容:
transform(转换)与action(执行)的区别
转换操作:返回的是一个新的RDD,常见的如:map、filter、flatMap、groupByKey等等
执行操作:返回的是一个结果,一个数值或者是写入操作等,如reduce、collect、count、first等等
惰性计算
spark中计算RDD是惰性的,也即RDD真正被计算(执行操作,例如写入存储操作、collect操作等)时,其转换操作才会真正被执行。

spark为什么采用惰性计算:
在MapReduce中,大量的开发人员浪费在最小化MapReduce通过次数上。通过将操作合并在一起来实现。在Spark中,我们不创建单个执行图,而是将许多简单的操作结合在一起。因此,它造成了Hadoop MapReduce与Apache Spark之间的差异。
惰性设计的好处:
① 提高可管理性
可以查看整个DAG(将对数据执行的所有转换的图形),并且可以使用该信息来优化计算。
② 降低时间复杂度和加快计算速度
只运算真正要计算的转换操作,并且可以根据DAG图,合并不需要与drive通信的操作(连续的依赖转换),例如在一个RDD上同时调用map和filter转换操作,spark可以将map和filter指令发送到每个executor上,spark程序在真正执行map和filter时,只需访问一次record,而不是发送两组指令并两次访问分区。理论上相对于非惰性,将时间复杂度降低了一半。
例如:
val list1 = list.map(i -> i * 3) // Transformation1
val list2 = list1.map(i -> i + 3) // Transformation1
val list3 = list1.map(i -> i / 3) // Transformation1
list3.collect() // ACTION
假设原始列表(list) 很大,其中包含数百万个元素。如果没有懒惰的评估,我们将完成三遍如此庞大的计算。如果我们假设一次这样的列表迭代需要10秒,那么整个评估就需要30秒。并且每个RDD都会缓存下来,浪费内存。
使用惰性评估,Spark可以将这三个转换像这样合并到一个转换中,如下:
val list3 = list.map(i -> i + 1)
它将只执行一次该操作。只需一次迭代即可完成,这意味着只需要10秒的时间。
试想下,如果采用的是非惰性的设计,那么无法在真正运行之前生成DAG图,那么就是“看一步代码,执行一步代码”,对于不需要与drive通信的转换操作,需要每步都要访问所有分区,十分耗时。那么如果采用了惰性设计,在运行之前会生成DAG图,可以合并不需要与drive通信的操作(连续的依赖转换),只需要访问所有分区一次即可。相当于站在全局的角度进行了优化。
容错性
RDD本身包含其复制所需的所有依赖信息,一旦该RDD中某个分区丢失了,该RDD有足够需要重新计算的信息,可以去并行的,很快的重新计算丢失的分区。
运行在内存
在spark application的生命周期中,RDD始终常驻内存(在所在的节点内存),这也是其比MapReduce更快的重要原因。
spark中提供了三种内存管理机制:
① in-memory as deserialized data
这种常驻内存方式速度快(因为去掉了序列化时间),但是内存利用效率低。
② in-memory as serialized data
该方法内存利用效率高,但是速度慢
③ 直接存在disk上
对于那些较大容量的RDD,没办法直接存在内存中,需要写入到DISK上。该方法仅适用于大容量RDD。
要持久化一个RDD,只要调用其cache()或者persist()方法即可。在该RDD第一次被计算出来时,就会直接缓存在每个节点中。而且Spark的持久化机制还是自动容错的,如果持久化的RDD的任何partition丢失了,那么Spark会自动通过其源RDD,使用transformation操作重新计算该partition。
cache()和persist()的区别在于,cache()是persist()的一种简化方式,cache()的底层就是调用的persist()的无参版本,同时就是调用persist(MEMORY_ONLY),将数据持久化到内存中。如果需要从内存中清楚缓存,那么可以使用unpersist()方法。
我们来仔细分析下持久化和非持久化的区别:
非持久化:
持久化:

显然对于要复用多次的RDD,要将其进行持久化操作,此时Spark就会根据你的持久化策略,将RDD中的数据保存到内存或者磁盘中。以后每次对这个RDD进行算子操作时,都会直接从内存或磁盘中提取持久化的RDD数据,然后执行算子,而不会从源头处重新计算一遍这个RDD,再执行算子操作。 所以在写spark代码时:尽可能复用同一个RDD。
这里常有个误区:
val rdd1 = ... // 读取hdfs数据,加载成RDD
rdd1.cache // 持久化操作
val rdd2 = rdd1.map(...)
val rdd3 = rdd1.filter(...)
rdd1.unpersist // 释放缓存
rdd2.take(10).foreach(println)
rdd3.take(10).foreach(println)
如果按上述代码进行持久化,则效果就如同没有持久化一样。原因就在于spark的lazy计算。
代码应该如下:
val rdd1 = ... // 读取hdfs数据,加载成RDD
rdd1.cache
val rdd2 = rdd1.map(...)
val rdd3 = rdd1.filter(...)
rdd2.take(10).foreach(println)
rdd3.take(10).foreach(println)
rdd1.unpersist
rdd2执行take时,会先缓存rdd1,接下来直接rdd3执行take时,直接利用缓存的rdd1,最后,释放掉rdd1。所以在何处释放RDD也是非常需要细心的。 请在action之后unpersisit!!!
Spark Job Scheduling
窄依赖 与 宽依赖
shuffle过程,简单来说,就是将分布在集群中多个节点上的同一个key,拉取到同一个节点上,进行聚合或join等操作。比如reduceByKey、join等算子,都会触发shuffle操作。shuffle操作需要将数据进行重新聚合和划分,然后分配到集群的各个节点上进行下一个stage操作,这里会涉及集群不同节点间的大量数据交换。由于不同节点间的数据通过网络进行传输时需要先将数据写入磁盘,因此集群中每个节点均有大量的文件读写操作,从而导致shuffle操作十分耗时(相对于map操作)。
窄依赖:父RDD 与 子RDD的分区是一对一(map操作)或多对一(coalesce)的,不会有shuffle过程;并且子RDD的分区结果与其key和value值无关,每个分区与其他分区亦无关。
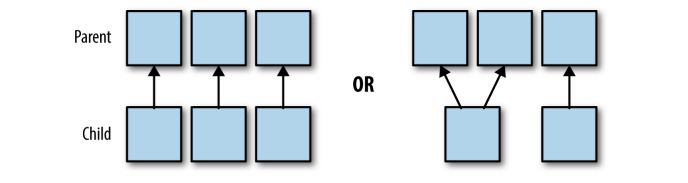
上面左图可对应map操作分区,右图对应coalesce操作。
宽依赖:父RDD与子RDD的分区是一对多的关系,并且是按一定方式进行重分区,会有shuffle过程产生,比较耗时,可能会引发spark性能问题。常见的宽依赖操作如:groupByKey、reduceByKey、sort、sortByKey等等。

注意:coalesce操作如果是将10个分区换成100个分区,由少分区转成大分区将会发生shuffle过程。coalesce操作场景主要是rdd经过多层过滤后的小文件合并。rdd的reparation方法与coalesce相反,主要是为了 处理数据倾斜,增加partiton的数量使得每个task处理的数据量减少,肯定会有shuffle过程产生(repartition其实调用的就是coalesce,只不过shuffle = true (coalesce中shuffle: Boolean = false))。
Spark Application
一个spark应用主要由一系列的spark Job组成,而这些spark Job由sparkContext定义而来。当SparkContent启动时,一个driver和一系列的executor会在集群的工作节点上启动。每个executor都有个JVM虚拟环境,一个executor不能跨越多个节点。

上图表示在一个分布式系统上启动一个spark application的物理硬件层面流程。
- 启动一个SparkContext
- 驱动程序(driver program)会定义一个集群管理(cluster manager)
- cluster manager会在工作节点上启动一些executor,运行提交的代码(注意:一个节点node上会有多个executor,但是一个executor不能跨越多个node)
需要注意以下两点:
- 一个节点node上会有多个executor,但是一个executor不能跨越多个node
- 每个executor会有多个分区,但是一个分区不能跨越多个executor
DAG(Directed Acyclic Graph)详解
spark Application tree

简而言之:一个spark Application由多个Job组成,Job由提交代码中的Action操作定义,而一个Action操作由多个Stage组成,Stage的分割由宽依赖进行分割的,而每个Stage又由多个Task组成。一个Task对应一个分区,一个task会被分配到一个executor上执行。
每个Job都对应一个DAG图,每个DAG有一系列的Stage组成。
- Job:每个Job对应一个Action操作,在spark execution Graph中,其边是基于代码中的transform操作的依赖关系定义的。
- Stages:每个Action中可能包含一个或多个transform操作,其中宽依赖又将Job划分成多个Stage。因为Stages的边缘需要和driver进行通信,故通常一个Job里,必须顺序的执行Stages而非并行。 并且会将多个窄依赖步骤合并成一个步骤,因为其中没有的转换操作没有shuffle过程,可以通过只访问一次数据,连续执行多个transform操作,这也是上面提到的惰性计算的优点。
def simpleSparkProgram(rdd : RDD[Double]): Long ={
//stage1
rdd.filter(_< 1000.0)
.map(x => (x, x) )
//stage2
.groupByKey()
.map{ case(value, groups) => (groups.sum, value)}
//stage 3
.sortByKey()
.count()
}
其代码中对应的Stage如下:

- Task:task是spark中最小最基本的执行单元,每个task代表一个局部的计算任务。在executor中可以有多个core,而每个core可以对应一个task,每个task针对一个分区。 每次针对不同的一块分区,执行相同的代码。
注意:
- spark中同时并行的task数量不能超过所有executor core数量。 其中 所有executor cores 数量= 每个executor中core数量 * executor数量。
- task的并行化是有executor数量 × core数量决定的。task过多,并行化过小,就会浪费时间;反之就会浪费资源。所以设置参数是一个需要权衡的过程,原则就是在已有的资源情况下,充分利用内存和并行化。
总结
对于DAG的深刻理解非常重要,如果理解不深刻则可能定位问题的效率不高。比如常见的数据倾斜。当理解了这些,如果出现了数据倾斜,可以分析job,stage和task,找到部分task输入的严重不平衡,最终定位是数据问题或计算逻辑问题。
参考
- High Performance Spark
- https://www.quora.com/What-is-the-reason-behind-keeping-lazy-evaluation-in-Apache-Spark
- https://data-flair.training/blogs/apache-spark-lazy-evaluation/
- http://bourneli.github.io/scala/spark/2016/06/17/spark-unpersist-after-action.html















 3513
3513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









