







转自:http://deeplearning4j.org/zh-eigenvector
1. 简介
本页主要以通俗语言和少量数学公式介绍本征向量及其与矩阵之间的关系,并且在此基础上解释协方差、主成分分析和信息熵。
本征向量(eigenvector)一词中的“本征(eigen)”来自德语,原意为a?自己的a。例如,在德语中,a?mein eigenes Autoa的意思是?a?我自己的车a。所以“本征”表示了两件事物之间的一种特殊关系。这是一种特定、独特而明确的关系:这辆车或这个向量是我的,而不是别人的。
在线性代数中,矩阵即是矩形的数组,是用括号括起来的标量值集合,就像一张电子表格一样。所有的方形矩阵(例如2 x 2或3 x 3的矩阵)都有本征向量,而矩阵与本征向量之间的关系很特别,有点像德国人与他们的车子之间的关系。
2. 线性变换
我们先简要介绍矩阵的用途以及矩阵和其他数字的关系,随后再来定义矩阵与本征向量之间的关系。
矩阵是很有用的,因为它们可以做加法或乘法运算。如果将向量v与矩阵A相乘,得到另一向量b,则可以认为矩阵对输入向量进行了线性变换。
Av = b
这一运算将向量v映射至另一向量b。
我们举一个实际的例子来说明。(如需了解这种称为点积的矩阵乘法,请点击此处。)
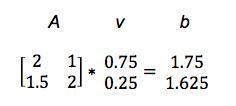
于是A将v变换为b。在下图中,可以看到矩阵将较短、较低的线段v映射为较长、较高的线段b。

你可以不断将正向量输入矩阵A,而每个向量都会被投射至一个向右上方伸展出去的新空间。
想象所有输入向量v都位于这样一个普通网格空间内:
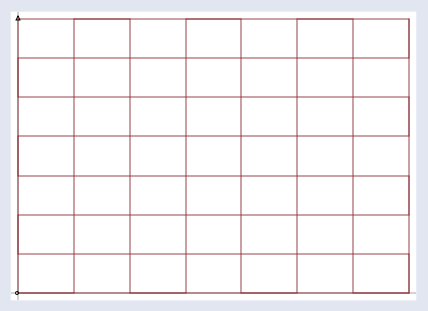
而矩阵将它们全部投射到下图所示的新空间内,所有输出向量b都位于这个空间内:
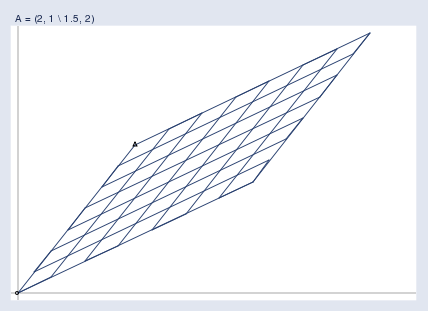
下图将这两个空间并置:
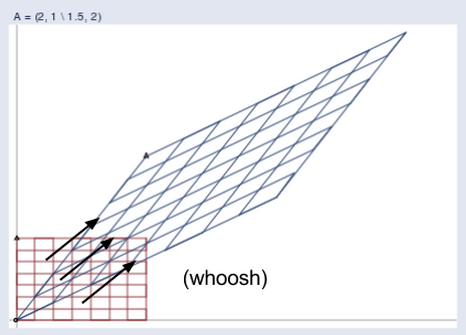
(供图:William Gould, Stata Blog)
下图则用动画说明矩阵将一个空间变换为另一个空间的作用:
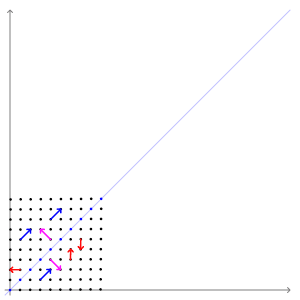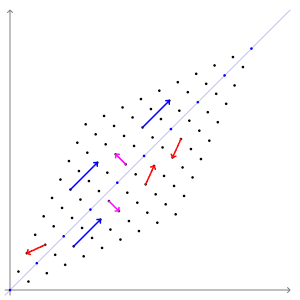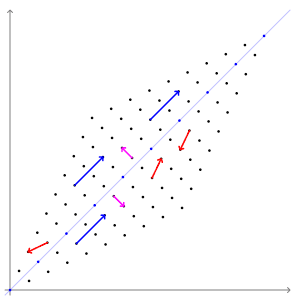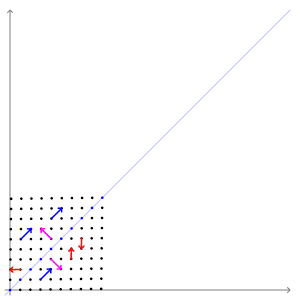
图中的蓝色线段是本征向量。
可以把矩阵想象成一阵风,这股不可见的力产生了可见的变化效果。而风必定会吹向一个特定的方向。本征向量指出了矩阵这股“风”的方向。

那么一个空间内所有受到矩阵影响的向量中,哪些才是本征向量呢?本征向量是不会改变方向的那个向量;也就是说,本征向量已经指向其它所有向量受矩阵推动而变换的方向。本征向量就像是风向标,可以叫本征向标。
因此本征向量的定义是,同矩阵相乘时仿佛只是与一个标量系数相乘的向量。在下面的等式中,A为矩阵,x为向量,λ为标量系数,比如5、37或者π。(即本征向量与矩阵相乘时,其方向不变)
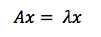
可以说本征向量是线性变换过程将输入向量拉伸或压缩时所遵循的轴线。本征向量是代表矩阵变换作用的线,也就是“线性变换”一词中所谓的“线”。
注意此处所说的轴线和线条不止一条。就好像一个德国人可能会有一辆买菜用的大众车,一辆出差用的奔驰,还有一辆兜风用的保时捷(每辆车都有特定的用途),方形矩阵有多少个维度,就有多少个本征向量;也就是说,一个2 x 2的矩阵有两个本征向量,3 x 3的矩阵有三个,而n x n的矩阵有n个,每个本征向量都代表了一个维度内的变换作用方向。1
由于本征向量提取出了矩阵对输入向量进行变换时的轴线,所以可以用来分解矩阵;即把矩阵沿着本征向量进行对角化。因为本征向量代表了一个矩阵的特性,它们的作用与深度神经网络所采用的自动编码器相同。
引用Yoshua Bengio的话来说:
对许多数学对象而言,如果要更好地理解它们,可以进行要素分解,或者寻找一些并非由表示方式所造成的共同属性。
例如,整数可以分解为素因数。我们表示数字12的方式在十进制和二进制中并不相同,但12 = 2 ?— 2 ?— 3始终是成立的。
从这种表示方式中,我们可以总结出有用的属性,例如12不能被5整除,或12的倍数都能被3整除。
与将整数分解为素因数后可以发现其本质一样,我们也可以将矩阵分解来探究其功能属性,因为当矩阵表示为元素组合时,并不容易发现这样的属性。
最常用的一种矩阵分解称为本征分解,将矩阵分解为一组本征向量和本征值。3.主成分分析(PCA)
PCA是用于分析图像等高维度数据的模式的工具。在机器学习应用中,PCA有时被用来对输入神经网络的数据进行预处理。PCA通过将数据中心化、旋转、缩放来进行维度的优先排序(可以去除一些差异性较低的维度),改善神经网络的收敛速度以及整体结果质量。
介绍PCA之前,我们首先需要对一些基本的统计学概念进行定义,包括均值、标准差、方差和协方差,以便在下文的说明中使用。这些概念的公式彼此紧密相关。
均值就是数据集X中所有x的平均值,计算方法是将所有数据点之和除以数据点的数量n。
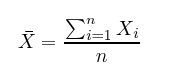
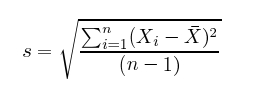
方差是衡量数据离散度的指标。以一支荷兰篮球队的球员为例,如果测量他们的身高,得到的结果不会有太大差异。所有人的身高都超过一米八。
但如果把这些荷兰篮球运动员和一个班的幼儿园学生混在一起,那么整个群体的身高数据就会出现很大的差异。方差是数据的离散度,或者说数据之间差异的大小。
方差就是标准差的平方,通常写作s^2。
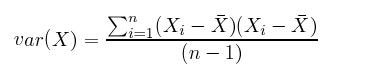
在计算方差和标准差时都会取数据点与均值之差的平方,目的是使差变为正值,避免高于平均数和低于平均数的值相互抵消。
假设以前文例子中每个人的年龄(x轴)和身高(y轴)为坐标绘图(将均值定为零),得到呈椭圆形的散点图。
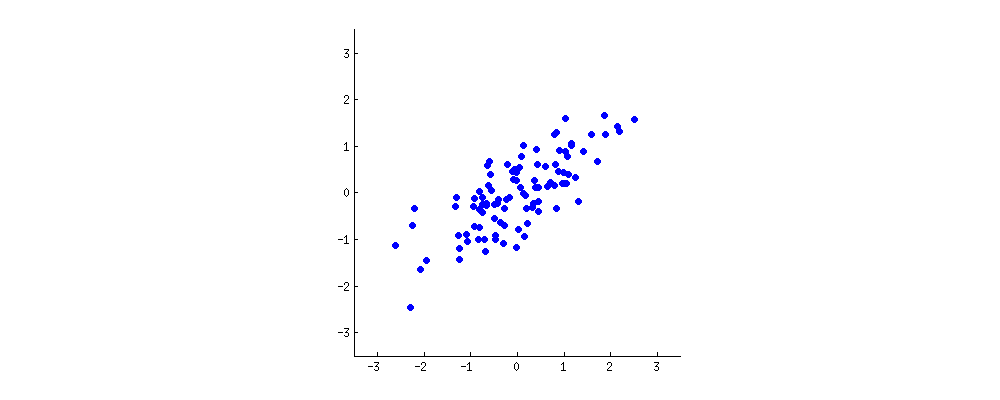
PCA就是尝试画出贯穿这些数据点的解释性直线,与线性回归类似。
每条直线代表一个“主成分”,或者说自变量与应变量之间的一种关系。主成分的数量与数据集的维度数相同,而PCA的作用是对主成分进行优先排序。
第一主成分是将散点图二等分的直线,可以解释最多的差异;也就是说,这条直线沿着数据集最长的维度伸展。(这也恰好是误差最少的一条直线,如红线所示……)在下图中,第一主成分沿“长棍面包”的长轴将其切开。
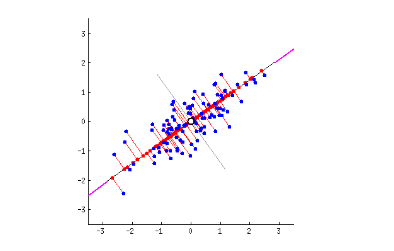
第二主成分垂直于第一主成分穿过数据集,与第一主成分产生的误差点拟合。上图中只有两个主成分,但如果有第三个维度,那么第三个主成分则会与前两个成分的误差点拟合,以此类推。
4. 协方差矩阵
上文提到,矩阵可以将一组向量变换成另一组向量,而换一种角度思考,矩阵也可以被视作描述数据所受作用力的方式,这种力也就是两个变量之间可能存在的关系,用方差和协方差来表示。
想象我们建立一个方形数字矩阵,描述数据的方差以及变量之间的协方差。这个矩阵就是协方差矩阵。它是对于我们所观察的数据的实证描述。
求取协方差矩阵的本征向量和本征值等同于将主成分直线与数据的方差进行拟合。为什么呢?因为本征向量跟踪变换作用的方向,而方差与协方差最大的轴线则能说明数据最容易发生变化的位置。
可以这样理解:变量发生变化时总是受到一股已知或未知的力的作用。如果两个变量一同变化,那么多数情况下,要么是其中一个变量对另一个发生作用,要么是两个变量都受到同一种未知作用力的影响。
矩阵用于进行线性变换时,本征向量跟踪矩阵对输入数据施加作用力的方向;而当矩阵的元素是数据的方差和协方差时,其本征向量反映了数据被施加的作用力。前一种矩阵施加作用力,后者则反映这种力。
本征值就是本征向量所附的系数,表示轴线的幅值。此处本征值是数据协方差的度量。将本征向量按本征值由高到低排列,即得到主成分重要性的顺序。
对于2 x 2的矩阵而言,协方差矩阵可能如下所示:
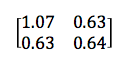
左上角和右下角的数字分别代表x与y两个变量的方差,而左下角与右上角的相同数字则代表x与y之间的协方差。由于这样的结构特点,此类矩阵被称为对称矩阵。可以看到协方差是正数,因为靠近PCA分段顶部的图像指向右上方。
协方差:只表示线性相关的方向,取值正无穷到负无穷。也就是说,协方差为正值,说明一个变量变大,另一个变量也变大;取负值说明一个变量变大另一个变量变小;取0说明两个变量没有相关性。
如果两个变量同时增减(直线指向右上方),它们的协方差为正;如果一个变量增加时,另一个变量减少,则两者间的协方差为负(直线指向右下方)。
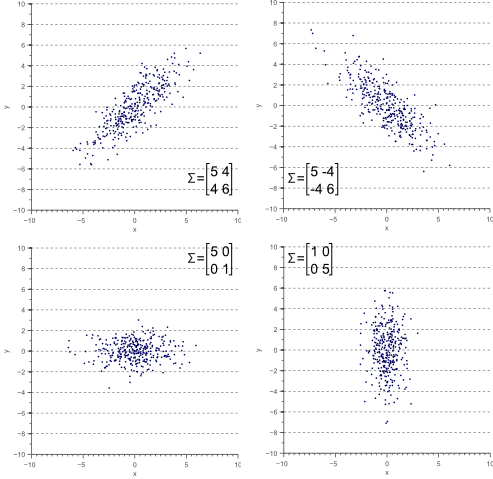
供图:Vincent Spruyt)
注意,若两个变量中有一个完全不变,且图像在对角方向上无运动,则不存在协方差。协方差回答的问题是:两个变量是否共同变化?如果一个变量变化时,另一变量维持不变,那么答案就是否定的。
此外,如下面的公式所示,协方差与方差之间的差别其实很小。
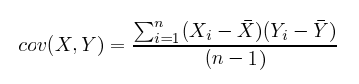
对比
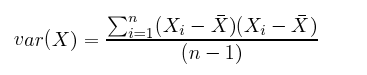
计算协方差的妙处是,对于难以从直观上判断变量关系的高维度空间,可以通过协方差的正负以及存在与否来判断两个变量之间的互动方式。(相关系数是标准化的协方差,范围在-1和1之间。)
总而言之,协方差矩阵界定了数据的形状。协方差表示对角方向上数据沿本征向量的离散程度,而x轴和y轴方向上的离散度则由方差表示。
因果性在统计学中的名声不好,所以下面这段话仅供参考:
虽然这种说法不完全准确,但可以将上文荷兰篮球队员例子中的每个要素视为一种原因因素,第一主成分是年龄,第二主成分可能是性别,第三则是国籍(包含不同国家医疗保健体系的差别),每一个成分都在各自的维度内与身高相关。每项因素对于身高有不同程度的作用。可以将协方差理解为揭示潜在原因的迹象。
5. 基变换
由于协方差矩阵的本征向量都是相互正交的,所以可以用于将原来由x轴与y轴定位的数据改为由主成分所表示的轴线定位。你可以将数据集的坐标系进行变换,变为由方差最大的轴线所界定的新空间。
上图所示的x轴与y轴称为矩阵的基;也就是说,它们为矩阵的点赋予x、y坐标。但是矩阵可以沿其他轴线重塑;例如,可以将矩阵的本征向量作为基础,赋予同个矩阵一组新坐标。矩阵和向量都是独立存在的,并不受限于x-y等坐标系的坐标数值。
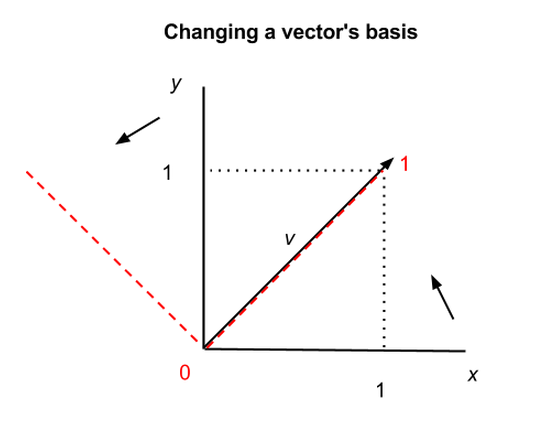
上图显示了同一个向量v在两个坐标系中的不同位置,x-y坐标系为黑色实线,新坐标系的两轴为红色虚线。在第一个坐标系中,v = (1,1),而在第二个坐标系中,v = (1,0),但v自身并未改变。向量和矩阵因而可以同括号内的数字分离开来。
这具有深远而近乎哲学性的意义,其中之一是,自然的坐标系并不存在,而n维空间中的数学对象有着多种描述方式。(基变换也可以让矩阵更容易操控。)
向量的基变换与数字的进制变换大致相似;即数量九在十进制下表示为9,而在二进制下表示为1001,在三进制下表示为100(三进制数字即1,2,10,11,12,20,21,22,100 <– 这是九)。同样的数量,不同的符号;同样的向量,不同的坐标。
6. 熵和信息增益
在信息论中,熵一词指的是我们所不知道的信息(人们通常将“信息”定义为已知的事情。这又是一个完全颠覆词语日常含义的专业词汇,非专业人士较难理解)。一个系统的熵即有关于这个系统的未知信息,它与系统的不可预测性相关,也就是说这个系统能产生多少意外性。
如果你知道一枚硬币两面都印着同样的花纹,那么抛这枚硬币就完全不能带来任何信息,因为每次得到的花纹都是一样的。不需要抛这枚硬币就能知道。我们会说两面花纹相同的硬币不包含任何信息,因为它没法让你感到意外。
而一枚两面花纹不同的硬币每次抛起时都存在意外的因素。同理,一枚有六个面的骰子每次被掷时包含更多意外的因素,可能产生六种结果中的任何一种,而每种结果出现的频率相同。这两样物体都包含技术意义上的信息。
试想如果骰子灌了铅,掷六次有五次都是“三”,那我们就会发现骰子做了手脚。骰子每次被掷所产生的意外性一下子大大减少。我们发现了骰子的动作模式,因此获得了更大的预测能力。
识别数据集的主成分可以与发现骰子是灌铅的相类比。两者的实质都是识别潜在的模式。
信息从有关系统的未知情况转变为已知情况,这代表了熵的变化。洞悉系统的模式会使系统的熵降低。获得信息,降低熵——这就是信息增益。没错,这类信息熵具有主观性,因为它取决于我们对于系统的了解程度。(顺便一提,信息增益与我们在受限玻尔兹曼机中探讨的KL散度意义相同。)
所以每个贯穿散点图的主成分都会降低系统的熵,减少系统的不可预测性。
巧合的是,从能够解释最多差异的成分开始、逐个利用主成分来解释数据形状的方法和用决策树处理数据相类似。PCA的第一主成分就像设计良好的决策树中的第一道if-then-else分割,其依据的维度可以最大程度地减少不可预测性。
7. 直接看代码
你可以在ND4J中查看我们如何使用本征向量。ND4J是用于Java虚拟机的数值运算库,可处理n维数组,很大程度上受到Numpy的启发。ND4J有Java和Scala的API,可在Hadoop或Spark上运行,超大矩阵操作的速度大约是Numpy/Cython的两倍。
8. 其他资源
- 主成分分析教程
- 本征值/本征向量有哪些重要意义?
- 理解PCA、本征向量和本征值
- 协方差矩阵的几何解释
- 本征向量和本征值介绍第一部分(视频)
- (另一篇)本征向量和本征值介绍(视频)
- 信息与熵,第一单元,第二讲(MIT OpenCourseWare)
- 价值250亿美元的本征向量:谷歌背后的线性代数
9. 其他基础教程















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









