








下方↓公众号后台回复“AFD”,即可获得论文电子资源。

文章目录
Key words
- person search
- FoveaBox detector
- on-the-fly OIM loss
- PPDMC loss
- offset guided
1. Introduction
关于行人搜索:in computer vision which matches a target person from a gallery of images.
应用场景:It is used in real world video surveillance applications, such as looking for lost people, cross-camera tracking, etc.
任务挑战性: The task is challenging due to complex variations of human poses, lighting, occlusion, resolution. (人体姿态、光照、遮挡、分辨率的复杂变化。)
研究背景:
- 传统person-re-id 分为两个子任务。先检测目标并进行裁剪,然后在做re-id。但是这个和真是的应用场景存在gap。
- 为了消灭这个gap,一些工作是这样做的:
- [3] propose the person search task that joins the task of detection with re-id by an end-to-end manner.
- focus on an end-to-end framework based on Faster R-CNN which is an anchor-based detector的不足:
- First, anchor boxes import additional hyper parameters. (首先,锚定框导入额外的超参数。
- Second, one kind of designed anchors based on a particular dataset is not always suitable to other datasets, leading to poor versatility. (第二,一种基于特定数据集设计的锚点并不总是适用于其他数据集,导致通用性差。)
- Third, a large set of anchor boxes are densely placed on the input image, resulting in a huge imbalance between positive and negative anchor boxes, and involving complicated and time- consuming computation.(第三,大量锚箱密集放置在输入图像上,导致正锚箱和负锚箱之间存在巨大的不平衡,计算复杂且耗时。)
- 因此一些工作的开始放弃 anchor boxes,比如FoveaBox [18], FCOS [15]
- 本文中是使用了 FoveaBox。
- OIM 是[3]提出的用于区别不同实体特征的方法。 由于它使用固定参数来更新查找表(LUT)中的特性,因此需要仔细设计参数。为了使其具有更强的自适应能力,我们提出了inter- section-over-union (IOU)
OIM在LUT中存储有标签身份的特征,在Queue中存储无标签身份的特征,并使用SoftMax[10]进行分类。
- OIM的不足: OIM损失只考虑标记和未标记的身份,而背景集群被忽略。因此,无法有效地识别与标记身份相似的背景聚类。
- 我们采用Siamese体系结构中的建议对,将DMC loss [7]和OIM loss联合起来监控整个网络。
- 遮挡是个人搜索中的一个主要挑战。 为了克服这一问题,在[14]中提出了一种数据增强——随机擦除(random erasing)。在训练阶段,我们将offset guided erasing代替随机擦除。
主要贡献:
- 首先,我们使用无锚定代替基于锚定的检测器。
- 其次,我们采用了Siamese体系结构中的建议对,将DMC loss与on-the-fly OIM loss联合起来,对整个网络进行监控。
- 最后,我们提出了偏移引导擦除(offset guided erasing),提高了部分遮挡样本重新识别的识别性能和鲁棒性。
2. Related work
3. The Proposed Method
person search 包含两个阶段:行人检测和re-id。如图1所示。
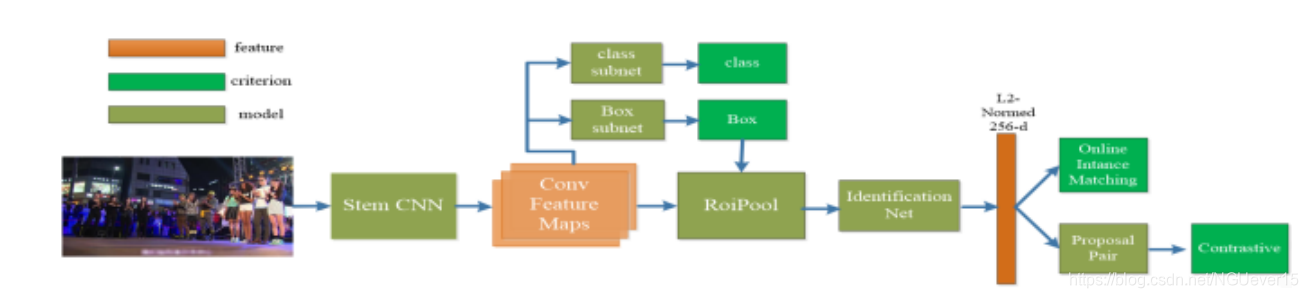
Fig. 1:Our proposed framework. .行人检测网络生成边界框,将边界框输入识别网络进行特征提取。我们将特征投影到l2 -范数256-d,并训练联合OIM和PPDMC损失。两种行人检测识别网络共享底层卷积特征映射。
我们在框架中使用无锚检测器代替传统的基于锚的检测器。我们选择以全景图像为输入的FoveaBox检测器,利用主干CNN将原始像素转换为卷积特征地图,并在这些特征映射上构建由两个任务特定子网络组成的检测网络。
我们从每像素分类和每像素包围盒预测子网中得到大量的粗盒以及置信度。只有满足一定规则的预测框才被送入识别网络。它们每个都使用RoiPooling来获得固定维度的输出(256-D)。
这个输出向量被它的l2范数标准化。在推理阶段,我们根据图库中的人与查询目标人的欧氏距离对其进行排序。在训练阶段,我们提出了用于建议对的DMC损失联合特征顶部的改进OIM损失来监督识别网。
3.1. Pedestrian Detection and Feature Learning
对FoveaBox的介绍:
which is completely anchor- free framework that does not rely on the default anchors both in training and inference phase. It is more robust and denser to predict bounding box distributions on each position and mitigate the foreground-background classification and box regression challenge contrast to anchor-based detection frame- work such as Faster-RCNN [10].
本文采用基于ResNet-50的特征金字塔网络[21]作为基础网络。
3.2. On-the-fly Online Instance Matching Loss
为了学习鲁棒性和判别性的特征,需要仔细设计损失函数。虽然Softmax loss在分类任务中得到了广泛的应用,但它有两个缺点。
- 首先,大规模的人员搜索数据集具有大量的身份,且每个身份的实例不平衡,或者每个图像只包含少数身份。
- 其次,数据集中存在一些非特定的类id和未标记的身份。利用SoftMax loss是一个棘手的问题。Xiao等[3]提出OIM损失来最小化同一人实例之间的特征差异。

Fig. 2: 左边的图像显示了标签(蓝色)和未标签(橙色)的身份建议。右边的部分显示根据id更新LUT。右下部分显示了建议的价值信息随着IOU的增加而增加。
As shown in Fig. 2, OIM maintains a LUT(
V
∈
R
D
×
L
V \in R^{D \times L}
V∈RD×L) to store the features of all the labeled identities. Denote
x
∈
R
D
x\in R^D
x∈RD as the feature of a labeled identities in mini-batch, where D is the dimension of feature and L is the number of different labeled identities. During the forward propagation, they compute cosine similarities between the mini-batch samples and the labeled identities within LUT as
V
T
x
V^T x
VTx
OIM维护一个LUT(
V
∈
R
D
×
L
V \in R^{D \times L}
V∈RD×L)来存储所有标记标识的特性。
x
∈
R
D
x\in R^D
x∈RD表示为小批标记身份的特征,其中D为特征的维数,L为不同标记身份的个数。在前向传播过程中,他们计算小批样本和LUT内标记标识之间的余弦相似度为
V
T
x
V^T x
VTx。
在后向传播的过程中,如果批样品x的类id为t,则更新LUT的第t列,
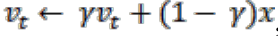
在我们的方法中,我们导入检测盒与ground-truth (gt)之间的IOU来代替恒动量
γ
\gamma
γ.
在训练阶段,由盒回归子网络分支产生的预测盒是不准确的,包含不同的目标信息。建议的有价值的信息随着IOU的增长而增加,如图右下部分所示。因此,用常量参数更新LUT 是不合理的。所提出的技术阐述如下。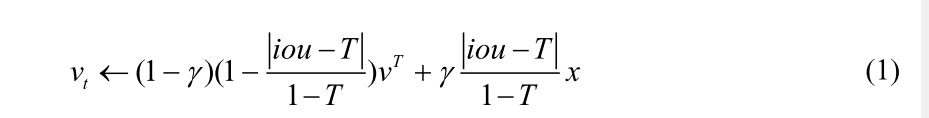
其中T为训练阶段IOU的阈值。
3.3. Proposal Pair Double Margin Contrastive Loss
有三种不同类型的建议,标签身份,未标签身份和背景集群。OIM使用LUT来存储所有标记身份的特性。不能从不同场景的巨大差异中准确地辨别出相似的人。如图2所示,蓝色边框中左边的四个女性很容易混淆。由于行人检测的假阳性和由于OIM遗漏了与标记身份相似的背景聚类,背景聚类无法被区分。基于这两方面的考虑,我们提出PPDMC loss来辅助OIM loss来学习更鲁棒和更有分辨力的特征。Siamese-Net有两个输入字段和一个输出,其状态值对应于两个模式之间的相似性。LeCun等人[5]提出训练由两个相同的卷积网络组成的网络,它们共享学习相似度度量的权值。然后最小化判别损失函数,使相似度度量对同一个人的脸小,对不同的人的脸大。

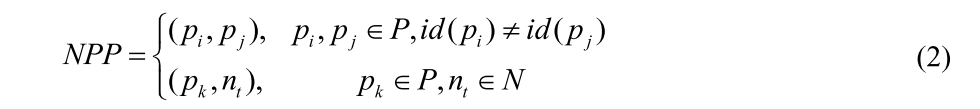
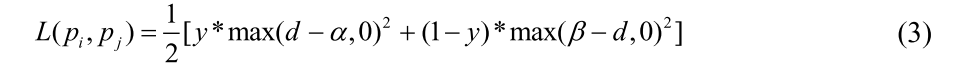
3.4. Offset Guided Erasing Data Augmentation
随机擦除是一种对图像进行数据增强的方法,用于训练卷积神经网络,降低了过拟合的风险,使模型在人脸识别中具有鲁棒性。如图4所示,输入到re-id的提案是随机位于gt周围的,很可能会删除有用的信息。模拟更真实的遮挡,我们提出由预测建议中心点和gt差分值产生的偏移量来指导擦除。

图4:对象检测的随机擦除示例。(b)物体检测的偏移导擦除例子。©建议上不同类型的擦除展览。
4 Experimental Results
在本小节中,我们将以top-1和mAP为指标,在中大- sysu和PRW数据集上,与几种目前最先进的方法进行比较。分析了IAN[6]、NPSM[8]、RCAA[19]、I-Net[4]、MGTS[22]、DisGCN[13]、GCN[24]和CLSA[17]等联合检测和搜索方法。此外,我们还比较了包括行人检测(CNN[10])、人描述符(DSIFT[9])和距离度量(XQDA[12])等在几个步骤中分离人搜索的方法。
结果CUHK-SYSU。我们和其他最先进的方法的结果列在表一:CNN是基于ResNet50的Faster RCNN检测器的缩写形式,IDNet代表re-id网。与将问题分解为单独的检测和重新识别任务的方法相比,提案人员搜索框架有了明显的改进。
OIM是整个拟建的人员搜索框架的基线。I-Net[4]引入了Siamese结构,并将在线配对损失与硬例优先级Softmax损失结合起来学习鲁棒特征表示。I-Net在前1名和mAP中都取得了大约1%的进步。
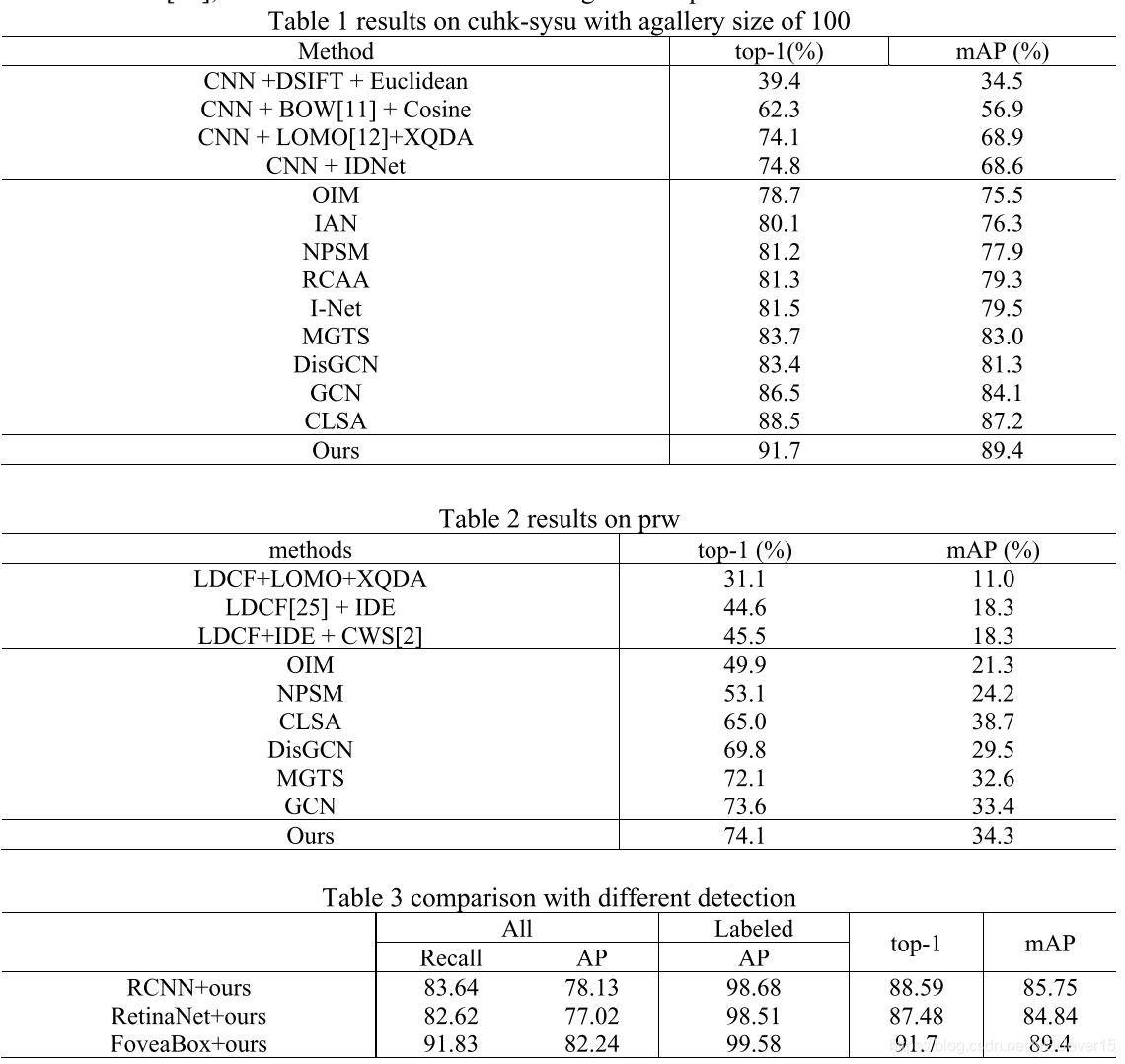
GCN[24]设计了上下文图表示和上下文实例结构来提高性能。与最先进的里昂证券[17]方法相比,我们的方法在排名前1和mAP指标上实现了3.2%/2.2%的收益.
为了验证我们的方法的可扩展性性能,我们与不同图库大小的其他人搜索方法[50,100,500,1000,2000,4000]进行了比较,如图5所示。从图中可以看出,随着画廊规模的增加,除了里昂以外,其他方法的表现退化都有所不同。但是,我们的方法在不同的图库规模下有很大的优势,这表明了我们的方法的鲁棒性。此外,我们注意到,当图库规模从500增加到4000时,我们的方法比CLAS略差,而当图库规模低于500时,我们的方法比CLAS好得多
5 Conclusion
在本研究中,我们提出了一种基于FoveaBox检测器的端到端人员搜索框架,该框架在查全率和查准率方面都有较好的表现。实验结果表明,将OIM loss和PPDMC loss结合起来对整个网络进行监控是有效的。最后,我们在re-id的训练阶段提出偏移引导擦除,与无擦除和随机擦除相比,我们的方法更有效和鲁棒。我们提出的框架在两个广泛采用的人员搜索数据集上取得了最先进的性能,这两个数据集分别是CUHK- sysu和PRW。


















 2569
2569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











