








原文链接:https://mp.weixin.qq.com/s/-R_KF13CydmoEZF1k1h_6A
可通过原文链接获取论文电子资源
内容速览
pixel2style2pixel(pSp):
- 一种通过的image-to-image的转化框架
- 基于encoder 网络, 可以直接生成许多 style vectors ,这些vectors 传递给预训练的StyleGAN 生成器,形成拓展的 w+ latent space。
- encoder可以直接嵌入真是图像到w+ 中,而没有任何附加的优化。
- 使用encoder直接来解决image-to-image的转换任务, 把它定义为从输入域到latent 域的编码问题。 所以最后的image也属于latent域?
- 通过样式的重采样支持多模态合成
contributions
- 创新的StyleGAN encoder, 用来之前编码真实的图像到 w+ latent domain。
- 使用预训练的StyleGAn 生成器来解决 image-to-image转换任务的新的方法。
源码地址: https://github.com/eladrich/pixel2style2pixel.
框架图
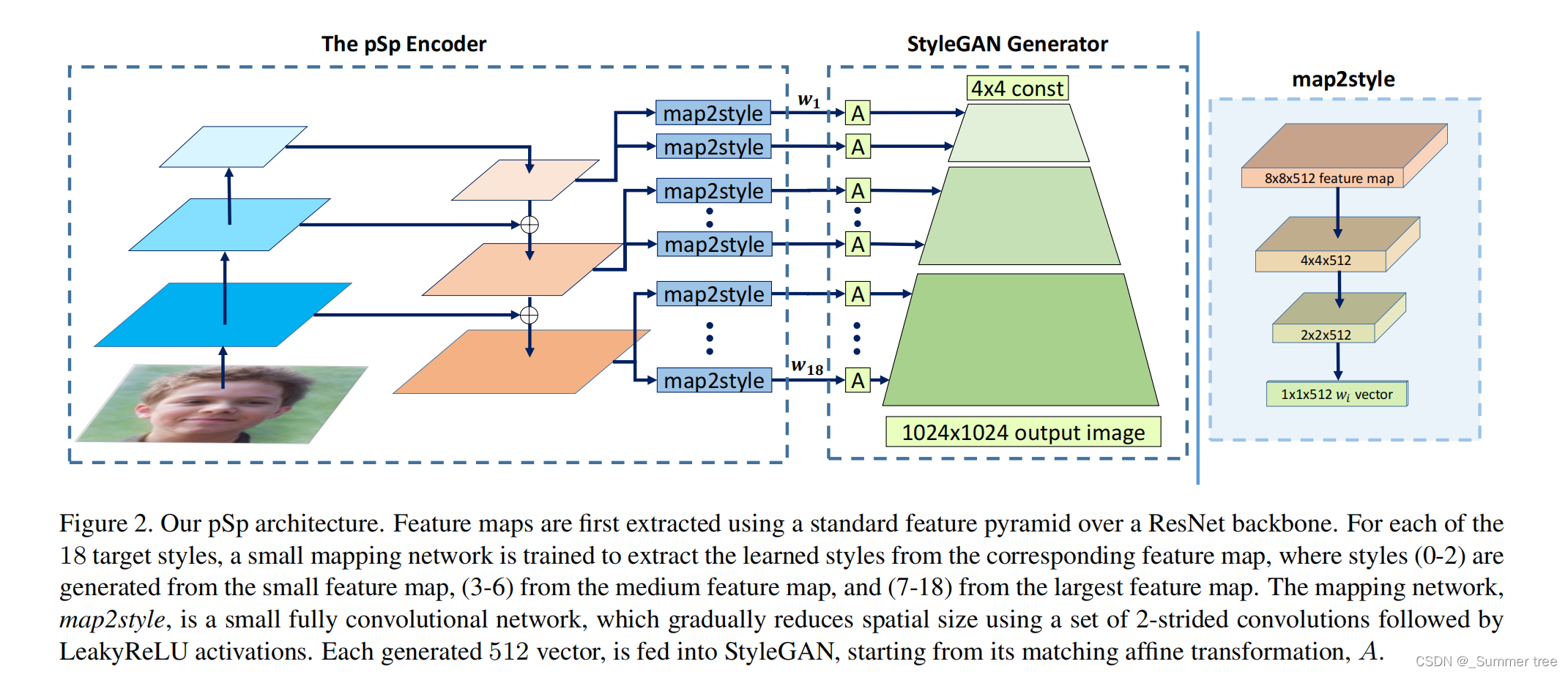
- 在ResNet的基础上,使用标准的feature pyramid 来提取特征映射。
- 对于18个目标风格中的每一个, 都有一个小的mapping net 被训练来 从对应的特征映射中提取学习到的风格。 其中,0-2 风格 是从small 特征映射中生成的,3-6 风格是从 medium 特征映射中生成的, 7-18 是从largest 特征映射中生成的。
- mapping net map2style, 是一个小的全卷积网络, 空间尺寸逐渐缩小。最后得到一个512的 w vector。
- 每个 512的 vector 喂给stylegan, 从它的匹配仿射变换A开始。
Methods
framework
- 我们用 w ˉ \bar{w} wˉ 表示与预训练生成器的 平均风格向量。
- 对于输入的图像 x , 整个模型的输出定义如下:
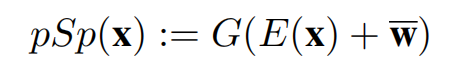
其中,E和G分别表示encoder 和 StyleGAN的生成器。
损失函数
-
像素级的 L2 损失
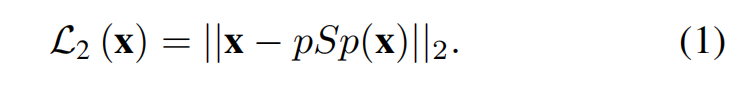
-
为了学习感知相似性,我们使用了LPIPS 损失
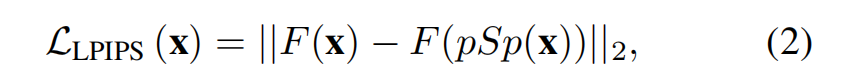
其中 F 表示perceptual feature extractor -
为了鼓励编码器输出的潜在风格向量更接近于平均潜在向量,我们定义了一下正则损失。
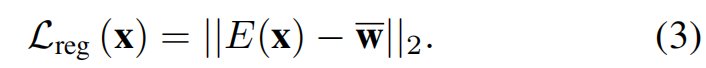
这个损失可以提高图像的质量而不伤害输出的保真度。 -
在考虑处理特定的face图像时, 我们结合 dedicated recognition loss 测量真是图像和原图像余弦相似性
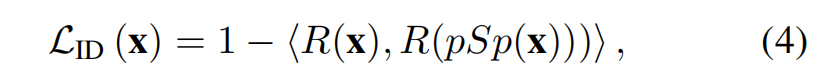
其中 R表示预训练的 ArcFace 网络。 -
整体损失表示如下:
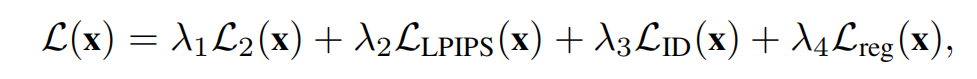
StyleGAN 域的好处
Style-mixing
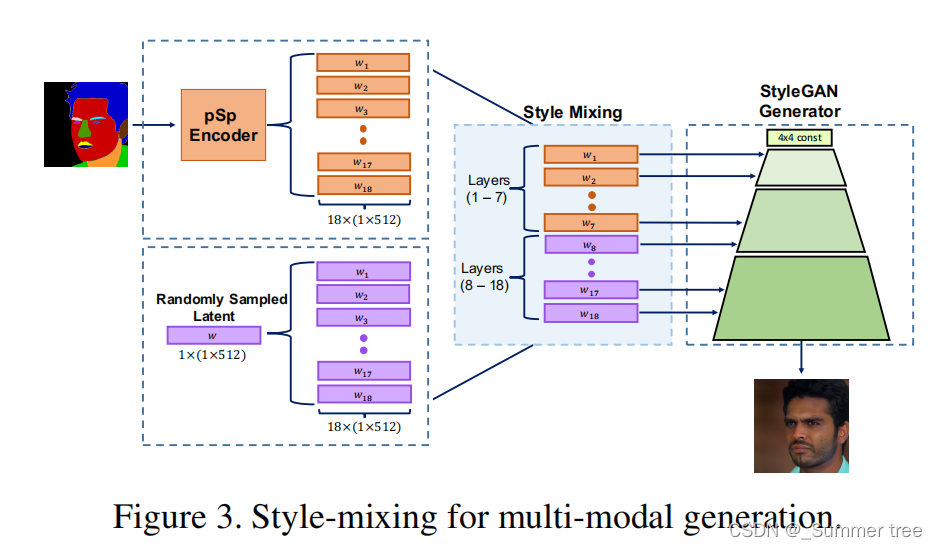
实验
StyleGAN 反转
将我们提出的encoder 和其他的几个 encoder进行对比。 结果如图4所示。

将我们提出的psp架构和两个相似的变种相比。
- 一种是单一的 512维的风格向量。
- 在第一种的基础上,增加层来转换512 到 18x 512 。
- 图5展示对比效果

- 第二种方法的效果提升了, 但不如psp 那么细节。
- 图6 展示了身份损失的重要性

量化评估展示在了表一当中。 这些指标是如何计算的?
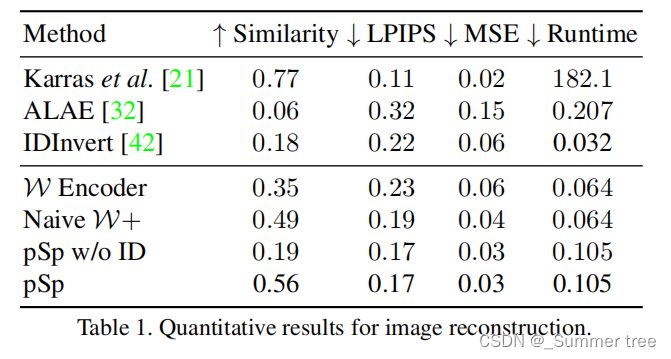
- 在感知相似性和一致性方面,pSp能够更好地保存原始图像。
- 为了确保相似度评分与我们的损失函数无关,我们使用了courseface[15]方法进行评估。
Face Frontalization(人脸转正)
我们展示了我们基于风格的翻译机制能够克服这些挑战(Face Frontalization),即使在没有标记数据的情况下进行训练。
方法
- 我们在训练过程中随机翻转目标图像,有效地迫使模型输出一个既接近原始图像又接近镜像图像的图像。这种增强背后的基本思想是,它引导模型收敛到一个固定的正面姿态。
- 我们增加Lid并减少图像外部的L2和LLlpip损失。这一变化是基于这样一个事实:与面部区域和面部特征相比,我们对保留背景区域不太感兴趣。
- 实验结果如图 7所示

- 我们的方法能够成功地处理任务,生成真实的正面脸,这可以与更复杂的R&R方法相媲美。
- 这显示了使用预先训练过的StyleGAN进行图像翻译的好处,因为它允许我们即使在监督薄弱的情况下也能获得令人满意的视觉效果
- 表2提供了FEI数据库[37]的定量评价
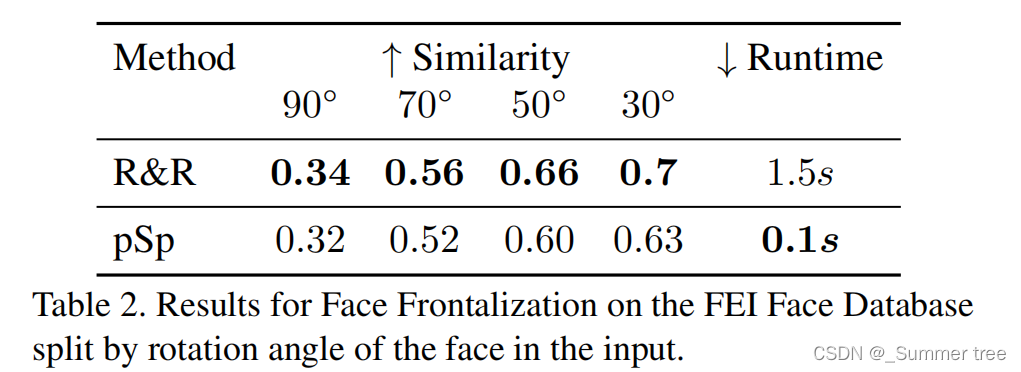
我们的简单方法提供了一种快速而优雅的替代方法,不需要专门的模块
条件图像合成
Face From Sketch

Face from Segmentation Map

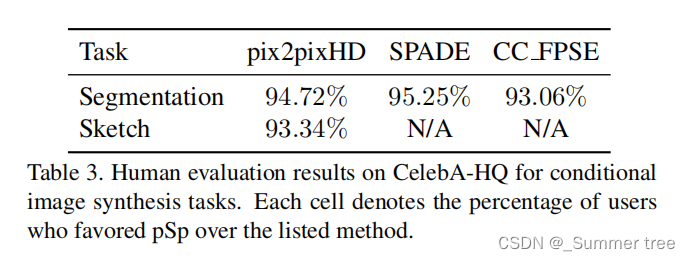
Human Perceptual Study.
Extending to Other Applications
我们还展示了通过在中等级别特征上进行风格混合来实现超分辨率的多模态支持,并评估了一些图像编辑任务的pSp,包括图像插值和局部补丁编辑。
Going Beyond the Facial Domain

讨论
- 利用预先训练的StyleGAN生成的高质量图像是有代价的,该方法仅限于StyleGAN可以生成的图像。因此,如果在训练StyleGAN模型时没有这些示例,生成不接近正面或具有特定表情的面孔可能是具有挑战性的。
- pSp的全局方法虽然对许多任务有利,但在保存输入图像的细节(如耳环或背景细节)方面存在挑战。
- 图11展示了此类重构失败的一些示例

总结
- 我们提出了一种新的编码器架构,可以用于直接映射真实图像到W+潜在空间,而不需要进行优化
- 将我们的编码器与StyleGAN解码器相结合,我们提出了一个解决各种图像到图像翻译任务的通用框架
- 与以往依赖于专门架构来解决单一翻译任务的作品不同,我们展示了pSp能够解决各种各样的问题,只需要对训练损失和方法做出最小的改变。


















 3501
3501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











