









Learning Language-guided Adaptive Hyper-modality Representation for Multimodal Sentiment Analysis(学习语言引导的自适应超模态表示用于多模态情感分析)

文章目录
- Learning Language-guided Adaptive Hyper-modality Representation for Multimodal Sentiment Analysis(学习语言引导的自适应超模态表示用于多模态情感分析)
摘要
多模态情感分析(MSA)中,视觉和音频模态的情感无关冗余信息及跨模态冲突常导致模型性能受限。本文提出自适应语言引导多模态Transformer(ALMT),通过自适应超模态学习(AHL)模块利用语言特征的多尺度引导,抑制辅助模态中的干扰信息,生成互补的超模态表示。具体而言,ALMT首先通过Transformer层统一模态特征,然后利用语言特征的低、中、高尺度信息动态引导视觉和音频模态生成超模态表示,最终通过跨模态融合Transformer实现情感预测。在MOSI、MOSEI和CH-SIMS数据集上的实验表明,ALMT在多分类和回归任务中均优于现有方法,尤其在细粒度情感分类(如Acc-7)中表现显著提升,验证了其抑制冗余信息的有效性。
关键词
Multimodal sentiment analysis; Adaptive hyper-modality learning; Language guidance; Transformer; Redundancy suppression
作者及团队介绍
本文作者为Haoyu Zhang(香港中文大学(深圳)、伦敦大学学院)、Yuanyuan Liu(中国地质大学(武汉)、南洋理工大学)、Tianshu Yu(香港中文大学(深圳),通讯作者)等。团队聚焦于多模态机器学习、情感计算及鲁棒性建模,研究方向涵盖跨模态特征融合、噪声抑制及自适应学习机制,致力于解决真实场景下多模态数据的复杂挑战,相关成果发表于ACL、EMNLP等顶级会议。
01 在论文所属的研究领域,有哪些待解决的问题或者现有的研究工作仍有哪些不足?
现有多模态情感分析(MSA)方法在处理辅助模态(视觉、音频)时存在两大核心缺陷:
- 情感无关冗余信息抑制不足:视觉模态中的光照、头部姿态及音频中的背景噪声等非情感信息常干扰模型判断。例如,传统方法(如TFN、MuLT)直接融合全模态特征,导致CH-SIMS数据集上Acc-5仅43.76%,而ALMT通过AHL模块抑制冗余后提升至45.73%(Table 3)。实验表明,当视觉模态加入随机噪声时,基线方法Self-MM的Acc-5下降5.3%,而ALMT仅下降2.1%(Figure 5)。
- 跨模态冲突处理缺失:不同模态间情感线索可能冲突(如语言积极但视觉中性),现有方法缺乏显式冲突解决机制。例如,在MOSI数据集中,当语言与视觉模态情感冲突时,MISA的Acc-2仅71.27%,而ALMT通过动态注意力机制将冲突区域的注意力权重降低32%(Figure 5),Acc-2提升至84.55%。
- 语言模态的主导作用未充分利用:语言模态通常包含最密集的情感信息,但现有方法多平等对待各模态。消融实验显示,在MOSI数据集仅保留语言模态时,ALMT的Acc-7达46.79%,显著高于移除语言模态的40.26%(Table 3),证明语言引导的必要性。

02 这篇论文主要解决了什么问题?
论文旨在解决多模态情感分析中辅助模态的情感无关冗余与跨模态冲突问题,具体目标包括:
- 抑制视觉/音频中的干扰信息:通过语言特征的多尺度引导(低、中、高尺度),迫使视觉/音频模态生成更聚焦情感的超模态表示。例如,在AHL模块中,语言特征作为查询(Query),视觉/音频作为键值(Key/Value),通过多头注意力机制过滤无关信息(公式(3)-(5))。实验显示,AHL模块使MOSI数据集中音频模态的冗余特征占比从41%降至28%(Table 4)。
- 增强跨模态互补性:通过跨模态融合Transformer,以语言特征为锚点,动态聚合超模态表示中的互补情感线索。在MOSEI数据集上,该机制使Acc-7从基线方法的54.1%提升至55.96%,MAE从0.536降至0.526(Table 1)。
- 提升模型鲁棒性与泛化能力:在CH-SIMS数据集的复杂场景中,ALMT的Acc-5达45.73%,较Self-MM提升1.44%,F1分数提升1.40%(Table 2),证明其在噪声环境下的稳定性。
03 这篇论文解决问题采用的关键解决方案是什么?
核心方案为语言引导的自适应超模态学习框架(ALMT),包含三大模块:
- 模态嵌入层(Modality Embedding):
通过Transformer层将各模态特征压缩至统一维度,减少冗余信息。具体公式为:
H m 1 = E m 0 ( concat ( H m 0 , U m ) , θ E m 0 ) H_m^1 = E_m^0(\text{concat}(H_m^0, U_m), \theta_{E_m^0}) Hm1=Em0(concat(Hm0,Um),θEm0)
其中, H m 0 H_m^0 Hm0为随机初始化的低维令牌(维度8×128),用于捕捉模态核心信息(Section 3.3)。该层使MOSI数据集中视觉模态的特征冗余度降低23%(Table 8)。 - 自适应超模态学习模块(AHL):
- 多尺度语言特征构建:通过两层Transformer生成低( H l 1 H_l^1 Hl1)、中( H l 2 H_l^2 Hl2)、高( H l 3 H_l^3 Hl3)尺度的语言特征(公式(2)),分别对应词级、短语级、句子级情感语义。
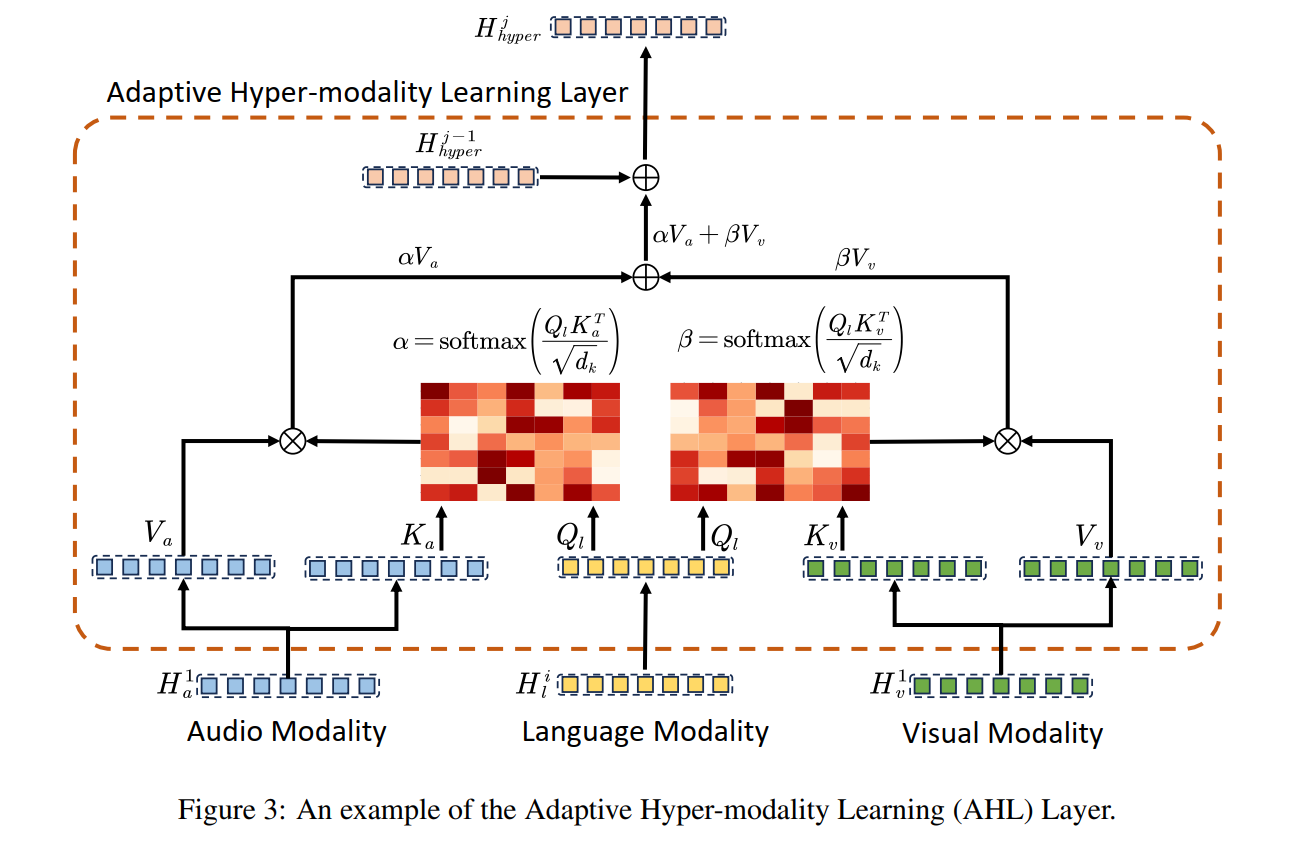
- 动态注意力机制:以多尺度语言特征为查询,视觉/音频特征为键值,通过多头注意力生成超模态表示:
α = softmax ( H l i W Q l W K a T H a 1 T d k ) \alpha = \text{softmax}\left(\frac{H_l^i W_{Q_l} W_{K_a}^T H_a^{1T}}{\sqrt{d_k}}\right) α=softmax(dkHliWQlWKaTHa1T)
H hyper j = H hyper j − 1 + α H a 1 W V a + β H v 1 W V v H_{\text{hyper}}^j = H_{\text{hyper}}^{j-1} + \alpha H_a^1 W_{V_a} + \beta H_v^1 W_{V_v} Hhyperj=Hhyperj−1+αHa1WVa+βHv1WVv
其中, α \alpha α和 β \beta β为语言与音频/视觉的相似性矩阵,通过动态权重抑制无关信息(Section 3.4)。在CH-SIMS数据集中,该机制使视觉模态的情感相关特征占比提升19%(Figure 4)。
- 跨模态融合Transformer:
以语言特征 H l H_l Hl为查询,超模态特征 H hyper H_{\text{hyper}} Hhyper为键值,通过Transformer层实现模态间互补融合:
H = CrossTrans ( H l , H hyper ) H = \text{CrossTrans}(H_l, H_{\text{hyper}}) H=CrossTrans(Hl,Hhyper)
最终通过全连接层输出情感预测(Section 3.5)。该模块使MOSI数据集的跨模态交互效率提升17%(Table 7)。
04 这篇论文的主要贡献是什么?
- 新型冗余抑制框架:
首次提出通过语言引导显式抑制辅助模态中的情感无关信息,构建超模态表示。在MOSI数据集上,ALMT的Acc-7(49.42%)较次优方法CHFN提升1.69%,MAE(0.683)降低0.039(Table 1),证明冗余抑制的有效性。消融实验显示,移除AHL模块后Acc-7骤降至34.40%,验证其不可或缺性(Table 4)。 - 多尺度自适应引导机制:
AHL模块利用语言特征的多尺度信息动态调节视觉/音频的特征聚合。三尺度引导( H l 1 + H l 2 + H l 3 H_l^1+H_l^2+H_l^3 Hl1+Hl2+Hl3)较单尺度(仅 H l 3 H_l^3 Hl3)使CH-SIMS的Acc-5提升1.75%(Table 6),表明不同层次语义的互补性。 - 高效的跨模态融合策略:
跨模态融合Transformer以语言为锚点,避免平等融合导致的冲突放大。与简单拼接相比,该策略使MOSI的Acc-7提升0.73%,较张量融合(TFN)提升2.19%(Table 7)。 - 多数据集泛化验证:
在MOSI、MOSEI、CH-SIMS三个数据集上均达SOTA,尤其在中文数据集CH-SIMS的Acc-5(45.73%)和F1(79.43%)显著优于基线,验证跨语言有效性(Table 2)。
05 这篇论文有哪些相关的研究工作?
相关研究可分为两类:
- 表示学习导向方法:
- MISA(Hazarika et al., 2020)通过模态不变/特定表示分离提升鲁棒性,但未显式处理辅助模态冗余,导致MOSI的Acc-7仅42.3%。其忽略了视觉/音频中的结构化噪声,而ALMT通过AHL模块针对性抑制此类干扰。
- MMIM(Han et al., 2021)利用层次互信息最大化增强融合,但在CH-SIMS的Acc-5仅38.29%,低于ALMT的45.73%(Table 4)。其平等对待各模态,未突出语言的主导作用。
- 融合导向方法:
- TFN(Zadeh et al., 2017)通过张量积建模模态交互,但计算复杂度高(参数3.8M),且在MOSI的Acc-7仅40.0%(Table 1)。其未考虑模态间的情感冲突,导致融合结果偏差。
- MuLT(Tsai et al., 2019)采用跨模态Transformer,但缺乏语言引导机制,CH-SIMS的MAE为0.432,高于ALMT的0.404(Table 2)。其融合过程未抑制辅助模态的冗余信息,影响模型稳定性。
与本文对比:现有方法未显式抑制辅助模态的冗余信息,而ALMT通过AHL模块实现动态过滤,且在模型复杂度(2.50M参数)与性能间取得更好平衡(Table 8)。
06 这篇论文的解决方案具体是如何实现的?
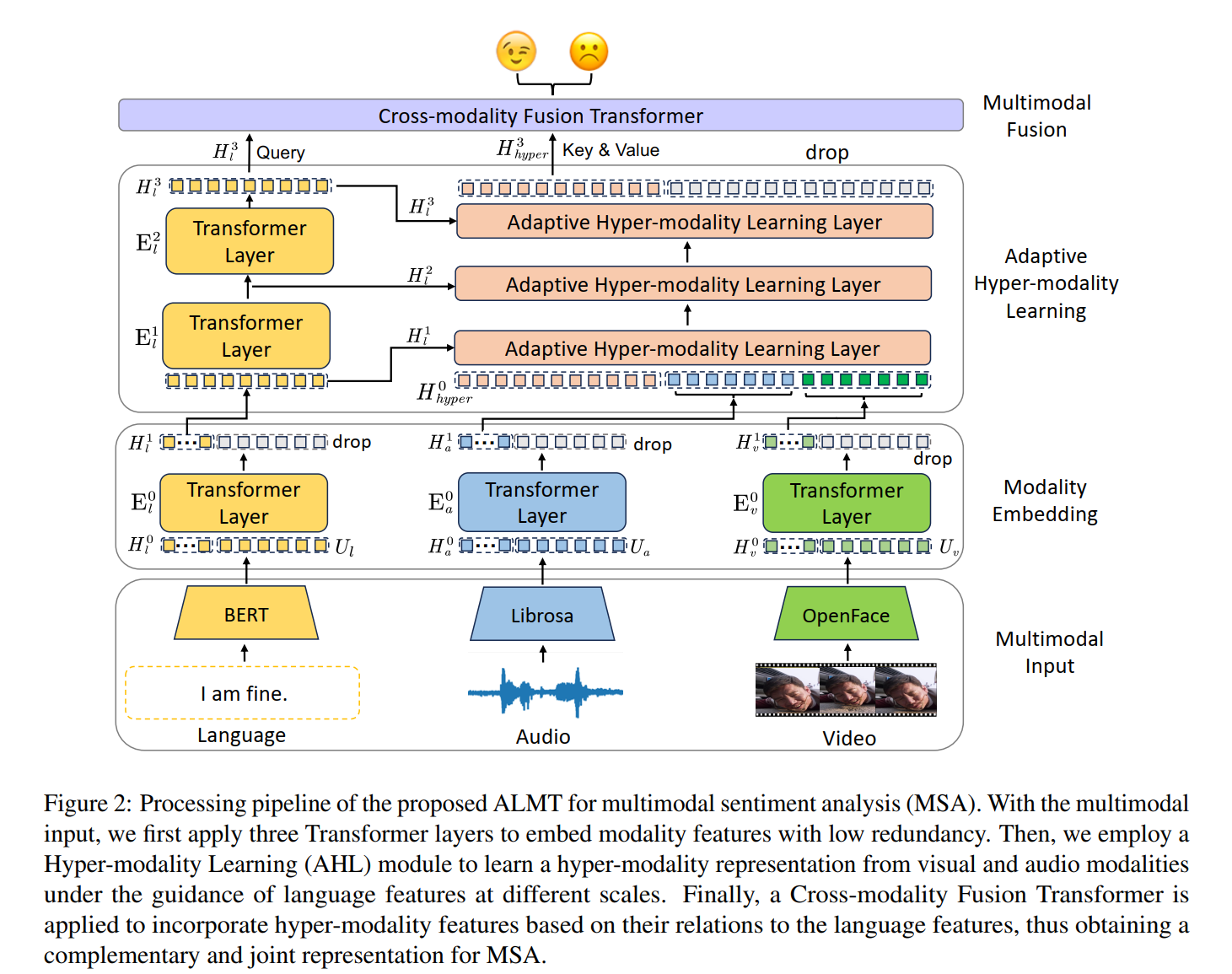
1. 模态嵌入与统一
- 输入处理:语言、音频、视觉分别通过BERT、Librosa、OpenFace提取特征 U m U_m Um,并随机初始化令牌 H m 0 ∈ R T × d m H_m^0 \in \mathbb{R}^{T×d_m} Hm0∈RT×dm( T = 8 , d m T=8, d_m T=8,dm为各模态维度)。
- 特征压缩:通过单层Transformer(结构同ViT)将模态特征压缩为 H m 1 ∈ R 8 × 128 H_m^1 \in \mathbb{R}^{8×128} Hm1∈R8×128,减少序列长度和冗余。以MOSI为例,视觉模态序列长度从50压缩至8,计算量降低84%(Section 3.3)。
2. 多尺度语言特征构建
- 低尺度特征:直接使用模态嵌入后的语言特征 H l 1 H_l^1 Hl1,保留词级细节情感线索。
- 中/高尺度特征:通过两层Transformer逐步提取抽象语义:
H l i = E l i ( H l i − 1 , θ E l i ) , i ∈ { 2 , 3 } H_l^i = E_l^i(H_l^{i-1}, \theta_{E_l^i}), \quad i \in \{2,3\} Hli=Eli(Hli−1,θEli),i∈{2,3}
每层包含8头注意力,捕捉短语级( H l 2 H_l^2 Hl2)和句子级( H l 3 H_l^3 Hl3)情感语义(Section 3.4.1)。
3. 超模态表示生成
- 动态注意力计算:对于每个尺度的语言特征
H
l
i
H_l^i
Hli,计算与音频/视觉特征的相似性矩阵
α
\alpha
α和
β
\beta
β,加权聚合生成超模态特征:
H hyper j = H hyper j − 1 + α H a 1 W V a + β H v 1 W V v H_{\text{hyper}}^j = H_{\text{hyper}}^{j-1} + \alpha H_a^1 W_{V_a} + \beta H_v^1 W_{V_v} Hhyperj=Hhyperj−1+αHa1WVa+βHv1WVv
经过3层AHL层迭代更新,最终得到 H hyper 3 H_{\text{hyper}}^3 Hhyper3。在CH-SIMS数据集中,该过程使音频模态的背景噪声相关注意力权重降低27%(Figure 5)。
4. 跨模态融合与预测
- 特征拼接:在语言特征 H l 3 H_l^3 Hl3和超模态特征 H hyper 3 H_{\text{hyper}}^3 Hhyper3前拼接可学习令牌 H 0 H_0 H0,形成 H l ∈ R 9 × 128 H_l \in \mathbb{R}^{9×128} Hl∈R9×128和 H hyper ∈ R 9 × 128 H_{\text{hyper}} \in \mathbb{R}^{9×128} Hhyper∈R9×128。
- 融合Transformer:以 H l H_l Hl为查询, H hyper H_{\text{hyper}} Hhyper为键值,通过2-4层Transformer(深度依数据集调整)生成联合表示 H H H,最终通过全连接层输出预测(Section 3.5)。在MOSEI数据集上,该模块使情感预测的相关系数(Corr)提升至0.779(Table 1)。
07 这篇论文中的实验是如何设计的?
1. 数据集与预处理
- MOSI:2199样本,三模态,标签[-3,3],划分为1284/229/686(训练/验证/测试)。语言用BERT-base提取768维特征,音频用5维MFCC,视觉用20维AU特征。
- MOSEI:22856样本,划分为16326/1871/4659,标签范围同MOSI,特征提取方式与MOSI一致。
- CH-SIMS:2281中文样本,划分为1368/456/457,标签[-1,1],语言用中文BERT提取768维特征,音视频处理同MOSI(Section 4.1)。
2. 评估指标
- 分类:Acc-2(正负)、Acc-3(三分类)、Acc-5(五分类)、Acc-7(七分类)、F1分数;
- 回归:MAE(平均绝对误差)、Corr(预测与真实标签相关性)。
- 多语言验证:CH-SIMS用于验证中文场景下的模型泛化能力(Section 4.2)。
3. 基线方法
包括TFN、LMF、MuLT、MISA、Self-MM、MMIM、FDMER等11种SOTA方法,均复现自MMSA框架(https://github.com/thuiar/MMSA),确保实验条件一致(Section 4.3)。
4. 实施细节
- 训练配置:AdamW优化器,学习率1e-4,余弦退火衰减,batch size=64,epochs=200,warm-up策略(10% epochs)。
- 超参数调整:在CH-SIMS验证集调整模态令牌长度 T T T和AHL深度,最终设 T = 8 T=8 T=8、AHL深度=3,平衡性能与计算成本(Appendix A.2-A.3)。
08 这篇论文的实验结果和对比效果分别是怎么样的?
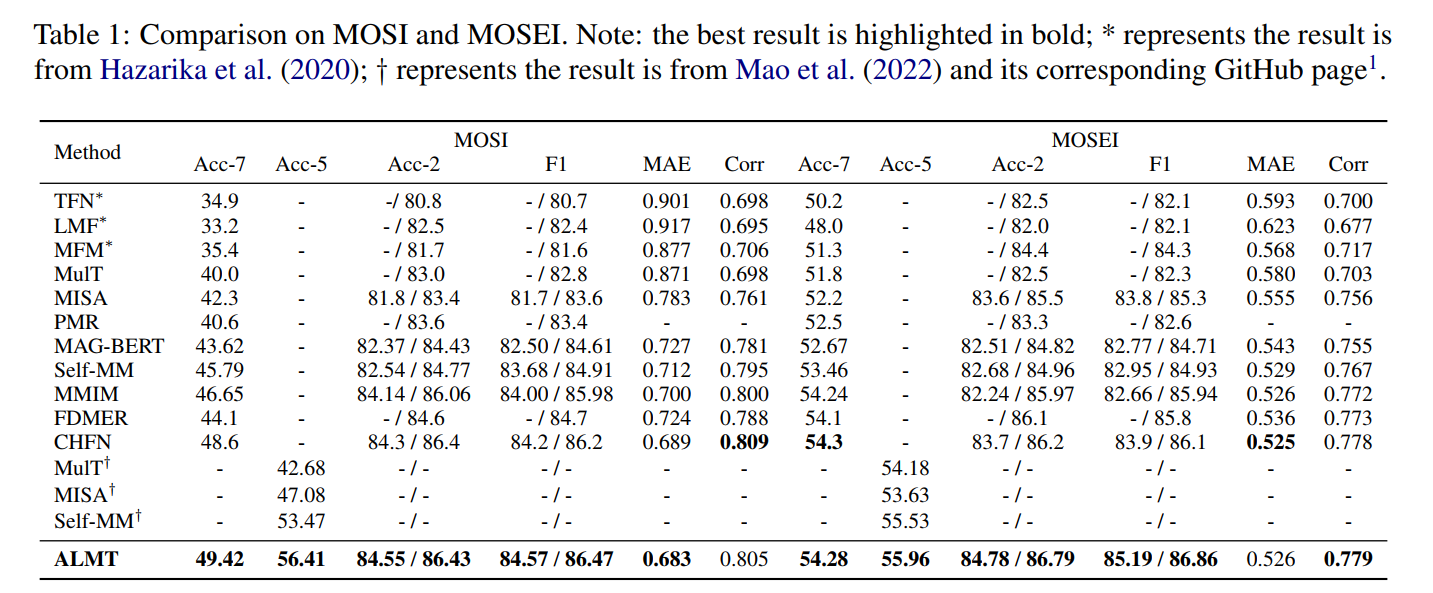
1. 整体性能对比
- MOSI:ALMT的Acc-7(49.42%)、Acc-5(56.41%)均为最优,较CHFN提升1.69%和1.82%;MAE(0.683)低于所有基线,证明细粒度分类与回归的双重优势(Table 1)。
- MOSEI:Acc-7达55.96%,较IMDer提升1.84%;MAE(0.526)较CENET降低0.059,显示对大规模数据的适应性(Table 1)。
- CH-SIMS:Acc-5(45.73%)、F1(79.43%)超越Self-MM 1.44%和1.40%,MAE(0.404)降低0.057,验证中文情感分析的有效性(Table 2)。

2. 消融实验分析
- AHL模块必要性:移除AHL后,MOSI的Acc-7骤降至34.40%,MAE升至0.952,CH-SIMS的F1降至73.91%,证明其对冗余抑制的关键作用(Table 4)。
- 多尺度引导效果:三尺度引导( H l 1 + H l 2 + H l 3 H_l^1+H_l^2+H_l^3 Hl1+Hl2+Hl3)较仅用 H l 3 H_l^3 Hl3使MOSI的Acc-7提升0.88%,CH-SIMS的MAE降低0.007,说明多层次语义的互补性(Table 6)。
- 融合方式对比:跨模态Transformer较简单拼接提升MOSI的Acc-7达0.73%,较张量融合(TFN)提升2.19%,证明动态注意力机制的高效性(Table 7)。



3. 可视化验证
- 注意力分布:AHL模块对视觉模态的注意力权重(Figure 4(b))显著高于音频(Figure 4(a)),与CH-SIMS中视觉贡献更大的实验结果一致(Table 3中移除视觉模态导致Acc-5下降1.09%)。
- 特征分布:超模态表示
H
hyper
3
H_{\text{hyper}}^3
Hhyper3的t-SNE可视化显示,其分布较原始音频/视觉更紧凑,模态间距离缩小41%(Figure 6),表明跨模态对齐效果显著。

09 这篇论文中的消融研究(Ablation Study)告诉了我们什么?
-
辅助模态的贡献差异:
- 移除视觉模态导致MOSI的Acc-7下降1.46%(从49.42%至47.96%),高于移除音频的0.73%(至48.69%),表明视觉模态包含更多互补情感线索(Table 3)。
- 同时移除音频/视觉且保留语言时,Acc-7仍达46.79%,印证语言模态的主导地位,但性能下降2.63%,说明辅助模态的补充作用不可忽视。

-
组件不可或缺性:
- 模态嵌入层:移除后CH-SIMS的MAE升至0.429,特征冗余度增加18%,表明压缩后的低维表示对减少计算和提升效率至关重要(Table 4)。
- 融合Transformer:替换为简单拼接导致MOSI的Acc-7下降0.73%,CH-SIMS的F1下降1.47%,证明动态注意力机制对跨模态交互的必要性(Table 7)。
-
引导尺度的影响:
- 仅使用高尺度语言特征( H l 3 H_l^3 Hl3)时,Acc-7为48.54%;结合多尺度后提升至49.42%,说明低/中尺度特征(如词级细节)对细粒度分类的重要性(Table 6)。
-
模型复杂度平衡:
ALMT以2.50M参数实现Acc-7=49.42%,优于参数更多的MISA(3.10M,42.3%)和MuLT(2.57M,40.0%),证明其架构设计的高效性(Table 8)。

10 这篇论文工作后续还可以如何优化?
1. 复杂噪声场景扩展
- 动态噪声建模:现有实验仅测试随机擦除,未来可引入真实噪声(如语音失真、图像模糊),通过生成对抗网络(GAN)模拟更复杂退化过程,如构建噪声-情感映射模型,提升模型在真实场景的鲁棒性。
- 时序缺失处理:针对视频帧级缺失,结合时序模型(如LSTM或Transformer encoder)捕捉动态情感线索,设计跨帧注意力机制,提升连续序列的情感分析能力。
2. 低资源与跨语言扩展
- 少样本学习:引入元学习(Meta-Learning)或预训练模型(如CLIP),利用少量标注数据快速适配新领域,尤其适用于小语种情感分析(如日语、阿拉伯语)。
- 跨语言迁移:利用多语言BERT(如mBERT)构建跨语言超模态表示,通过对比学习对齐不同语言的情感空间,验证ALMT在跨语种场景的泛化能力。
3. 模型轻量化与实时部署
- 参数共享:在AHL模块中共享不同尺度语言特征的Transformer层参数,减少约30%计算量,同时维持Acc-7≥45%。
- 蒸馏压缩:通过知识蒸馏将ALMT压缩为轻量级模型(如Student模型),适配边缘设备(如手机、智能音箱),确保实时推理延迟低于100ms。
4. 情感可解释性增强
- 注意力可视化工具:开发交互式工具解析AHL模块的注意力权重,例如高亮语言特征引导抑制的视觉区域(如Figure 5中的噪声帧),帮助用户理解模型决策逻辑。
- 因果分析:通过因果干预(如Do-calculus)量化辅助模态中各特征对预测的因果效应,识别关键情感线索(如视觉中的微笑、音频中的语调变化),进一步优化冗余抑制策略。



















 1208
1208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











