







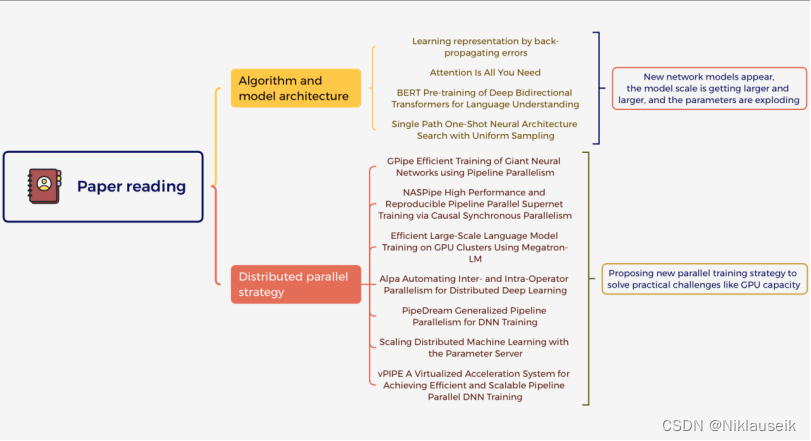
This figure shows my classification and summary of these papers.
My reading notes are below. Each note following the headline is divided into several parts, which are the summary, advantages, evaluation and improvement of the paper.
Learning representations by back-propagating errors
- The team describe a new back-propagation learning procedure for networks of neurone-like units, which adjusts the weight of those connections in the network over and over in order to reduce the difference between the actual output vector and the desired output vector little by little. And as a consequence of the adjustments of weight, the internal ‘hidden’ units which do not belong to input or output come to present significant features of the task domain. Meanwhile, the interactions of these units extract the regularities in this task. This new learning procedure distinguishes from earlier, simpler methods like the perceptron-convergence(they do not learn representation) procedure because of its ability to create useful new features.
Aiming at finding a powerful synaptic modification rule that allow neural network to develop an internal structure that is appropriate for a particular task domain, there have been many attempts used self-organizing neural networks. So the task is important, the difficulty is closely related to whether the task is specified. If the task is specified by the desired state vector of the output units and the input units are directly connected to output units, it is easy to find learning rules, finally, the difference between the actual output and the desired output is progressively reduced. Things are different and more difficult when we introduce hidden units whose actual or desired states are not specified by the task. In order to achieve the desired input-output behaviour,when the hidden units should be active must be decided by the learning procedure.And the team prove that a general purpose and relatively simple procedure is powerful enough to construct appropriate internal representations.
2.Divided into three levels, the simplest form of the learning procedure has a layer of input units at the bottom; any number of intermediate layers; and a layer of output units at the top. Connections within a layer or from higher to lower layers are forbidden,but connections can skip intermediate layers. An input vector is presented to the network by setting the states of the input units.Then the states of the units in each layer are determined by applying equations (1) and (2) to the connections coming from lower layers. All units within a layer have their states set in parallel, but different layers have their states set sequentially, starting at the bottom and working upwards until the states of the output units are determined.
3.The most obvious limitation of this learning procedure is about the local and overall problems. The error-surface may contain local minima so that gradient descent is not guaranteed to find a global minimum. But this rarely happens.
4.Although the learning procedure, in its current form, is not a plausible model of learning in brains. Its application in various tasks shows that interesting internal representations can be constructed by gradient descent in weight-space, and this suggests that it is worth looking for more biologically plausible ways of doing gradient descent in neural networks.
Attention Is All You Need
1.The team propose the Transformer, a new simple network architecture which is based on attention mechanisms and totally dispenses with recurrence and convolutions. It consists of two parts: encoder and decoder which associate with the dominant sequence transduction models are based on complex recurrent or convolutional neural networks. Through an attention mechanism connecting encoder and decoder, the model can show best performance. After experiments and displays, the results show that: these models have higher quality and do better in parallel tasks, at the same time needs less time to train.
2.Recurrent language models and encoder-decoder architectures, associating with sequence modeling and transduction problems such as language modeling and machine translation, are current nowadays. Although recent work has achieved significant improvements in computational efficiency through factorization tricks and conditional computation, as a result of sequential computation, constrains and the Gradient disappearance problem still remain. But with the help of attention mechanisms which allows modeling of dependencies without regard to their distance in the input or output sequences, the Transformer can eschewing recurrence. So, Transformer relies entirely on an attention mechanism to draw global dependencies between input and output, which allows for significantly more parallelization and can reach a new state of the art in translation quality especially after enough training.
3.The Transformer follow the overall architecture which contains encoder and decoder. Encoder map an input sequence of symbol representations to a sequence of continuous representations and then decoder generate an output sequence. The whole process is auto-regressive and the next output relies on previous output. The encoder is composed of a stack of N = 6 identical layers so do the decoder.
The attention function mechanism operates through a batch of vectors: the query, keys, values, and output. Map query and a set of key value pairs to an output which is weighted sum of values. The Transformer uses multi-head attention in three different ways: In “encoder-decoder attention” layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. The encoder contains self-attention layers. self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position.
4.Considering of total computational complexity per layer, parallel computing and s the path length between long-range dependencies in the network, the team chose the self-attention. Self-attention provides with feasible parallel computing, lower operational complexity and generate more interpretable models.
5.The team trained on the standard dataset and used the Adam to optimize. Residual Dropout and Label Smoothing were used for regularization. Further experiments show that the large transformer model has higher scores and lower training costs than the previously published best model. As expected,bigger models are better, and dropout is very helpful in avoiding over-fitting.
The first sequence transduction model based entirely on attention,the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers for translation tasks. And the team is planning to extend the Transformer to problems involving input and output modalities other than text.
GPipe: Efficient Training of Giant Neural Networks
using Pipeline Parallelism
-
Known as an effective method to improve the quality of model for several different machine learning tasks, scaling up the capacity deep of neural network increases model capacity beyond the memory limit of a single accelerator has required developing special algorithms or infrastructure, in many instances. And this kind of solution usually is specified by architecture so it cannot transfer to other tasks. Considering all these constrains and limitations, the team proposed and introduced GPipe, which is a pipeline parallelism library allowing scaling any network which can be expressed as a sequence of layers. The GPipe is able to address the meet the requirements of efficient and task-independent model parallelism. GPipe provides the flexibility to efficiently scale a variety of different networks to a large scale by By pipelining different sub-sequences of layers on separate accelerators. Besides, when the model is divided across multiple accelerators, GPipe can almost achieve linear speedup, using a new a novel batch-splitting pipelining algorithm. The team trained large-scale neural networks on Image Classification attaining a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1432
1432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









