







深度学习经典神经网络:ResNet
1. 简介
众所周知,自 2012 年 AlexNet 在 ILSVRC 一战成名后,卷积神经网络便一发不可收拾,后续的各类竞赛中各种神经网络都大发异彩,除了更高的准确率之外,它们普遍的特征就是,网络的层级越来越深。这里会产生一个问题,神经网络真的是越深就会越好吗?但是证据表明,情况不是这样的,如果神经网络越来越深,神经网络可能会出现退化现象。
有一个解决方案是:在一个常规的比较浅的模型上添加新的层,而新的层是基于identity mapping的。identity mapping可以称之为恒等变换,也就是说输入和输出是相等的映射关系。
那么如何做呢?作者引入了deep residual learning framework,也就是基于残差的深度学习框架,实际上是需要对常规的神经网络的改造。
我们都知道,目前流行的神经网络都可以看成是卷积层的堆叠,可以用栈来表示,我们就叫它卷积栈好了。
输入数据经过每个卷积层都会发生变化,产生新的 feature map,我们可以说数据在输入与输出间发生了映射,也就是mapping。神经网络中的权重参数一个作用就是去拟合这种输入与输出之间的 mapping。
ResNet 准备从这一块动手,假设现在有一个栈的卷积层比如说 2 个卷积层堆叠,将当前这个栈的输入与后面的栈的输入之间的mapping 称为 underlying mapping,现在的工作是企图替换它引入一种新的mapping 关系,ResNet 称之为 residual mapping 去替换常规的 mapping 关系。
然后,作者假设对residual mapping的优化要比常规的 underlying mapping 要简单和容易,而F(x)+x在实际的编码中,可以被一种叫做快捷连接的结构来实现。

2. Deep Residual Learning
我们可以将焦点放在 H(x)H(x)H(x) 上,理论上有一种假设,多层卷积的参数可以近似地估计很复杂的函数表达公式的值,那么多层卷积也肯定可以近似地估计H(x)-x这种残差公式。
所以与其让卷积栈去近似的估计H(x)-x,还不如让它去近似地估计 F(x):=H(x)−x, 而F(x)就是残差。作者假设的是,残差比原始的 mapping 更容易学习。
一个残差单元,它的输入与输出的关系可以用下面的公式表达:
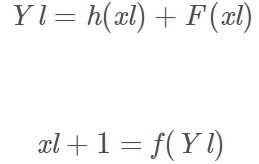
l 代表层的意思,xl代表当前这个残差单元的信号输入,xl+1代表输出,同时也是神经网络下一层的输入。h(x)代表的 identity mapping,F(xl)是这个单元的残差,f(yl)是ReLU 激活函数。
ResNet网络结构如下图所示:

作者对 VGG-19 进行仿制与改造,得到了一个 34 层的 plain network,然后又在这个 34 层的 plain network 中插入快捷连接,最终形成了一个 34 层的 residual network。

我们回到这张图上面,F(x)F(x)F(x) 要与 x 相加,那么它们的维度就需要一样。
而 ResNet 采用的是用 1x1 的卷积核去应对维度的变化,通过 1x1 的卷积核去对输入进行升维和降维。值得注意的是,从 50-layer 起,ResNet 采用了一种 bottleneck design 的手段。

1x1 的卷积核让整个残差单元变得更加细长,这也是 bottleneck 的含义,更重要的是参数减少了。















 6706
6706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









