







 本文探讨了机器学习中模型优化的策略,重点关注损失函数在经验风险和结构风险平衡中的作用。介绍了误差的来源:Bias、Variance和Irreducible error,并讨论了如何通过权衡这两者来优化模型。接着详细讲解了分类和回归模型的常见损失函数,如Hinge loss、Log loss和Square loss等,强调了一个好的损失函数应具备的特性。
本文探讨了机器学习中模型优化的策略,重点关注损失函数在经验风险和结构风险平衡中的作用。介绍了误差的来源:Bias、Variance和Irreducible error,并讨论了如何通过权衡这两者来优化模型。接着详细讲解了分类和回归模型的常见损失函数,如Hinge loss、Log loss和Square loss等,强调了一个好的损失函数应具备的特性。
上一篇文章介绍了机器学习三要素中的第一个要素-模型,模型部分限制了预测模型函数的假设空间。本文将要介绍的第二个要素-策略,策略部分就是要定量判断不同参数下模型的优劣,为第三步求解最优模型做基础。由于策略部分想要介绍的内容较多,所以分成了两篇,这是第一篇,主要是对正则化系数和损失函数的介绍。
本文首发于我的知乎专栏《机器怎么学习》中机器学习·总览篇(6) 三要素之策略 - 损失函数,转载请保留链接 😉
机器学习的学习目标是获得假设空间(模型)的一个最优解,在模型部分,我们固定了模型函数的形式,在此基础上选择最优参数即可。那么对于任意参数的模型,如何评判解是参数是优还是不优?如下图1中所示的一个线性回归和线性分类的例子,
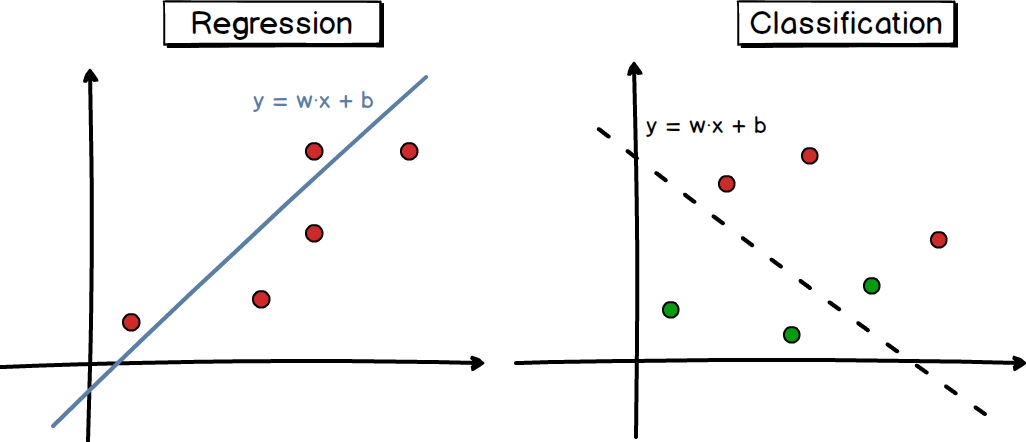
如图1所示,图中左子图是一个回归(Regression)任务,随意画一条拟合线性函数曲线,拟合效果看起来还不错,但定量的来看,到底有多不错?又比如右子图所示是一个分类(Classification)任务,随意画一条判别线性函数曲线,分割效果看起来也还行,但定量的来看,到底有多还行?这就引出了文本要介绍的内容-机器学习三要素的第二个要素-策略。策略部分就是评判“最优模型”(最优参数的模型)的准则和方法。图2所示就是策略的函数形式,
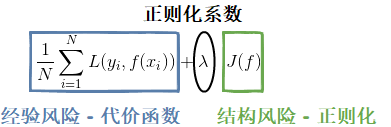
如图2所示的函数即经验结构风险的度量函数,也被称为目标函数(Object function),我们的优化目标就是选取最优的模型参数使目标函数的函数值最小,符合这个优化目标的模型就是最优的。目标函数由两部分组成,经验风险和结构风险:经验风险越小意味着模型在训练样本集上预测越准确,经验风险由代价函数表征,通过使模型预测值与训练样本标签尽可能接近来实现;结构风险越小意味着模型越简单,结构风险由正则化项表征,通过使模型参数尽可能小来实现。将经验风险和结构风险放在一起就要考虑权衡问题了,只有权衡两者才能尽可能地减少学习误差。所以我们要解决的第一个问题就是处理经验风险和结构风险的平衡问题(本文的第一节);然后再分析代价函数(本文的第二节)和正则化项(下一篇文章)各自应该如何选择。
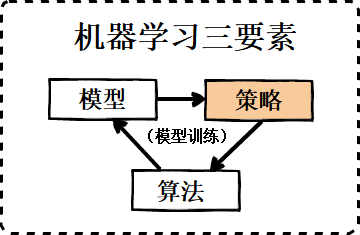
一、经验风险和结构风险的平衡
直接从机器学习模型的预测误差来分析,机器学习中的Error(误差)来源主要为Bias(偏差)、Variance(方差)以及Irreducible error(Noise,噪声)&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









