







Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
基本信息
- 论文链接:arxiv
- 发表时间:2021 - ICCV - best paper
- 应用场景:
摘要
| 存在什么问题 | 解决了什么问题 |
|---|---|
| 1. 鉴于图像中物体尺度的剧烈变化,利用transformer建模相对困难,以及图像相对于文本来说,像素的数量太大导致token数量激增,使得计算量骤增,所以把transformer应用在图像上是一件棘手的事情。 | 1. 提出了一个通用视觉transformer-based backbone,该backbone具备hierarchical design与shift window特性,使得计算量和图像大小是线性相关的,不再是平方关系。而且验证了使用该backbone后不论在分类、目标检测还是语义分割上任务上精度都达到了SOTA, |
模型结构

整个网络由patch embedding + swin transformer block + patch merging三个模块组成。
patch embedding
patch embedding和vit一样,由组patch和fc层组成,但是这里的patch_size比较小,初始值一般为4x4,不像vit那样动辄14x14或者16x16,此时每个patch的通道数为3x4x4=48。所以此时得到的patch数量要多于常规vit的patch数量。
swin transfromer block

可以将其看成是一个级联结构,有两个self-attention模块,只不过这两个模块在MSA上有些许异同。
W-MSA
仅在每个patch内做self-attention,这样做的目的是大大降低了计算复杂度,使得计算量级从O(N^2)变为O(N)。和普通的MHSA的计算量对比如下:

推导过程就不列了,还是挺直观的,该时间复杂度包含了计算qkv,q k T k^T kTV以及一个fc层。
从公式(1)中可以看到MSA的计算量正比于patch_num的平方,而(2)中W-MSA正比于patch_size的平方。可以认为是正比于patch_num。因此计算复杂度下降了一个量级。
SW-MSA

虽然降低了MSA的计算复杂度,但此时计算self-attention仅在每个patch内进行,而patch间是没有信息传递的,这么做特征表达肯定会受到限制,因此作者这里引入了shifted-window机制让每个patch和其临近的patch产生信息交互,增强模型特征表达能力。
具体表现为将所有patch向图像右下角移动**int(M/2)**个单位,M为patch的高度(或者宽度)。超出图像的部分沿轴对称(或中心对称)补回图像中因位移空出来的部分。此时再去计算W-MSA的时候就会包含了原先每个patch其临近patch的信息,增强模型的表达能力。

所以swin transformer block内的整体计算流程如下:

通过堆叠若干个swin transformer block,,每个block内部对每个patch先执行W-MSA,再执行SW-MSA,使得每个patch能够和离自己距离较远的patch也产生信息融合,进而达到扩大感受野的作用。
patch merging
将每个patch看成一个像素点,通过一个大小为2x2,stride=2的窗口对每个patch进行concat,那么此时patch数量减半,patch的channel变为原先的4倍,再通过一个fc层将其降低为1/2,即channel变为原先的2倍。即完成了像CNN那样,图像大小减半,深度增加一倍的策略。
若干个swin transformer block和一个patch merging module组合就可以抽取更深层的语义信息。这种类似于卷积的操作范式很容易将其应用到FPN、UNet等主流结构中。进而也衍生出了众多应用于不同任务上的以swin transformer为backbone的网络结构。
Relative position bias
在每次计算self attention的时候,在attention matrix上(softmax之前)会加上一个相对位置偏移量B:

B是从relative position matrix B ^ s h a p e = [ 2 M − 1 , 2 M − 1 ] \hat{B} shape=[2M-1,2M-1] B^shape=[2M−1,2M−1]上采样而来的。
作者通过实验发现加上这个相对偏移量,会有比较大的提升,另外也验证了相对位置便宜的策略是最优的。
实验
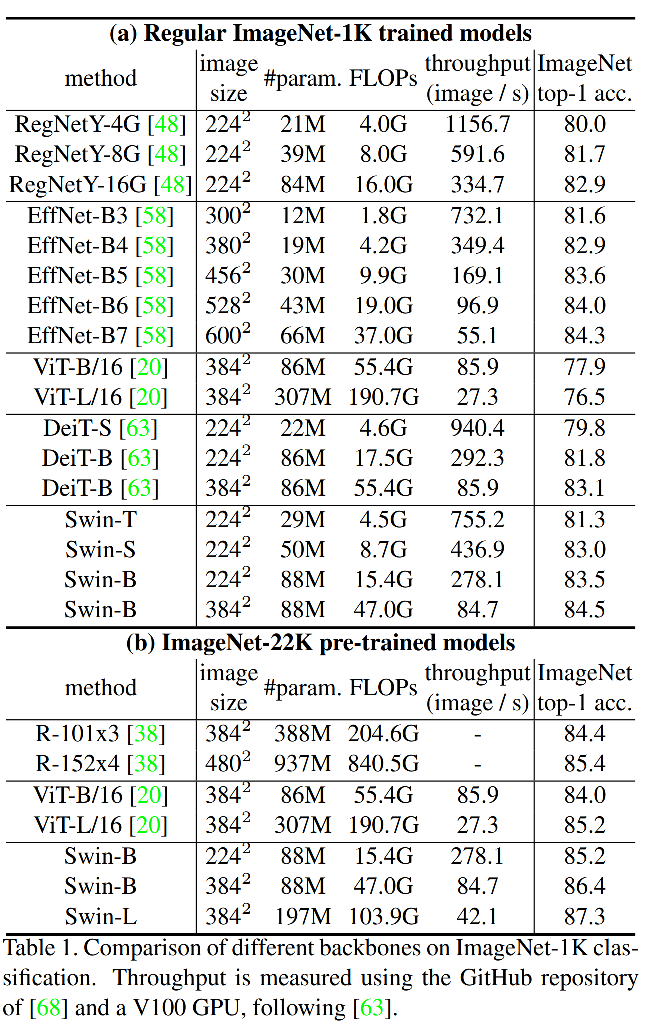
图像分类任务,不论是基于ImageNet-1K还是ImageNet-22K数据集上的预训练模型,均达到了SOTA。
目标检测以及实例分割任务上,将resnet50替换成swin-T,resnet101替换成swin-S,各模型精度都会有明显的提升。另外基于HTC的swin-L在目标检测和实例分割任务上均达到SOTA。

语义分割任务,将UperNet中的backbone换成swin-L达到SOTA。

消融实验:
- 在shift-window上的消融实验,验证了用shift-window策略后相比不用shift-window有着明显提点。
- 相对位置偏移量带来的受益也是最高的。尤其是在目标检测以及语义分割任务上提升较大。

总结
- 提出了一个由W-MSA和SW-MSA组成的transformer block,将这个block和patch merging模块堆叠起来就构成了swin transformer backbone,降低了计算复杂度的同时其精度在图像分类、目标检测、实例分割、语义分割任务上均取得了SOTA,达到了所有视觉任务通杀的效果。
- 效果好的原因个人认为还是加上了归纳偏执,类似CNN的局部连接,不再像VIT那样是一个纯粹的transformer了。不过从效果上来看还是非常惊艳的,是一个不可多得的打比赛利器。















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









