






前沿科技速递🚀
近日,Qwen2.5 系列重磅发布,成为开源语言模型领域的又一里程碑。作为一款全新的通用语言模型,Qwen2.5 在支持自然语言处理的基础上,还在编程、数学等领域进行了专项优化。Qwen2.5 模型支持长文本生成,最高可达 128K tokens,并能处理多达 29 种语言的复杂任务,在跨语言文本处理、角色扮演、数据结构生成等场景中表现出色。无论是生成结构化输出(如 JSON),还是应对多样化的系统提示,Qwen2.5 都具备强大的适应性,为用户带来全方位的智能体验。
来源:传神社区
01 Qwen2.5模型家族:多领域覆盖,性能卓越
Qwen2.5 是一系列先进的开源语言模型,覆盖了多个参数规模,从 0.5B 到 72B !这个系列不仅包含通用语言模型,还特别针对编程(Qwen2.5-Coder)和数学(Qwen2.5-Math)领域进行了优化。无论您是在进行自然语言处理、代码编写,还是复杂的数学推理任务,Qwen2.5 都能提供强大的支持。
以下是主要模型规模:
-
Qwen2.5:0.5B、1.5B、3B、7B、14B、32B、72B
-
Qwen2.5-Coder:1.5B、7B、32B
-
Qwen2.5-Math:1.5B、7B、72B
除了3B和72B的版本外,Qwen2.5所有的开源模型都采用了 Apache 2.0 许可证。您可以在相应的模型仓库中找到许可证文件。此外,本次通义千问团队还开源了性能不输于GPT-4o的 Qwen2-VL-72B。
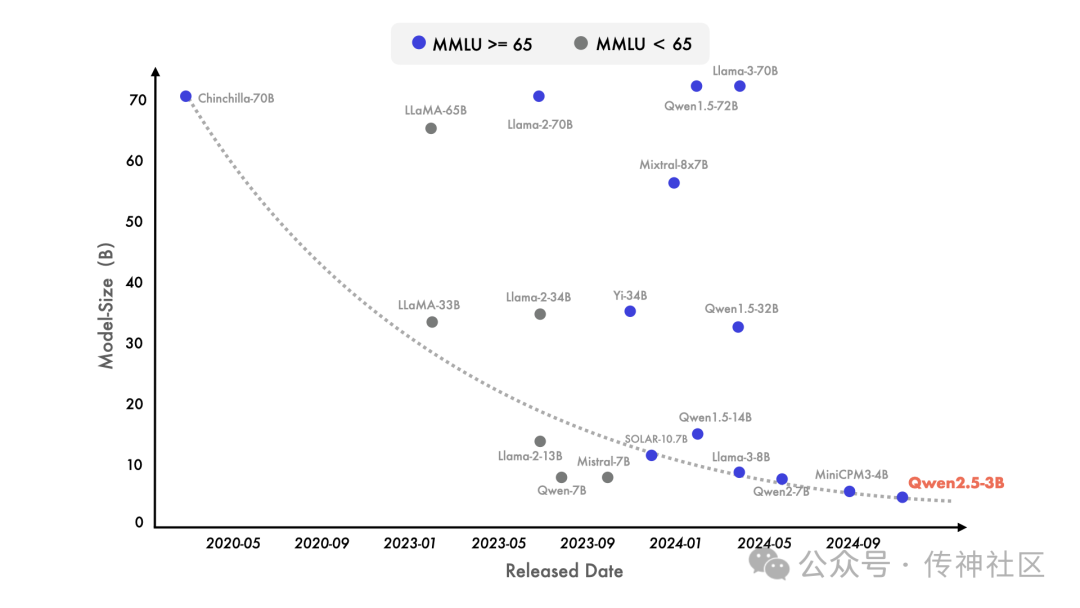
02 模型亮点:更大、更强、更灵活!
-
更大的训练数据集:Qwen2.5语言模型在最新的超大规模数据集上进行了预训练,该数据集包含多达 18T tokens。与前代Qwen2相比,Qwen2.5 在知识广度与深度上取得了显著进步,特别是在 通用知识测试(MMLU:85+)、编程能力测试(HumanEval:85+) 和 数学能力测试(MATH:80+) 方面表现尤为突出。
-
更强的指令遵循能力:新模型在指令执行、长文本生成(超过 8K tokens)、理解结构化数据(如表格)以及生成结构化输出(特别是 JSON)方面表现大幅提升。Qwen2.5 还更加适应不同的系统提示(system prompts),从而增强了角色扮演和聊天机器人的条件设置功能。
-
强大的长文本支持:Qwen2.5 继承了Qwen2的强大长文本生成能力,支持最高 128K tokens 的输入,能生成最多 8K tokens 的内容,非常适合需要处理大量文本的任务。
-
多语言支持:Qwen2.5 支持包括中文、英文、法文、西班牙文、葡萄牙文、德文、意大利文、俄文、日文、韩文、越南文、泰文、阿拉伯文等 29 种以上语言,真正实现全球化语言处理能力。
-
专业领域的专家语言模型:在编程领域,Qwen2.5-Coder 经过 5.5T 编程数据的训练,即使较小的模型也能在编程评估测试中表现出媲美大型模型的能力。对于数学领域,Qwen2.5-Math 支持中文和英文,整合了 CoT(Chain of Thought)、PoT(Program of Thought) 和 TIR(Tool-Integrated Reasoning) 等多种推理方法,显著提升了推理能力。
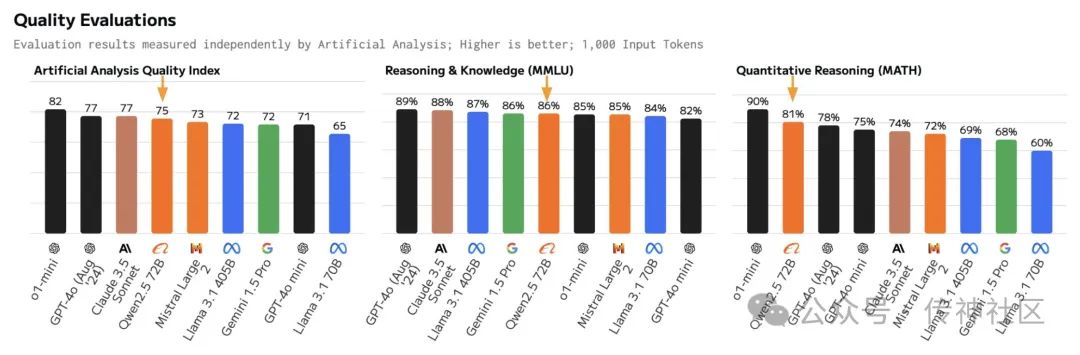
03 性能提升:更多知识、更强指令执行
为了全面展示 Qwen2.5 的强大能力,Qwen团队选择了最大的开源模型 Qwen2.5-72B,这是一个拥有 720 亿参数的稠密 decoder-only 语言模型。Qwen团队将其与当前领先的开源模型,如 Llama-3.1-70B 和 Mistral-Large-V2 进行了多项基准测试。通过这些测试,Qwen团队展示了经过指令调优的版本在不同任务中的综合表现,全面评估了模型的能力以及用户对生成内容的偏好。
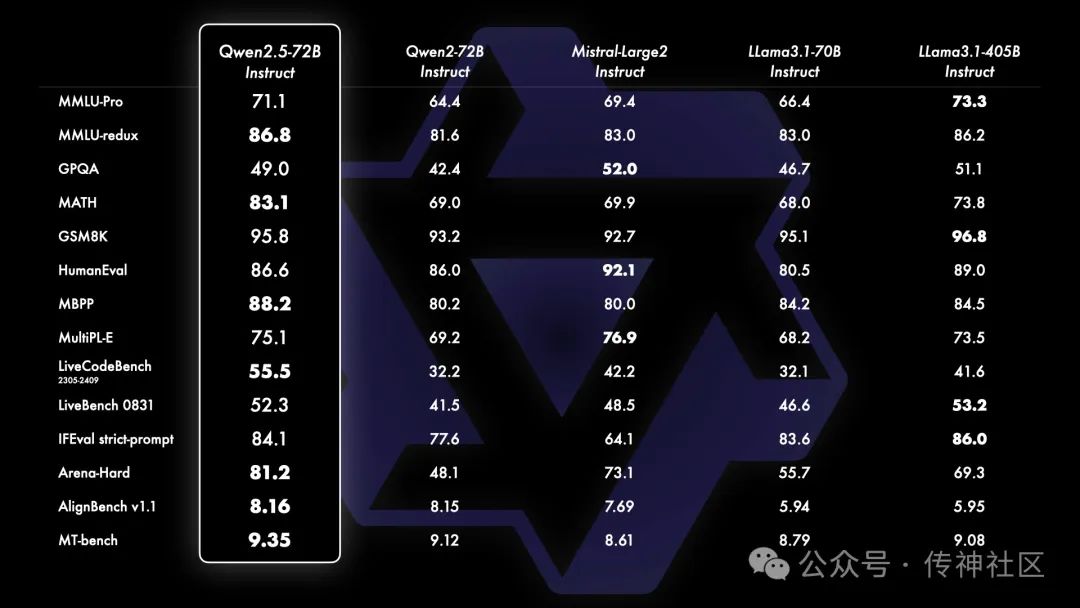
Qwen2.5-72B 性能表现
除了指令调优版本外,还发现,Qwen2.5-72B 的基础模型在多个任务中达到了顶级表现。即使与参数规模更大的模型(如 Llama-3-405B)相比,Qwen2.5-72B 的性能依然不落下风,证明了其强大的通用处理能力。
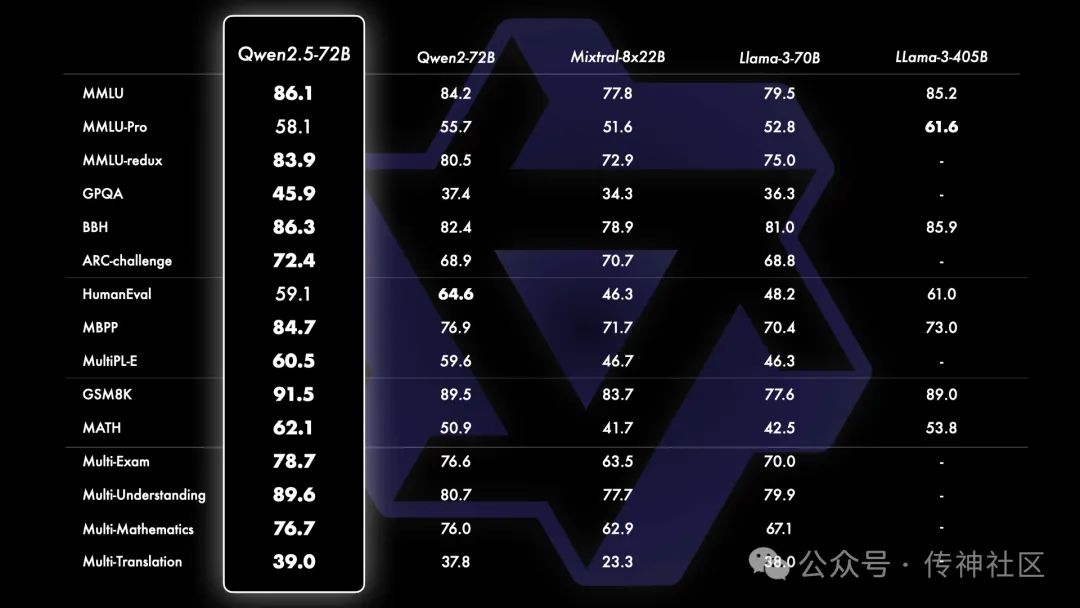
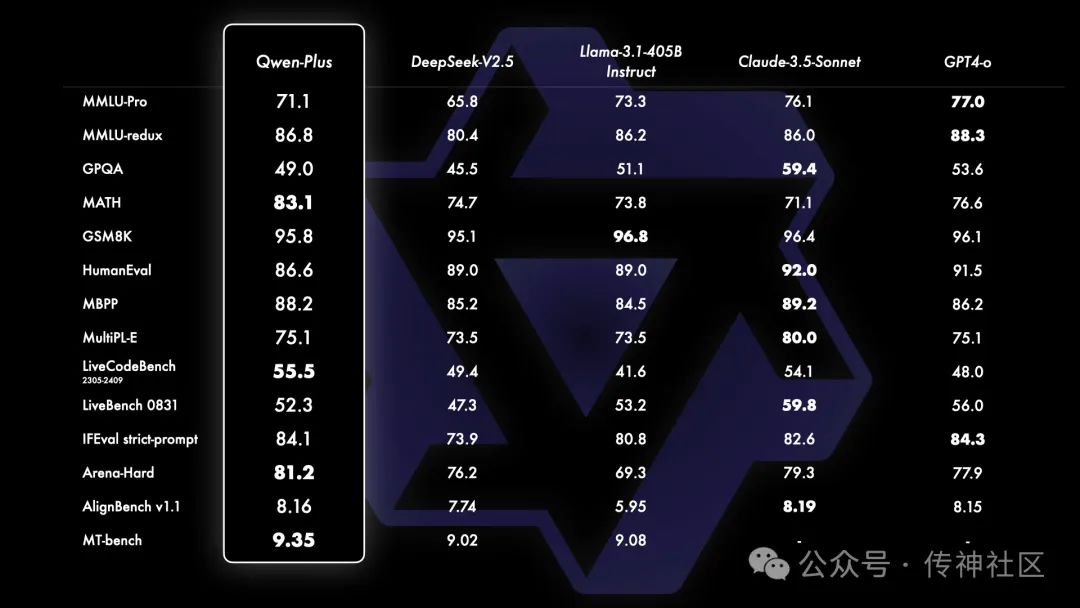
Qwen-Plus模型性能
Qwen团队还将基于 API 的模型 Qwen-Plus 与其他领先的专有和开源模型进行了比较,包括 GPT4-o、Claude-3.5-Sonnet、Llama-3.1-405B 和 DeepSeek-V2.5。结果显示,Qwen-Plus 在多个任务上表现出极具竞争力的实力,尤其是显著超越了 DeepSeek-V2.5,并在与 Llama-3.1-405B 的对比中展现了强大的竞争力。虽然在某些方面仍然稍逊于 GPT4-o 和 Claude-3.5-Sonnet,但这次基准测试进一步验证了 Qwen-Plus 的卓越性能,并为未来的改进提供了方向。
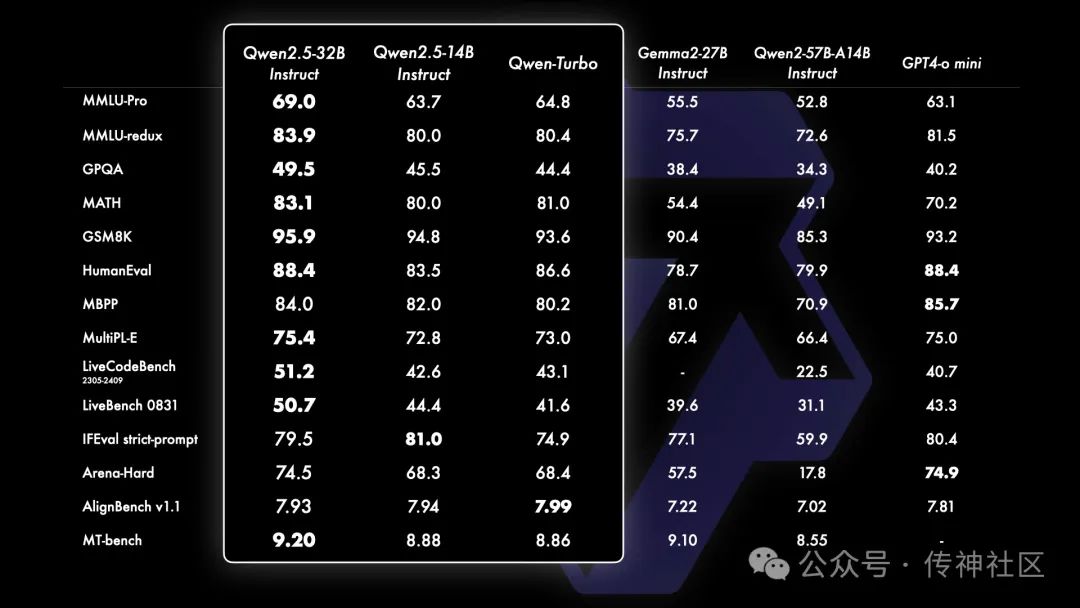
Qwen2.5-14B 和 Qwen2.5-32B 的更新
一个重要的更新是重新引入了Qwen2.5-14B 和 Qwen2.5-32B 模型,分别拥有 140 亿和 320 亿参数。这些模型在多个任务中表现出色,甚至超越了同等规模或更大规模的基线模型,如 Phi-3.5-MoE-Instruct 和 Gemma2-27B-IT。它们在性能与模型大小之间实现了理想平衡,不仅匹敌更大模型,甚至在部分任务上表现更优。此外,Qwen2.5-Turbo 基于 API 提供的模型,具有卓越的性能和高性价比,能够为用户提供快速响应的服务。
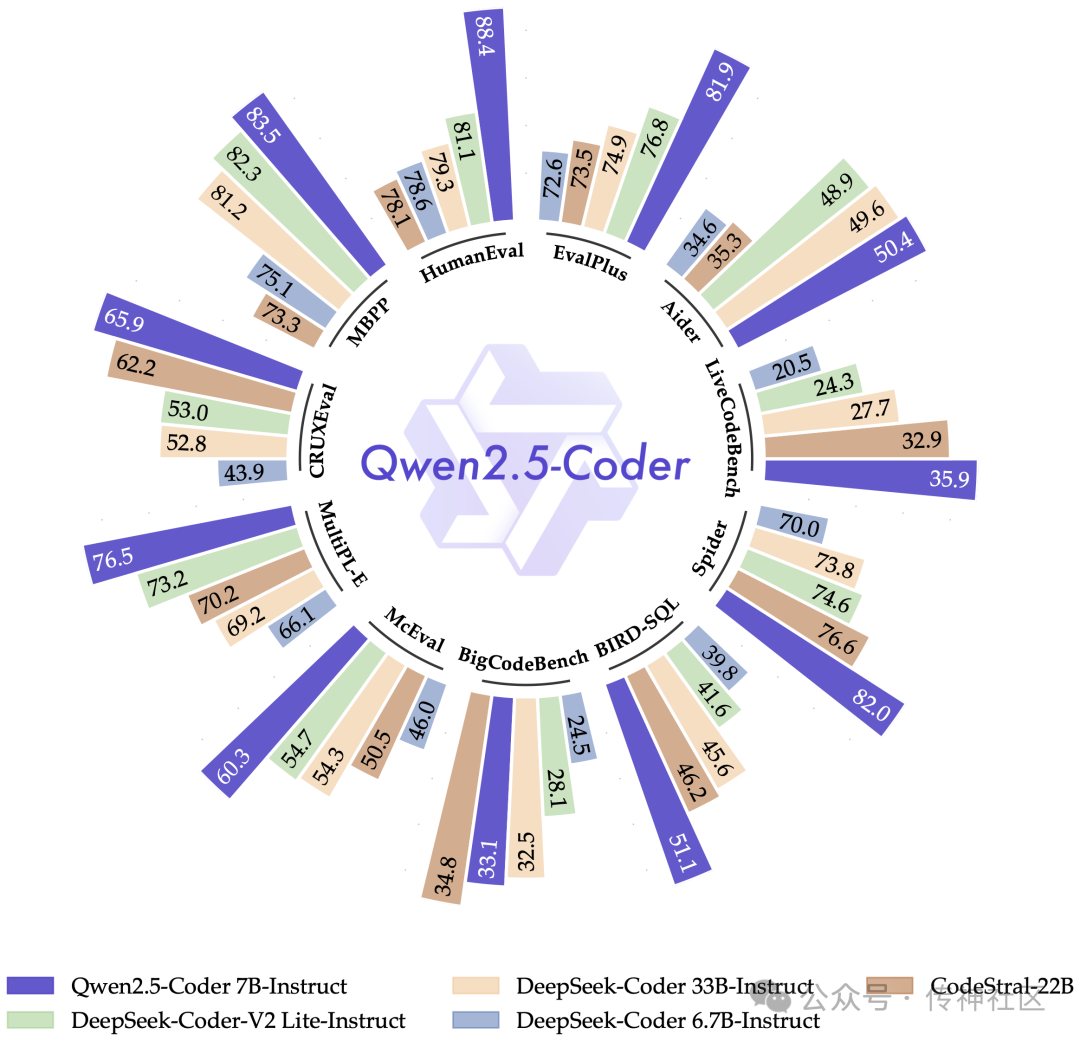
04 专为编程与数学优化的模型
-
Qwen2.5-Coder 是专门为编程任务设计的,它经过 5.5T 编程相关数据的训练,即使是小规模模型(如 7B)也能在编码评估基准中超越许多大型模型,成为您理想的编程助手,无论是调试代码、解答编程问题,还是提供代码建议,它都能应对自如。
-
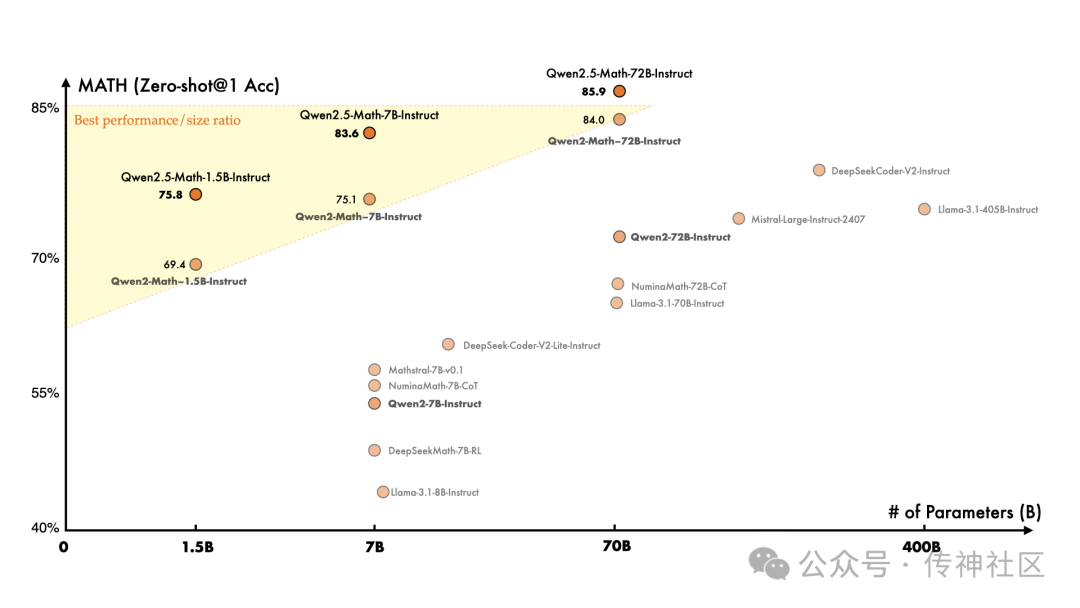
Qwen2.5-Math 则专注于数学领域的复杂推理,支持中文和英文两种语言,并整合了多种推理方法,如 Chain of Thought(CoT)、Program of Thought(PoT) 和 Tool-Integrated Reasoning(TIR),能轻松应对复杂的数学问题。Qwen2.5-Math-72B-Instruct 的整体性能超越了 Qwen2-Math-72B-Instruct 和 GPT4-o,甚至是非常小的专业模型如 Qwen2.5-Math-1.5B-Instruct 也能在与大型语言模型的竞争中取得高度竞争力的表现。
04 模型下载
传神社区:
https://opencsg.com/models/Qwen/Qwen2.5-7B-Instruct
huggingface:
https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https://github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区


















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









